
DeepSeek-OCR2:像人一样“看懂”文件的AI,如何撬动千亿数据清洗市场?


当一份复杂的学术论文或财报被扫描进电脑,传统AI需要像复印机一样机械地逐行“复刻”,而DeepSeek-OCR2则像一位经验丰富的编辑,能先理解标题、正文、图表和脚注的逻辑关系,再进行“智能重排”与转录。
全球的AI实验室每天都在“喂养”大模型海量的文本数据,这些数据很多来自扫描的纸质文档或图片。一个长期被忽略的痛点在于:传统的OCR(文字识别)技术像个“盲打员”,它看得见字符,却读不懂段落。
比如,当遇到一份两栏排版的论文或一张财务报表时,传统模型会从左到右、逐行扫描,结果很可能把分属两栏的句子错误地拼接在一起,生成一堆需要人工花大力气清洗的“乱码”。
2026年1月27日,DeepSeek开源的 DeepSeek-OCR2模型,正是为了根治这一痛点而来。它的核心创新不是让模型“看得更清”,而是让它像人一样“看懂”文档的结构与逻辑。

01 商业模式:不直接收费的开源模型,如何创造百亿价值?
DeepSeek-OCR2延续了DeepSeek团队“论文、代码、模型全开源”的惯例。这种看似“用爱发电”的模式,实则瞄准了一个更庞大、更底层的市场:AI时代高质量训练数据的自动化生产与清洗。
数据,是驱动所有大模型的“石油”。但“原油”需要经过精炼才能使用。据行业估算,在大型AI项目中,数据清洗和标注的成本可占总预算的25%以上,且高度依赖人力。DeepSeek-OCR2扮演的,正是一个高效的“自动化炼油厂”角色。
它的直接商业价值体现在“降本增效”上。根据DeepSeek披露的内部数据,在将在线用户日志图像转换为文本的数据流水线中,新模型将结果的错误重复率从 6.25% 降到了 4.17%;在PDF文档处理场景中,重复率从 3.69% 降到了 2.88%。这意味着,AI公司用更低的成本、更少的人工校验,就能获得更干净的训练数据,从而直接提升最终大模型的质量。
更进一步,这项技术可以赋能整个数字化产业。从金融、法律机构的档案数字化,到学术研究的文献分析,再到跨境电商的商品信息提取,所有需要从复杂文档中精准抽取信息的场景,都是其潜在的市场。据华创证券分析,前代DeepSeek-OCR已展现出强大的处理能力,在20个A100显卡节点上,每日能处理超过3300万页数据。这种级别的吞吐能力,预示着一个规模可观的B端技术服务市场。
图片来源:https://github.com/deepseek-ai/DeepSeek-OCR-2
02 产品服务:从“复印机”到“智能编辑”
DeepSeek-OCR2提供的不仅是一个识别工具,更是一套文档理解的“认知框架”。其服务能力可以拆解为三个层次:
基础层:无与伦比的结构化理解能力
传统模型如“复印机”,采用“光栅扫描”顺序,死板地从左上角到右下角处理图像。而DeepSeek-OCR2引入了 “视觉因果流” 机制。它像人的目光一样,会根据语义逻辑跳跃:先“看”标题,再“读”正文,遇到表格则按行或列来理解。这使得它在处理学术论文、财务报表等复杂版面时的准确率和逻辑性大幅提升。
特性维度 | 传统OCR / VLM模型 | DeepSeek-OCR2 |
处理逻辑 | 固定扫描:像复印机,从左到右、从上到下 | 语义推理:像人类,根据内容逻辑动态调整顺序 |
核心技术 | 基于CLIP等编码器,将图像强行转为1D序列 | DeepEncoder V2:使用小型大语言模型(Qwen2-0.5B)作为编码核心,引入“因果流查询”机制 |
阅读顺序精度 (编辑距离,越低越好) | 前代模型为 0.085 | 提升至 0.057,逻辑性显著增强 |
综合性能 (OmniDocBench v1.5) | 前代模型得分未明确,作为基线 | 91.09%,较前代提升 3.73% |
数据生产效率 | 高错误重复率,增加清洗成本 | 用户日志重复率从6.25%→4.17%;PDF重复率从3.69%→2.88% |
中间层:极致的效率与成本控制
该模型在“看得懂”的同时,还做到了“算得省”。它用更少的“视觉令牌”承载了更多信息。在权威的OmniDocBench v1.5基准测试中,DeepSeek-OCR2仅用256-1120个视觉令牌就取得了91.09%的综合得分。相比之下,一些顶级闭源模型(如Gemini-3 Pro)在使用相似数量令牌时,在文档解析准确度上反而略逊一筹。这意味着用户可以用更低的算力成本,完成更高质量的任务。
应用层:开箱即用的多场景解决方案
模型开源即意味着极强的可塑性。企业可以将其直接集成到自己的数据流水线中,用于海量扫描文档的批量结构化;开发者可以基于其强大的编码器,微调出专注于医疗报告、法律卷宗、手写笔记等特定场景的专用模型。它为解决“如何让AI消化海量非结构化文档”这一普遍难题,提供了一个高性能的基础设施。
03 核心痛点:直击AI数据流水线
DeepSeek-OCR2的成功,在于它精准命中了当前AI工业化进程中三个日益尖锐的痛点:
- “结构化”缺失:信息爆炸时代,大量有价值的知识仍锁在PDF、图片等非结构化文档中。传统OCR只能提供“字符位置”,无法输出“语义段落”,导致下游的NLP模型难以进行深度分析和知识挖掘。
- “脏数据”成本:大模型训练遵循“垃圾进,垃圾出”法则。由低级OCR错误引入的噪音数据(如错乱的顺序、错误拼接),会严重污染训练集,轻则增加模型训练周期,重则导致模型产生事实性幻觉。清洗这些数据的成本巨大。
- “复杂版面”理解:现实世界的文档布局千变万化。从简单的两栏排版,到嵌套的表格、环绕的图表,再到数学公式和化学方程式,传统模型对此束手无策,成为自动化流程中必须依靠人工干预的“断点”。
04 差异化:为何是“范式转变”而不仅是“性能提升”?
DeepSeek-OCR2的领先,并非单纯的指标上涨,而是一次技术路径的“代际差异”。
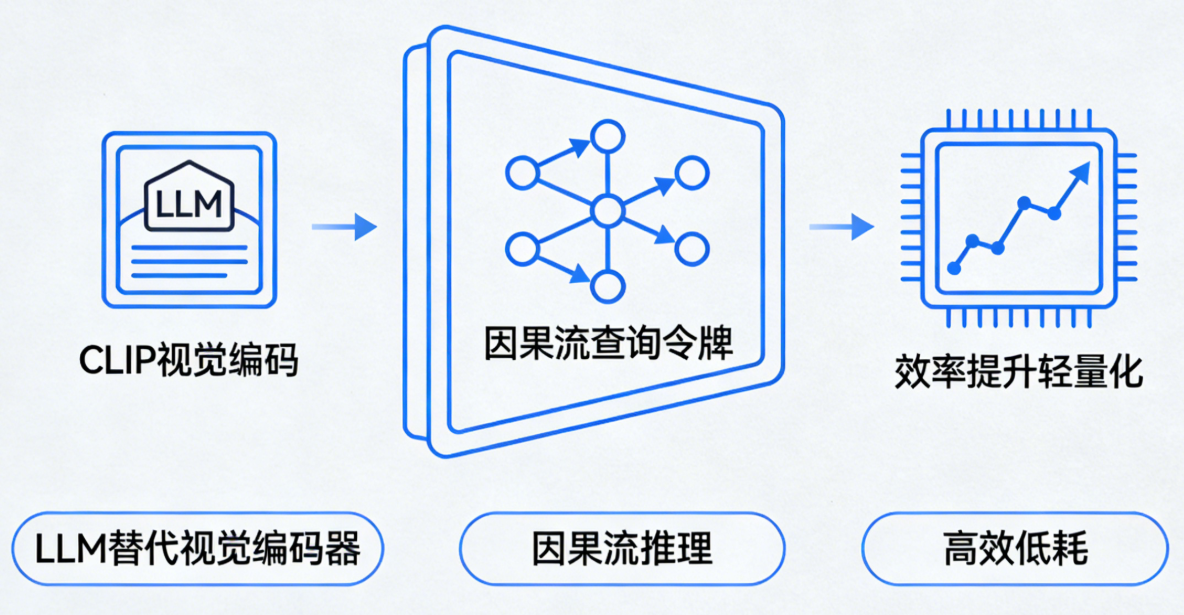
其一,是方法论的根本不同。 它没有在传统的“视觉特征提取”路线上修修补补,而是大胆地用一个小型大语言模型(LLM)替代了经典的CLIP视觉编码器。这意味着,模型在“看”图的第一瞬间,就在尝试进行“语言化”的理解和推理,让视觉理解和文本生成在底层架构上实现统一。
其二,是“因果流”的灵魂创新。 模型内部新增的“查询令牌”像一个内部的“调度指挥”,它以因果推理的方式,对全局视觉信息进行重要性排序和逻辑重组后,再交给解码器生成文本。这个过程模仿了人类“先览全局,再聚焦细节”的阅读习惯,从源头杜绝了信息顺序的混乱。
其三,是效率与效果的统一。 在AI领域,提升效果往往伴随计算量暴增。但DeepSeek-OCR2通过上述精巧设计,实现了“用更少的资源,办更好的事”,在多项基准测试中超越了计算资源可能更庞大的闭源模型,这在商业落地上具有决定性优势。
05 市场拓展:从数据清洗到“原生多模态”
DeepSeek-OCR2的野心,远不止于做一个“最好的OCR工具”。它的市场拓展路径清晰分为三步:
近期:夯实数据生产基础设施
作为当前最实用、最落地的视觉任务之一,OCR是绝佳的切入点。模型将首先在全球各大AI实验室、云服务商和数字化转型企业中铺开,成为它们数据预处理流水线的标准组件。通过解决最痛的问题,建立最广泛的技术口碑和生态依赖。
中期:孵化垂直行业解决方案
基于其优秀的架构和开源属性,预计将催生出一个繁荣的开发者生态。在金融、医疗、法律、教育等垂直领域,会涌现出大量基于DeepSeek-OCR2微调的专用模型,形成一个个细分市场的SaaS服务或私有化部署方案。
长期:通向统一的多模态“世界模型”
这才是DeepSeek团队的终极愿景。DeepSeek-OCR2验证了 “LLM作为通用编码器”的可行性。理论上,同一个模型架构,只需稍作调整,就能处理文本、图像、语音乃至视频。它为构建一个能够统一理解和生成一切信息的 “原生多模态”智能体,铺平了最关键的一段技术道路。届时,它的市场将不再是百亿级的数据处理,而是万亿级的人工智能本身。
06 结论
DeepSeek-OCR2的发布,是一次典型的“根技术”创新。它没有在应用层内卷,而是下沉到AI认知的基础层,重塑了机器“阅读”世界的方式。
当绝大多数公司仍在纠结于模型参数规模时,DeepSeek选择重构模型的“认知逻辑”。这不仅仅是为了让AI更准确地识别一份合同或一篇论文,更是为了给饥渴的AI世界,建造一座高效、纯净、结构化的“数据水库”。这座水库的水质,将直接决定未来所有大模型的智能成色。
