
阿里Qwen3-Max-Thinking深度复盘:GPT-5.2的“王座”还能坐多久?
1月26日深夜那场发布之后,经过这两天的沉浸式体验,大模型圈的气氛明显变了。
一直以来,我们都在吐槽AI像个“鹦鹉学舌”的高手——嘴皮子利索,但真遇到复杂逻辑,经常一本正经地胡说八道。为什么?因为它只会线性预测下一个字,不懂得“停下来想一想”。这也是为什么之前的国产模型虽然跑分高,但真到了写复杂代码或者解决数学难题时,总让人觉得差点意思。
但阿里这次上线的Qwen3-Max-Thinking,似乎捅破了这层窗户纸。它不只是回答更快,而是学会了“慢思考”,性能直接对标了目前公认的霸主GPT-5.2 和 Gemini 3 Pro。这次,咱们可能真的不仅仅是“追赶”了。
01 为什么以前的AI总是“脑子不转弯”?
咱们都知道,传统的LLM(大语言模型)有一个致命弱点:线性思维。你问它一个问题,它就像是在走钢丝,只能一步步往前蒙,一旦中间某一步推导错了,后面就全盘皆输,根本不知道回头检查。
这就导致了在写长代码、做复杂数学题时,AI经常出现“幻觉”。对于专业人士来说,这种模型只能当个辅助,真要干重活,还得人盯着改。行业里缺的不是能聊天的机器人,而是能像人一样,遇到难题知道“打草稿”、“反思错误”的智能体。
02 实测“重推理模式”,代码一次过
这次Qwen3-Max-Thinking的核心大招,就是引入了Heavy Mode(重推理模式)。
简单说,就是让AI在回答之前,先在后台进行多轮“自我辩论”。它不再是脱口而出,而是通过一种叫“Test-time scaling”的技术,用算力换智力。就像咱们考试做压轴题,它会反复推演,发现死胡同就退回来重走。
实测案例1:技能五子棋
我们在实测中让它写一个带技能系统的五子棋网页。以前的模型可能给你一段还得自己修修补补的代码,但Qwen3直接甩出了1000多行代码,不仅逻辑通顺,连交互细节都处理得明明白白。
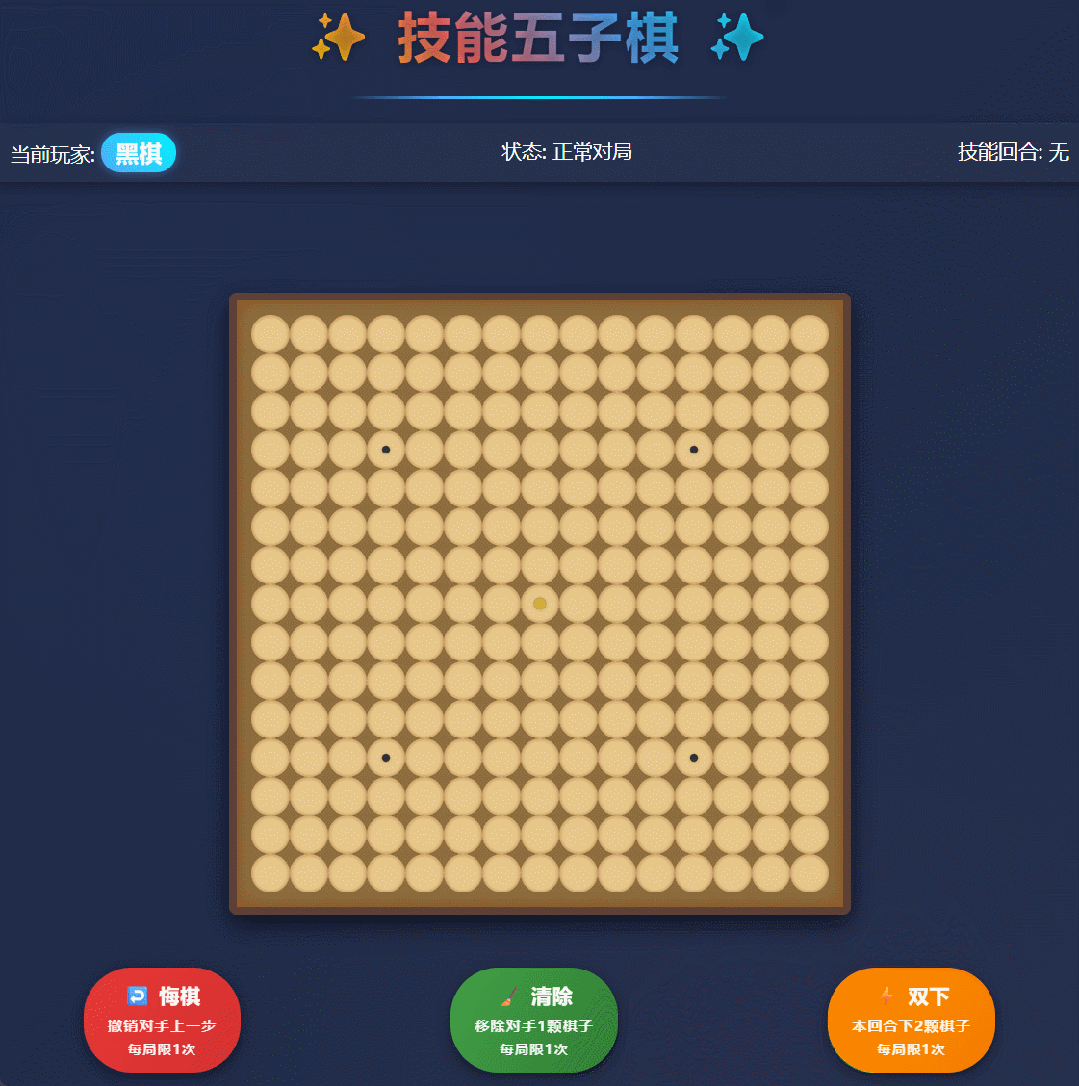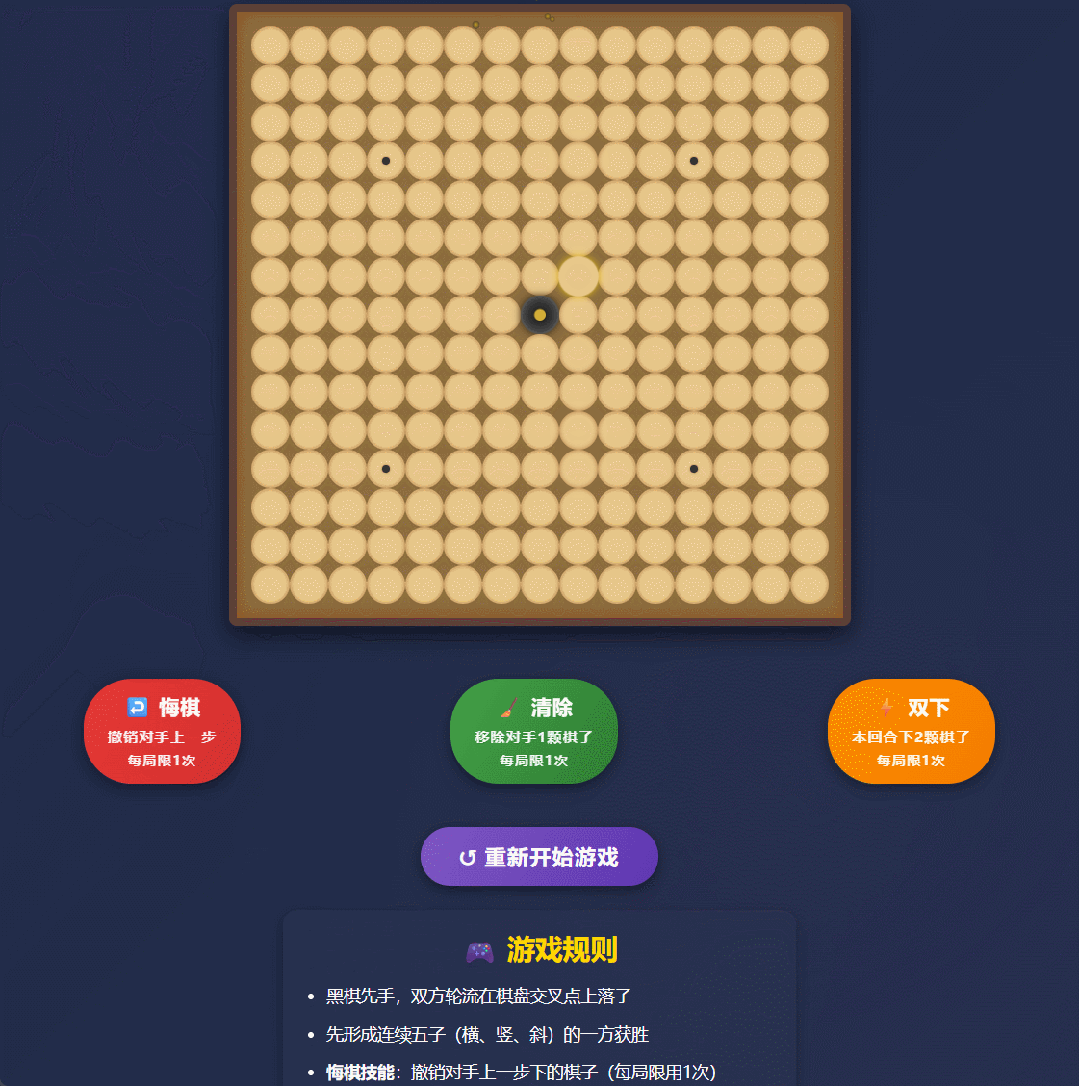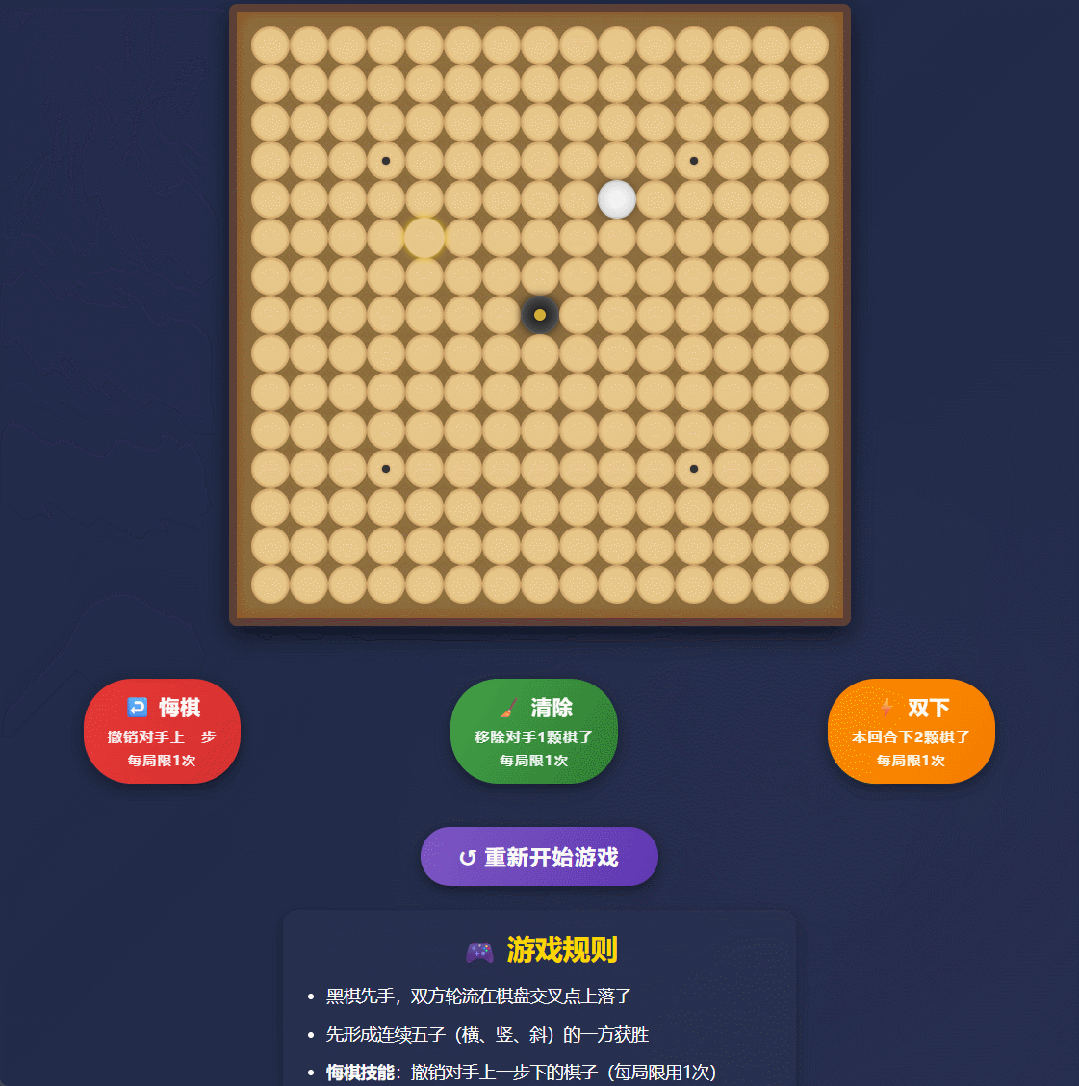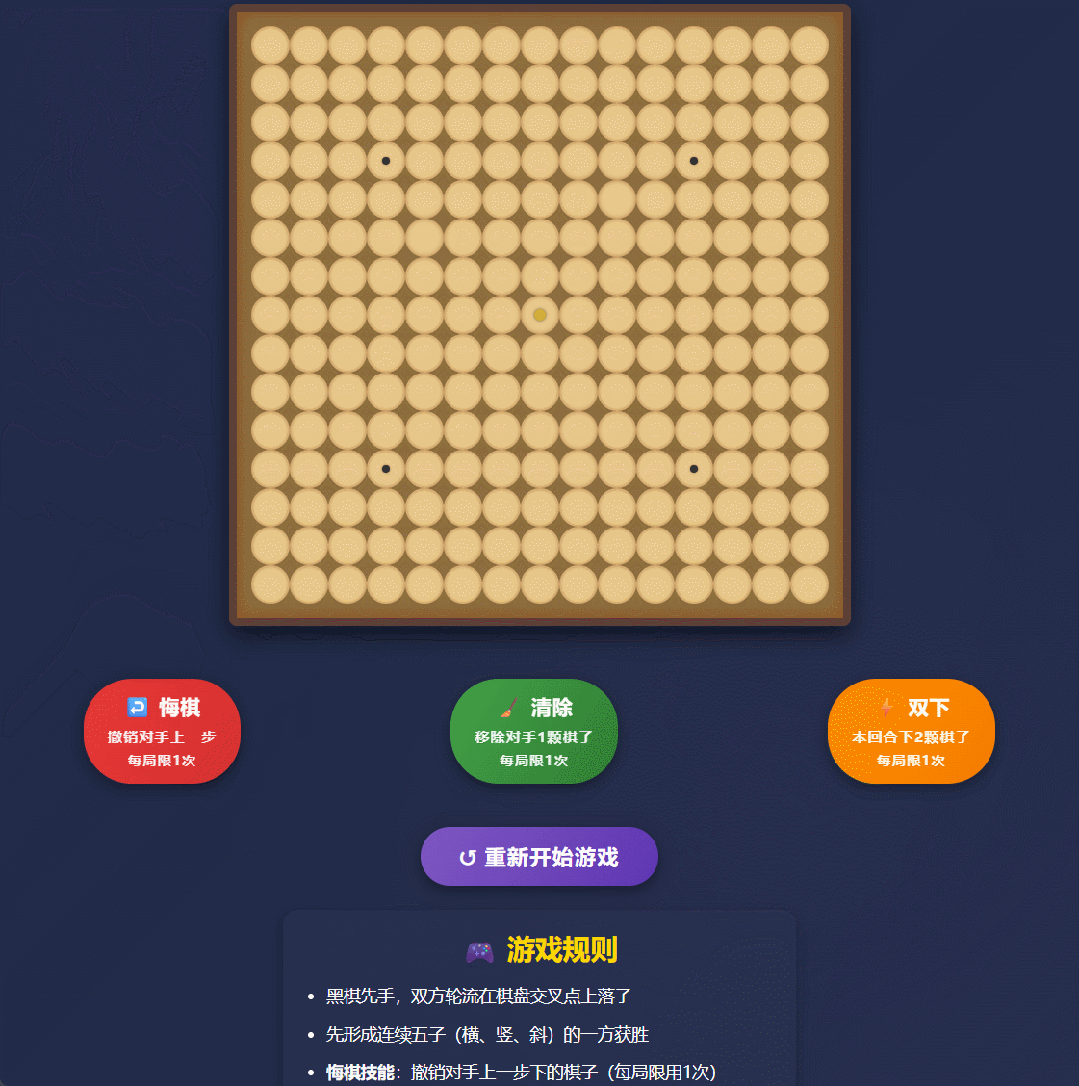
Qwen3-Max-Thinking生成的“技能五子棋”网页实测。 图片来源:Qwen3-Max-Thinking
实测案例2:跳一跳小游戏
为了增加难度,我们又让它用纯原生代码写一个《跳一跳》。这种游戏最考验物理判定的逻辑。结果它不仅写出来了,还顺手把蓄力动画和计分逻辑都做好了。这种“甚至不需要你改BUG”的体验,才是专业用户最馋的。
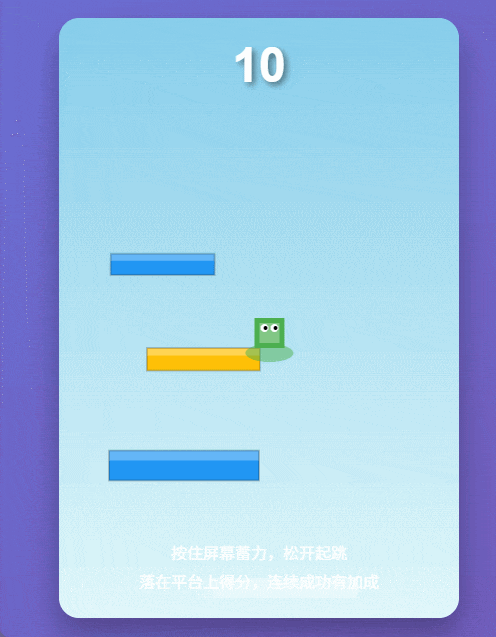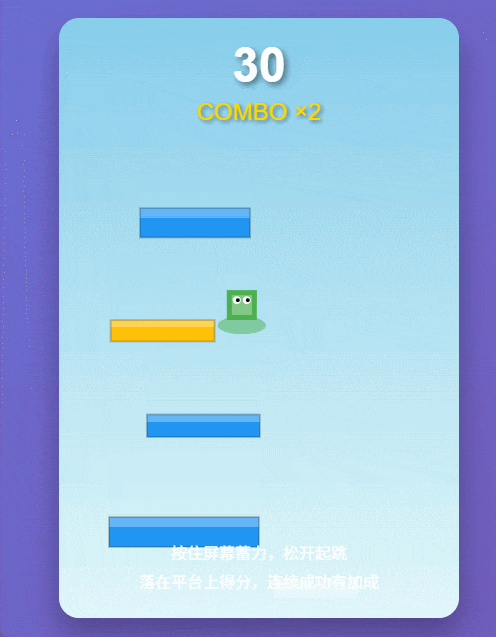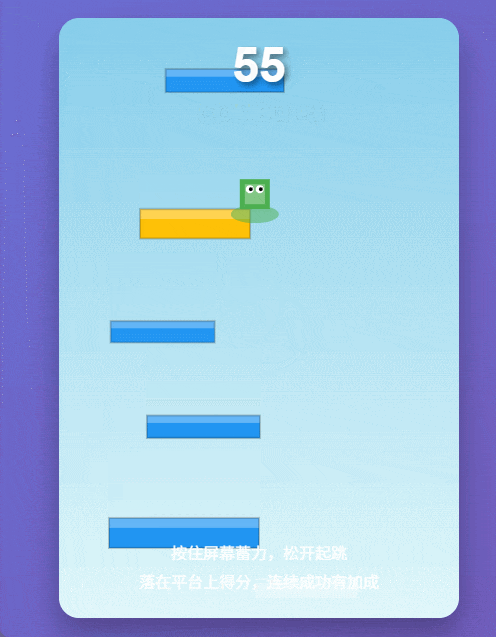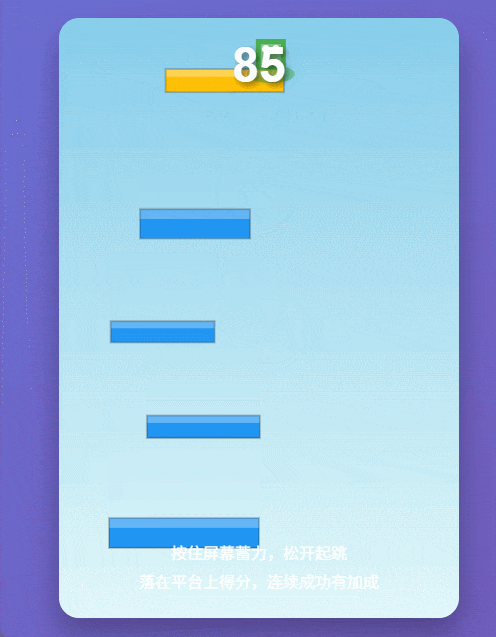
Qwen3-Max-Thinking生成的《跳一跳》游戏。 图片来源:Qwen3-Max-Thinking
03 左手开源生态,右手云端变现
阿里的商业逻辑非常清晰:MaaS(模型即服务)。
- 开源引流:通过在Hugging Face上疯狂刷榜(10亿次下载量不是盖的),让全球开发者都习惯用Qwen 的架构。
- 云端收割:你想用最强的Qwen3-Max-Thinking?不好意思,开源版没有,得来阿里云上调API。
- 算力捆绑:企业要部署Agent,要微调私有模型,最后都得跑在阿里的算力设施上。
04 硬刚国际顶流,数据不撒谎
既然是对标,咱们就得看数据。这不是“概念发布”,而是实打实的基准测试对比。根据官方最新公布的评估数据,开启了“思考模式”(with TTS)后的Qwen3-Max-Thinking在多个硬核维度上都实现了超越。
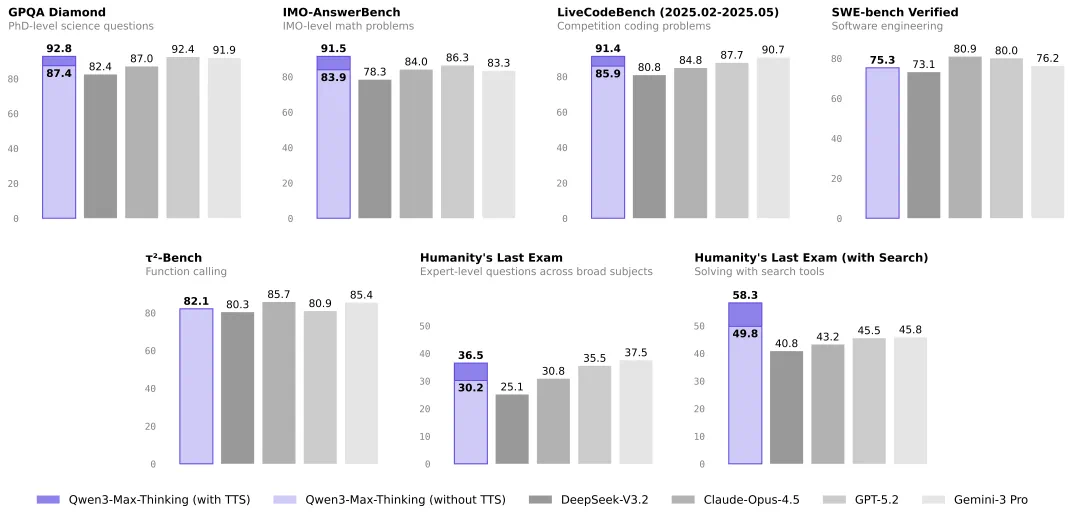
Qwen3-Max-Thinking (紫色柱状图) 在GPQA、IMO数学竞赛及代码测试中与GPT-5.2、Gemini 3 Pro的对比数据。图片来源:阿里千问技术报告
从上图可以看出几个关键指标的跃升:
- GPQA Diamond (博士级科学问题):开启思考模式后得分高达92.8,与GPT-5.2 (92.4) 处于同一水平线。
- LiveCodeBench (编程):得分91.4,超越了DeepSeek-V3.2 (80.8) 和Gemini 3 Pro(90.7),代码能力极其强悍。
- IMO-AnswerBench (数学奥赛):得分91.5,在数学推理上展现了压倒性优势。
05 它不只是想,它还会“用工具”
Qwen3跟竞品最大的区别在于Agent能力的内生化。
别的模型是用工具(比如搜索、代码解释器)是“外挂”的,有时候接不上有时候瞎调用。但Qwen3把工具调用刻进了“思考过程”里。它在推理的时候,会自己判断:“这步我算不准,我得调个计算器”或者“这个信息太旧,我得搜一下”。
这种自适应工具调用,让它从一个“懂很多的书呆子”,变成了一个“会干活的实习生”。
06 从Hugging Face包围企业级市场
阿里在市场打法上非常凶猛:
- 刷榜战术:在Hugging Face等开源社区保持高频更新,只要你是搞AI开发的,就绕不开Qwen。
- 降维打击:利用中国供应链的算力成本优势,把推理成本压到美国的几分之一。对于中小企业来说,GPT-5.2虽好,但Qwen3便宜又大碗,性能还差不多,选谁不言而喻。
- 全家桶策略:结合钉钉、阿里云,直接把模型塞进企业原有的工作流里,降低迁移成本。
07 2026,从聊天走向行动
未来的竞争焦点,将从“你拥有多大的模型”转移到“你的模型能解决多复杂的长链条任务”。Qwen3这种“思考+行动”的模式,大概率会成为2026年行业的新标配。对于我们普通人来说,也许以后真的只需要说一句:“帮我做个游戏”,剩下的,就真的只需要等待了。
