
AI视觉误差究竟多大?谷歌“像素操控”与DeepSeek“逻辑阅读”的可靠性对决


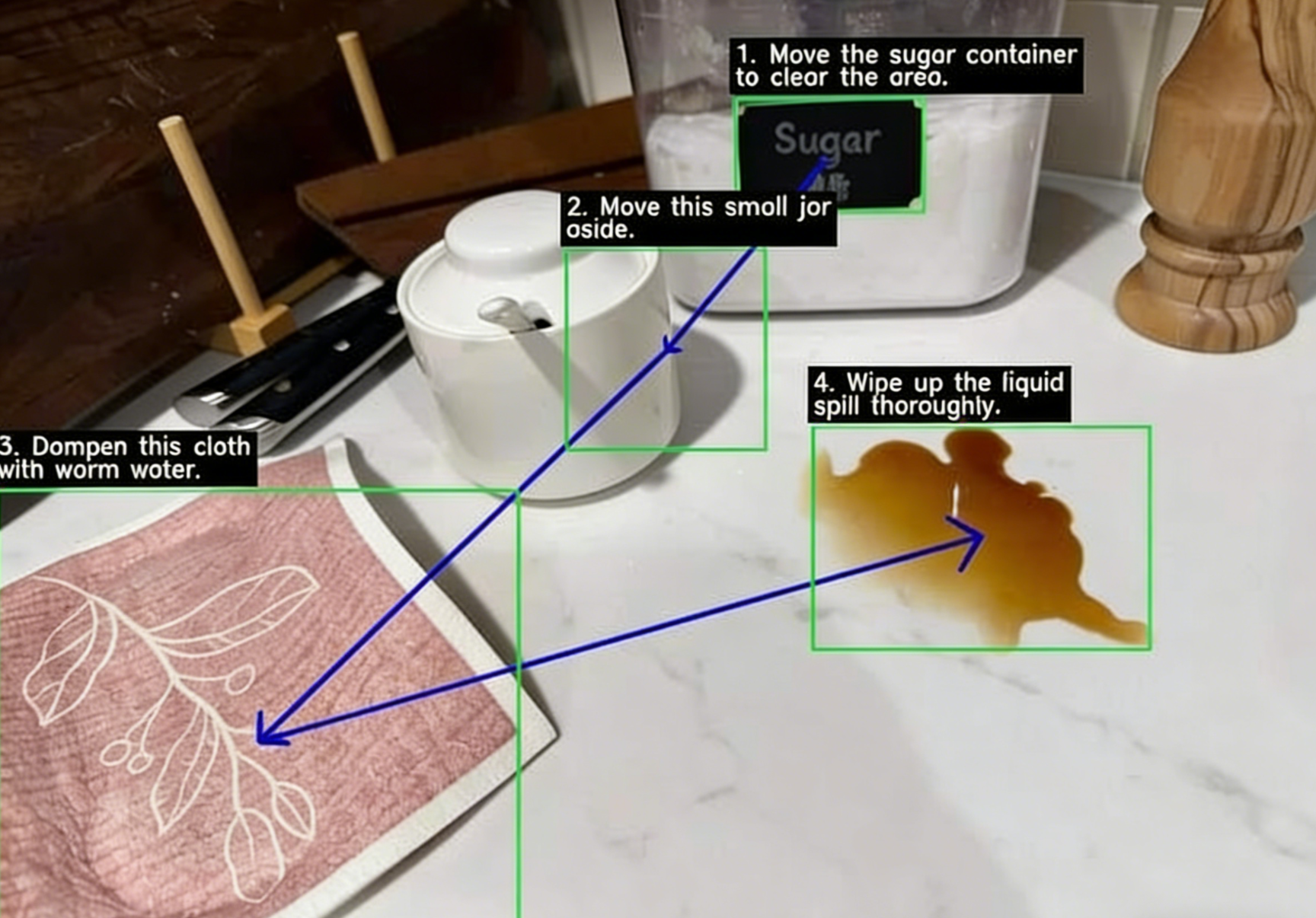
当AI不再只是“猜”图片里有什么,而是能自己写代码放大、标注、计算时,我们与机器的交互方式正被重新定义。
2026年1月27日,科技圈上演了一场精彩的“隔空对话”。前脚,中国的DeepSeek刚刚开源了能像人类一样逻辑阅读文档的DeepSeek-OCR2模型;几乎同一时间,谷歌DeepMind后脚就为Gemini 3 Flash模型重磅推出了名为 “Agentic Vision”(智能体视觉) 的新能力。

这远非巧合。如果说DeepSeek教AI“用心看”,那么谷歌则在教AI“动手做”。一场围绕“机器如何理解世界”的底层技术路线之争,已然拉开序幕。
01 从“静态看图”到“动态调查”
谷歌的Agentic Vision,彻底改变了AI处理图像的方式。你可以把它理解为一个被赋予了“显微镜和手术刀”的AI特工。
过去,AI看图片就像人快速扫一眼海报:如果角落里的文字太小或模糊,它只能连蒙带猜。现在,这个AI特工拥有了一套“思考-行动-观察”的行动闭环:
- 思考:分析你的问题(如“数清芯片上的引脚”),并制定计划。
- 行动:主动编写并执行Python代码去操作图像,比如放大特定区域、画框标注、甚至进行数学计算。
- 观察:检查处理后的新图像,基于确凿证据给出最终答案。
图片来源:新智元
这意味着,AI从被动的“图像描述者”,变成了能主动调用工具解决问题的“调查员”。例如,在建筑图纸审核平台PlanCheckSolver.com的实际应用中,启用此功能将验证准确率提升了5%。
02 AI处理图片的新功能
这项技术直击了当前视觉AI的最大软肋:不确定性带来的“幻觉”。
- 痛点一:细节丢失与猜测。面对高分辨率图片中的微小目标(如远处路牌、芯片序列号),传统模型因输入限制只能压缩图像,导致信息丢失,答案往往基于概率猜测。
- 痛点二:复杂推理的混乱。进行多步骤视觉推理(如“从图表中提取数据并对比趋势”)时,模型容易在过程中“迷失”,产生计算或逻辑错误。
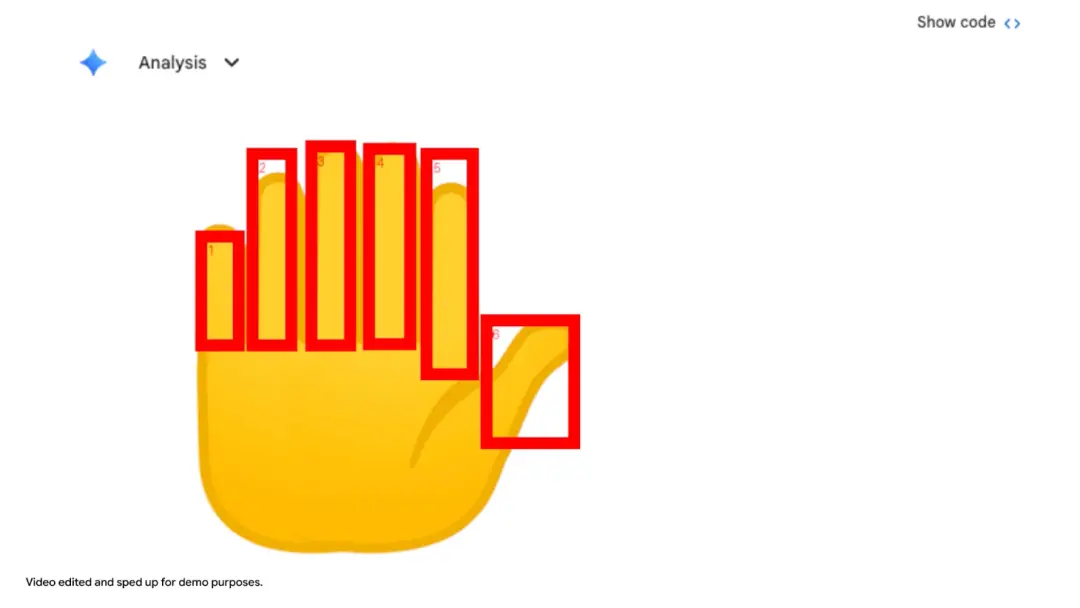
Agentic Vision的解决之道是 “让代码成为眼睛的延伸” 。当被要求数清图片中的人手上有几根手指时,Gemini 3 Flash会生成代码,在每根手指上画一个带数字的标记框,然后再输出答案。它将模糊的视觉感知,转化为可验证、确定性的代码操作,让AI的“思考过程”变得可见、可信。
03 与DeepSeek-OCR2的差异化
谷歌此次发布,被广泛视为对DeepSeek-OCR2的直接回应。两者代表了视觉AI进化的不同路径:
对比维度 | DeepSeek-OCR2 | 谷歌 Agentic Vision |
核心思路 | 模拟人类注意力:让AI学会像人一样,按内容逻辑(先标题后正文)动态调整阅读顺序。 | 赋予机器能力:让AI学会像程序员一样,调用外部工具(代码)主动改变观察视角以获取信息。 |
技术实现 | DeepEncoder V2架构:用小型语言模型重构视觉信息流,实现极致的逻辑理解与压缩。 | 代码执行引擎:将Python代码作为核心工具,进行图像处理、数学计算和可视化。 |
实现场景 | 复杂文档(报告、论文)的结构化理解与信息提取,追求高效和拟人化。 | 需要主动干预、精确测量或复杂计算的视觉任务(工业检测、图表分析、科学研究)。 |
简言之,DeepSeek让AI“看懂”世界的逻辑,而谷歌让AI“动手”验证世界的细节。
04 Agentic Vision 的未来蓝图
目前,Agentic Vision的能力虽强,但大多需要用户在提示词中明确引导(如“请放大那个角落”)。谷歌的未来路线图正在于此:
- 短期:能力完全隐式化。AI将能自主判断何时需要放大、计算或标注,无需用户提醒,体验将更加自然。
- 中期:工具多元化。从单一的图像处理代码,扩展到调用搜索引擎、专业数据库甚至机器人控制API,成为连接数字与物理世界的智能体。
- 长期:架构范式化。这种“模型规划+工具执行”的智能体范式,可能成为下一代AI的基础架构,从视觉扩展到声音、物理交互等全模态。
05 Agentic Vision 的风险与机遇
机遇方面,它打开了通往“可靠AI”的大门。在医疗影像分析、科学发现、工业自动化等领域,一个能提供像素级证据、而非概率猜测的AI,价值巨大。
风险与挑战同样突出:
- 计算成本激增:每轮“思考-行动-观察”循环都涉及多次模型调用和代码执行,推理成本和延迟远高于传统一次性识别。
- 复杂性与可靠性:代码执行可能引入新错误(如边界条件处理不当),需要更复杂的错误处理机制。
- 竞争与开源压力:正如DeepSeek-OCR2以开源带来冲击一样,封闭的尖端能力可能面临开源替代品的竞争。谷歌需在保持领先与开放生态间找到平衡。
06 总结与思考
谷歌Agentic Vision的发布,其意义远超一次普通的模型更新。它标志着AI从“感知智能”向“行动智能”关键一跃的尝试。
它与DeepSeek-OCR2的“隔空较量”,并非零和博弈,而是共同拓宽了AI能力的疆界。未来,最强大的视觉系统或许将是二者的融合:一个既能像人类一样理解复杂场景的内在逻辑,又能像超级工具一样主动验证和操控细节的智能体。
对于开发者和企业而言,这预示着一个新规则:未来的AI应用竞争力,可能不仅取决于模型本身的大小,更取决于其与工具和环境交互的深度与灵活性。当AI学会了“动手”,所有需要“眼手协调”的行业,都值得被重新想象。
