
老黄的“核弹”又爆了:Sora还在做梦,英伟达已经动手“造世界”了
黄仁勋没有吹牛,Sora生成的视频再美,终究只是“动画片”。为什么?因为你伸手去拿视频里的杯子,手会穿过去——它没有物理碰撞,没有重量,不懂真实世界的规则。
这就是目前生成式AI最大的痛点:只会“看”和“说”,不会“做”。
但就在刚刚,英伟达联合斯坦福扔出了一颗重磅炸弹——3D-Generalist(3D通才模型)。它不生成视频,而是直接生成一个符合物理定律、可交互的3D世界。如果说Sora是AI在做梦,那这个新模型就是AI醒来后,开始动手搬砖了。硅谷的下半场,真的变天了。

外媒评价这是“物理AI的ChatGPT时刻”,黄仁勋再次定义了赛道。图片来源: 新闻报道
01 AI不懂“物理”,只是概率的复读机
不管是Midjourney还是Sora,它们本质上都是“观察者”。它们看过一亿张椅子的照片,知道椅子长什么样,但不知道椅子有多重、能不能坐人、材质是木头还是塑料。

OpenAI发布的Sora视频虽美,但它只是“视觉欺骗”,缺乏物理交互属性。图片来源:OpenAI Sora演示视频
对于我们要发展的机器人(具身智能)来说,这种AI是没用的。机器人需要知道:“我撞到这堵墙,墙会不会倒?”或者“这个杯子滑不滑?”。目前的视频生成模型无法提供这些物理属性(Physical Properties),这就导致机器人只能在现实中笨拙地试错,成本极高且效率极低。
02 不是画图,而是“全能工头”
英伟达这次发布的3D-Generalist,核心是一个全新的概念:VLA(视觉-语言-动作模型)。

英伟达与斯坦福联合发表的重磅论文:3D通才模型。图片来源:论文《3D-GENERALIST: Vision-Language-Action Models for Crafting 3D Worlds》
请注意“动作(Action)”这个词。当你输入一句“给我一个温馨的现代客厅”,它不是给你一张客厅的照片,而是像一个全能工头一样,一步步把客厅造出来:
- 全景生成:先用扩散模型生成一张360°的蓝图。
- 逆向工程:通过HorizonNet模型分析哪里是墙、哪里是地。
- 精细装修:调用GPT-4o级别的模型分析门窗材质(是木门还是推拉门?)。
- 代码构建:最后,它生成的不是像素,而是代码!直接产出可编辑、可互动的3D环境资产。

3D-Generalist生成的各种高精度3D环境(健身房、酒吧、大堂),细节惊人且具备物理结构。图片来源:论文《3D-GENERALIST: Vision-Language-Action Models for Crafting 3D Worlds》
独到见解:这就像是从“美图秀秀”进化到了“CAD建筑师”。前者是为了好看,后者是为了能用。英伟达这一步,直接把内容生成的维度升了一级。
03 卖铲子给“造物主”
老黄的商业逻辑永远这么性感。他不仅仅是想卖显卡,他是想垄断“机器人的训练场”。
这个模型是英伟达Omniverse生态的核心拼图。它的商业闭环是这样的:
- 低成本造界:利用3D-Generalist快速生成数亿个不同的虚拟3D房间。
- 合成数据(Synthetic Data):在这些虚拟房间里训练机器人(比如Tesla Optimus或Project GR00T)。
- Sim-to-Real:机器人在虚拟世界里摔倒一万次学会走路,然后下载到现实世界的机器人脑子里,一次成功。
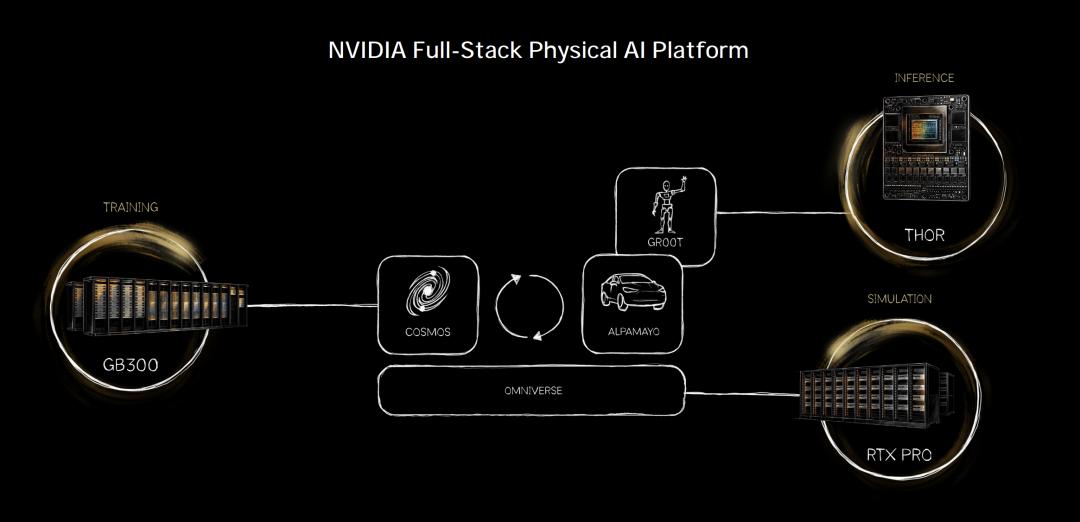
英伟达的全栈物理AI平台:从芯片(Thor)到仿真(Omniverse)再到机器人(Groot)的完美闭环。图片来源:英伟达官方演示PPT
英伟达卖的不是模型,是“物理AI的子宫”。以后谁想做机器人,都得用英伟达的平台来“生”数据。
04 合成数据吊打人工标注
根据英伟达和斯坦福的联合论文,这一模型展现了惊人的数据统治力:
指标维度 | 传统人工合成数据 | 3D-Generalist 生成数据 | 结论 |
数据规模能力 | 极受限(需人工建模) | 无限(AI自动化生成) | 效率提升数个数量级 |
模型训练效果 | 基准水平 | 超越人工精细标注的数据 | 机器生成的质量更高 |
自我纠错能力 | 无 | 涌现(Emergent) | 微调后具备自我优化能力 |
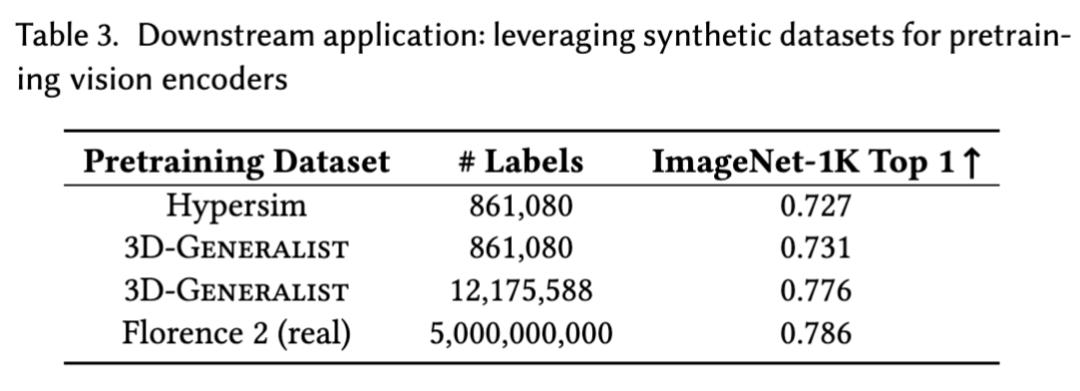
实验数据显示,3D-Generalist生成的训练数据(ImageNet Top 1准确率0.776)效果显著优于传统方法,逼近真实数据。图片来源:论文《3D-GENERALIST: Vision-Language-Action Models for Crafting 3D Worlds》
特别值得注意的是,论文指出,使用该模型生成的合成数据训练出的视觉基础模型,其效果“接近使用规模大几个数量级的真实数据所能达到的效果”。这意味着,我们可能不再需要那么多昂贵的真实世界数据了。
05 它不只是“看客”
这里必须拉踩一下Sora和Runway。
- Sora (OpenAI):生成的是像素(Pixel)。它是2D的,你无法转动视角看物体背面,也无法测量距离。它主要用于娱乐和影视。
- 3D-Generalist (Nvidia):生成的是资产(Asset)和布局(Layout)。它是3D的,你可以把里面的椅子拖走,换个位置,光影会跟着变。它主要用于工业、游戏开发和机器人训练。
差异化核心: Sora是给人看的,3D-Generalist是给机器用的。
06 从虚拟渗透现实
英伟达的打法非常清晰:“农村包围城市”(从虚拟包围现实)。
- 学术界首发:通过与斯坦福大学顶尖学者合作,先在 3DV 2026 等顶级会议上确立技术标准。
- 开发者工具化:迅速将模型集成进Isaac Sim和Omniverse平台,让开发者“开箱即用”。
- 解决长尾问题:利用该模型生成极端场景(比如着火的厨房、满是玻璃渣的地面),解决机器人训练中遇不到的“边缘案例”。

该技术将在2026年3月于温哥华举办的3DV国际会议上正式亮相。图片来源:3DV 2026会议官网
07 所有移动之物,终将自主
黄仁勋在SIGGRAPH上说的那句“Everything that moves will be autonomous”,正在变成现实。
未来3-5年,我们预测:
- 游戏开发自动化:游戏美工不再需要手搓每一把椅子,输入一句话,整个关卡自动生成。
- 机器人爆发:因为训练数据的成本被这个模型打下来了,家用机器人的落地速度将加快至少2倍。
- 物理世界数字化:我们将拥有一个和地球一模一样的“数字孪生”世界,所有的测试都在里面完成后,再映射回现实。
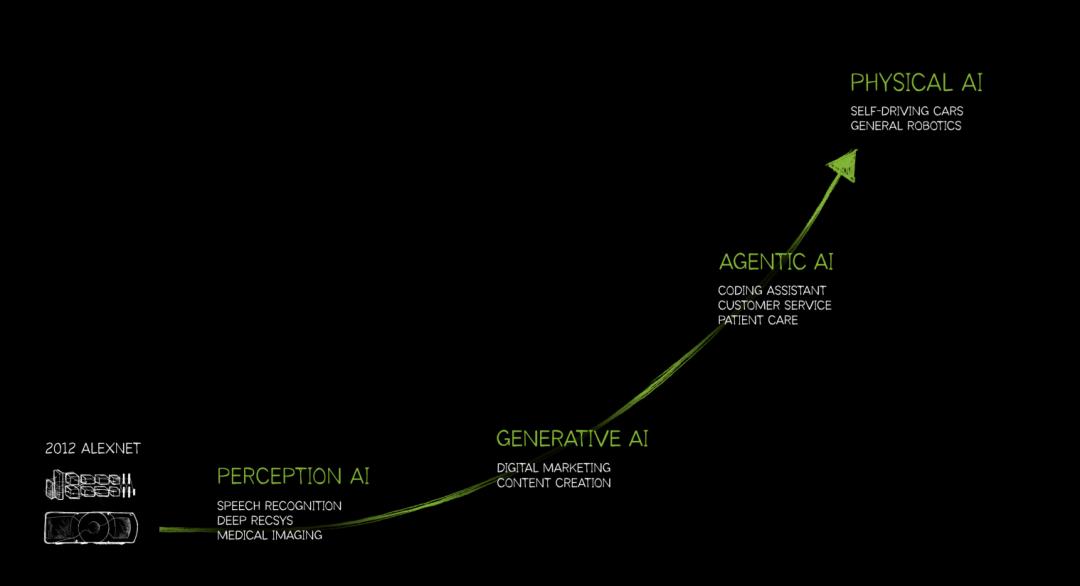
AI进化的终局:从感知AI(Perception)到生成式AI(Generative),最终迈向物理AI(Physical AI)。图片来源:行业分析图表
别只盯着大语言模型(LLM)了,物理AI(Physical AI)才是下一个万亿赛道的入场券。当AI不仅能写诗,还能理解“重力”和“摩擦力”时,它才真正具备了改变实体经济的能力。
