
告别拼图,秒级重建:谷歌D4RT让AI透视「四维世界」


想象一下——
你拍摄了一段孩子在公园奔跑的视频,却无法在回放时自由转换视角,无法预测他下一秒会跑到哪里,更无法将背景中杂乱的行人“一键清除”。
这正是谷歌DeepMind最新发布的D4RT(Dynamic 4D Reconstruction and Tracking)所要击穿的核心壁垒。
它不再满足于让AI“看图片”,而是教它“看懂时间”,真正理解物体在空间中的运动轨迹、相机的移动路径,以及二者之间错综复杂的关系。
当AI遇上“动态世界”,传统方法为何失灵?
从“拼图游戏”到“全息记忆”——传统4D重建的三大死穴
当前的动态场景重建技术,就像是用多盒拼图拼一幅流动的油画——每一帧都要重新拼,且永远拼不完。具体来说面临三大难题:
流程冗长,误差累积:
传统方法需要串联多个模型——光流估计、相机姿态解算……每一步都可能出错,一旦光流“飘了”,后续全盘皆崩。
假设静止,动态抓瞎:
大多数3D重建算法基于“世界是静止的”这一强假设。一旦画面中出现奔跑的狗、飘落的叶或荡漾的水波,输出就会变成一团“幽灵重影”。
算力黑洞,无法实时:
高质量的4D重建曾是好莱坞渲染农场的专属,一段1分钟的视频可能需要数小时甚至整夜的计算,根本无法应用于机器人、AR等实时场景。

D4RT如何重新定义“视觉问答”
“哪里不会点哪里”——D4RT的时空搜索引擎
谷歌DeepMind——D4RT,能够从普通 2D 视频中重建 3D 场景和物体随时间的运动轨迹。D4RT 简化的架构和新颖的查询机制使其处于 4D 重建的前沿,效率比以前的方法高出 300 倍——速度足以满足机器人、增强现实等领域的实时应用需求。
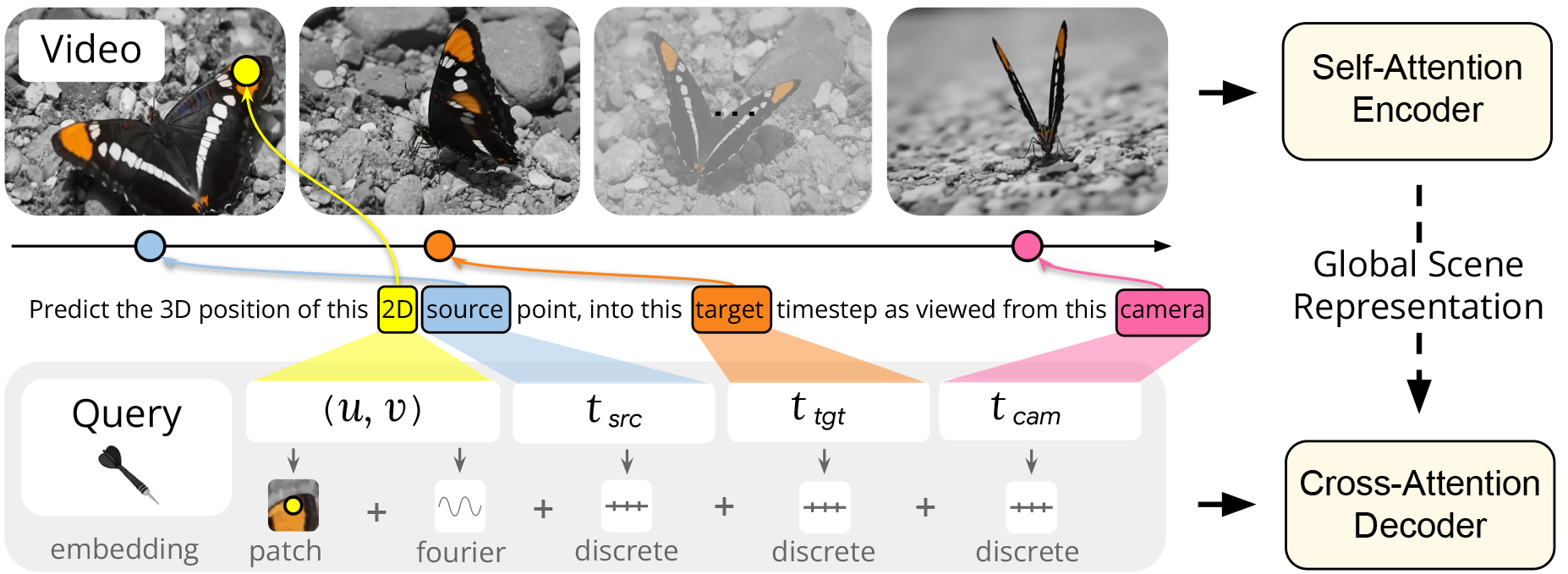
D4RT 采用统一的编码器-解码器 Transformer 架构,编码器首先将输入视频处理成场景几何形状和运动的压缩表示。凭借灵活的公式,该模型现在可以解决各种各样的 4D 任务,包括:
- 点跟踪:D4RT 通过查询像素在不同时间步长中的位置,可以预测其 3D 轨迹。重要的是,即使物体在视频的其他帧中不可见,模型也能做出预测。
- 点云重建:通过冻结时间和相机视角,D4RT 可以直接生成场景的完整 3D 结构,无需额外的步骤,例如单独的相机估计或逐个视频的迭代优化。
- 相机姿态估计:通过生成和对齐来自不同视角的同一时刻的 3D 快照,D4RT 可以轻松恢复相机的轨迹。
你可以向模型提出这样的问题:
“在视频第5帧画面中(x=320, y=240)的那个像素,在第10秒钟时,如果从某个虚拟相机视角看,它在真实世界中的3D坐标是多少?”
统一架构,告别“模型动物园”
从“多头怪兽”到“一体引擎”——D4RT的架构哲学
当前4D重建方案主要分为两派:
拼装派:如MegaSaM,串联多个专用模型,误差传递风险高。
多头派:如VGGT,虽为单一模型,但需为不同任务配备独立解码头,结构臃肿。
D4RT的突破在于极简统一:
一个编码器(Encoder) 将整段视频压缩为“全局场景记忆”;
一个解码器(Decoder) 通过同一套查询接口,回答深度、位姿、轨迹等所有问题。
这种设计不仅减少误差累积,更充分利用GPU/TPU的并行能力,实现百倍速度提升。
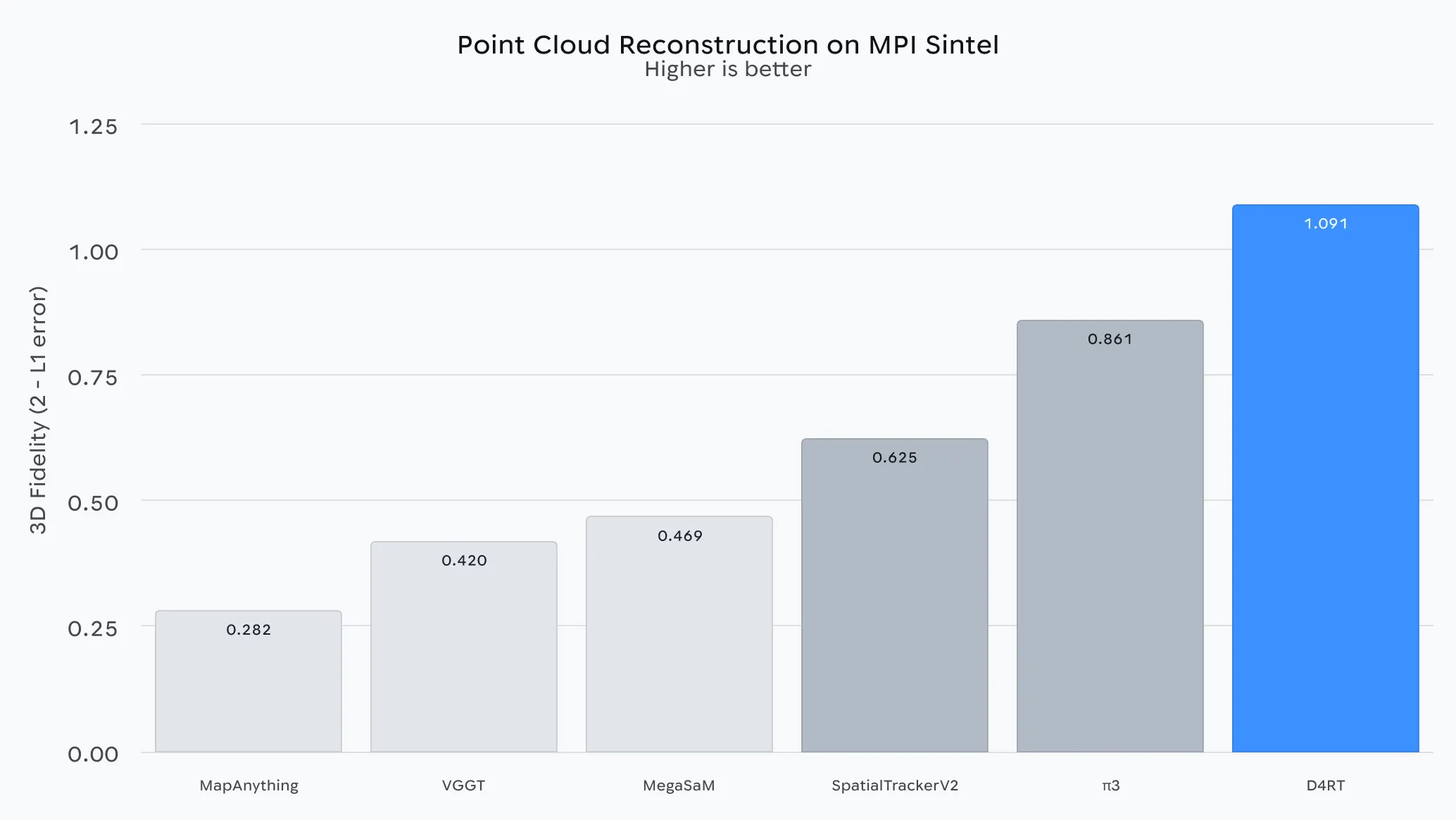
在包含快速运动模糊和非刚性形变的复杂合成场景的MPI Sintel基准测试中,D4RT展现出优于近期优秀基线模型的保真度。这凸显了该模型即使在物体或摄像机快速移动的情况下也能精确重建几何形状的能力。
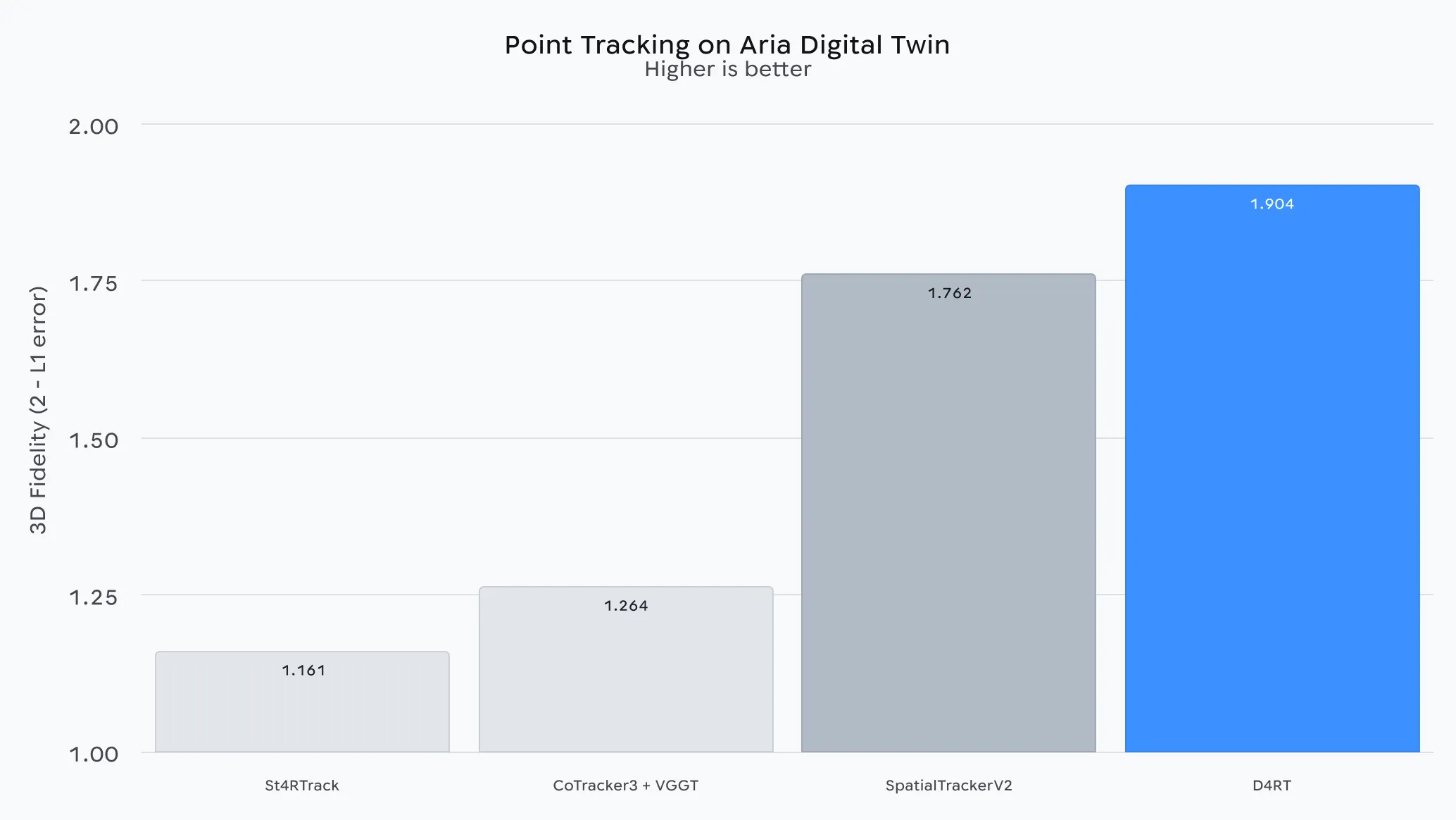
利用来自 Aria 数字孪生数据集的智能眼镜拍摄的视频,D4RT 在 3D 点跟踪方面实现了顶级性能。这验证了该模型在真实的家庭环境中能够稳健地处理复杂的自我运动和遮挡情况。
快300倍,不只是数字游戏
5秒 vs. 数小时——D4RT的速度革命真实可感
谷歌宣称D4RT比现有SOTA(最先进技术)快18~300倍,这并非营销话术,而是在具体任务上的实测突破:
- 处理效率:1分钟视频,D4RT仅需约5秒即可完成全像素追踪与重建;同类技术如DELTA可能需要数分钟,传统流水线甚至需小时级计算。
- 追踪密度:在24 FPS视频中,前代模型SpatialTrackerV2最多同时追踪84条轨迹;D4RT可轻松处理1570条,实现真正的“全像素级”感知。
- 训练规模:模型基于ViT-g架构,拥有10亿参数,在64个TPU上训练两天而成,属于大厂级基础设施的产物,但推理阶段极度轻量化。
未来发展分析:通向AGI的“时空基石”
超越识别,走向洞察——D4RT的长期想象
D4RT不仅是一项技术突破,更是AI感知范式的转变:
- 走向“世界模型”:通过分离相机运动、物体运动与静态背景,D4RT为构建具有物理常识的AI“世界模型”迈出关键一步,这是实现通用人工智能(AGI)的重要基石。
- 端侧部署潜力:虽然当前训练需大规模算力,但其高效的查询机制极适合优化后部署至移动芯片,赋能边缘设备实时4D感知。
- 跨行业融合:从医疗(手术轨迹分析)、体育(运动员动作重建)到城市规划(车流模拟),D4RT的时空理解能力将逐渐渗透至各行各业。
真正的突破,在于AI终于将时间变成可调取的参数。D4RT改写了机器感知的底层逻辑:从“逐帧猜测”走向“全局洞察”,从“静态拼图”迈向“动态全景”。
当AI学会在时空中自由问答,我们离那个能真正理解流动世界的智能,又近了一步。
