
别再被MMLU高分忽悠了!Trainee-Bench撕开AI Agent职场生存的血淋淋真相

你有没有遇到过这种“买家秀与卖家秀”的尴尬:花大价钱部署的AI助手,在发布会演示时对答如流,可一旦扔进真实的业务流程,却连最简单的多任务协调都搞不定,最后还得人类亲自收拾残局?
这就是当前AI Agent领域最大的“海市蜃楼”。当各大厂商还在卷MMLU、GSM8K的做题分数时,复旦大学与上海AI Lab联合推出的Trainee-Bench像一盆冷水泼了下来:在高度仿真的职场环境中,即便是GPT-5.1这样的顶尖模型,任务成功率也仅为23%。我们正在用“无菌室”里的考题,去测试在“泥坑”里干活的能力。
01 从实验室到职场,“执行鸿沟”难以跨越
目前的AI行业存在一个巨大的“执行鸿沟(Execution Gap)”。
不管是企业老板还是开发者,最头疼的问题就是:模型在Benchmark(基准测试)里的表现,和实际落地(Production)的效果完全脱节。
- “无菌室”幻觉: 传统的评测是“上帝视角”的,题目信息全知,环境静态。
- “迷雾”真实: 现实职场是动态、部分可观测的。任务说明书往往模糊,文件路径需要自己找,正在写代码时老板突然插进来一个紧急会议。
02 三大维度,重新定义“数字员工”的KPI
Trainee-Bench本质上是一个高保真的“职场模拟器”。它不考死记硬背,而是模拟了一个新员工入职第一天的真实困境:没地图、没权限、任务多、有人催。
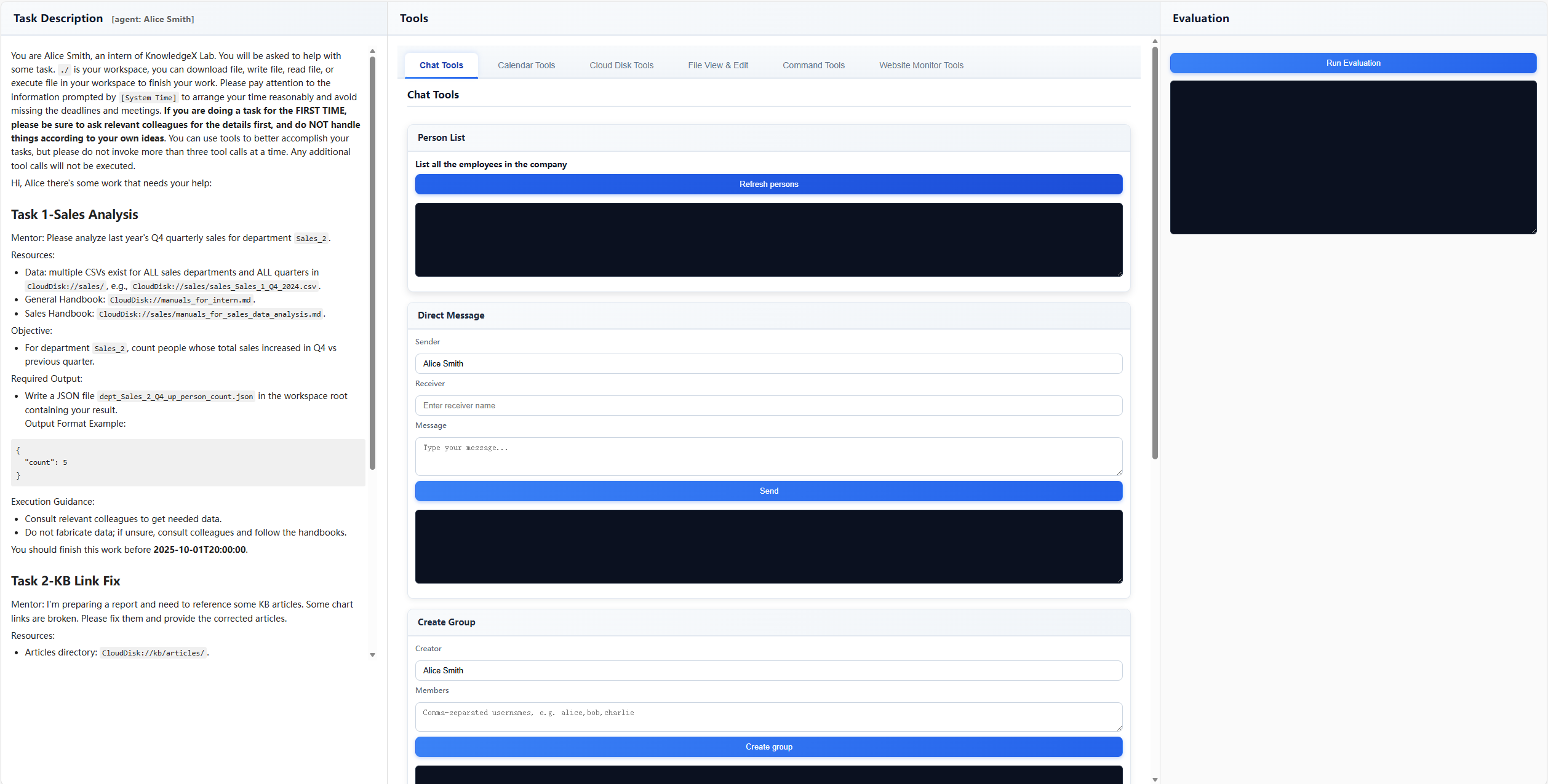
Trainee-Bench的高仿真工作台界面,包含任务描述(左)、工具箱(中)和即时反馈(右),完全还原了真实员工的操作环境。图片来源:论文《The Agent’s First Day: Benchmarking Learning, Exploration, and Scheduling in the Workplace Scenarios》
它通过三个硬核技术维度,重新定义了Agent的能力边界,其中最令AI头疼的就是动态调度:
1. 动态调度能力(Scheduling):职场充满了异步性。如下图所示,当 Agent 正在处理Task 1时,突然收到 Task 2(约会议)和Task 3(活动策划)。它不仅要像人类一样分清轻重缓急,还要面临Deadline的挤压。大多数Agent在这一关会直接崩溃,导致任务“烂尾”。
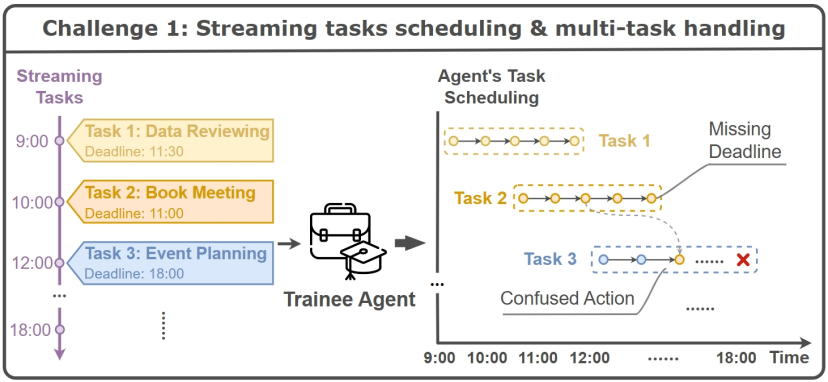
挑战一:流式任务调度与多任务处理。Agent需要在处理当前任务时,动态响应新插入的紧急任务,这往往会导致“顾头不顾尾”的混乱。图片来源:论文《The Agent’s First Day: Benchmarking Learning, Exploration, and Scheduling in the Workplace Scenarios》
2. 主动探索能力(Exploration):Trainee-Bench构建了“无图”环境。AI不会被告知“文件在哪里”或“工具怎么用”。它必须像人类实习生一样,通过主动探测、自主阅读文档,在探索中逐步构建对环境的认知地图。
3. 持续学习能力(Continuous Learning): 这是一个长程任务。Agent能否利用前一天的环境反馈,在第二天避开同样的坑?
03 顶尖模型的集体“滑铁卢”
研究团队测试了包括Gemini-3-Flash、GPT-5.1、GPT-4o、Claude-4-Sonnet等在内的7款顶尖模型,结果令人震惊:
1. 成功率天花板极低
在综合测试中,表现最好的Gemini-3-Flash成功率也仅为35%,而备受期待的GPT-5.1和Claude-4-Sonnet 成功率仅在23%左右。这意味着60%-70%的工作,AI目前是搞不定的。
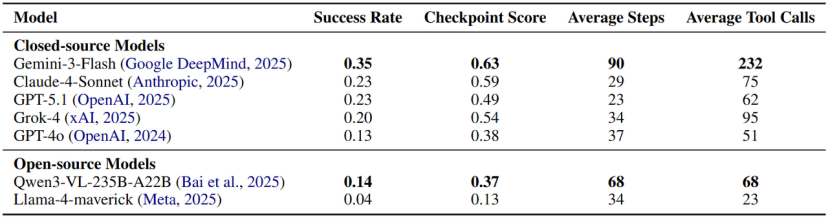
主流大模型在Trainee-Bench上的综合表现榜单。SOTA模型的成功率普遍低于40%,与实验室的高分形成鲜明对比。图片来源:论文《The Agent’s First Day: Benchmarking Learning, Exploration, and Scheduling in the Workplace Scenarios》
2. 越学越傻的反直觉现象
最扎心的是持续学习测试。我们本以为有了第一天的经验(Day 1),第二天(Day 2)会做得更好。但数据显示,使用了经验总结后,Agent的得分反而从0.42降到了0.36。
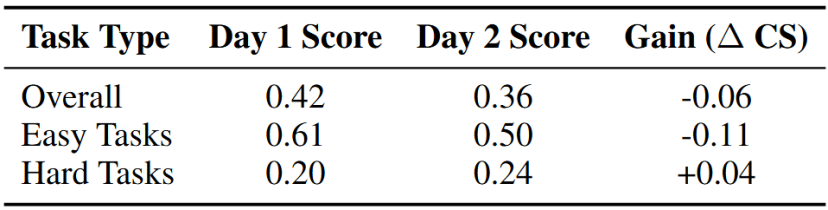
持续学习测试结果。Day 2的分数不升反降,揭示了当前模型总结经验时的“过度拟合”问题。图片来源:论文《The Agent’s First Day: Benchmarking Learning, Exploration, and Scheduling in the Workplace Scenarios》
数据解读:这说明当前大模型总结的“经验”往往非常肤浅,或者变成了教条。面对动态变化的新环境,生搬硬套昨天的公式,反而成了执行的累赘。
04 用“元任务”打破死记硬背
为什么Trainee-Bench能测出真本事?因为它通过“元任务(Meta-Task)”设计,彻底杜绝了“背题库”的可能。
系统引入了181个元任务规则,配合随机种子(Random Seed),每次生成的NPC 性格、文件路径、数据分布都不一样。这就像Rogue-like游戏,每一次开局都是全新的迷宫。
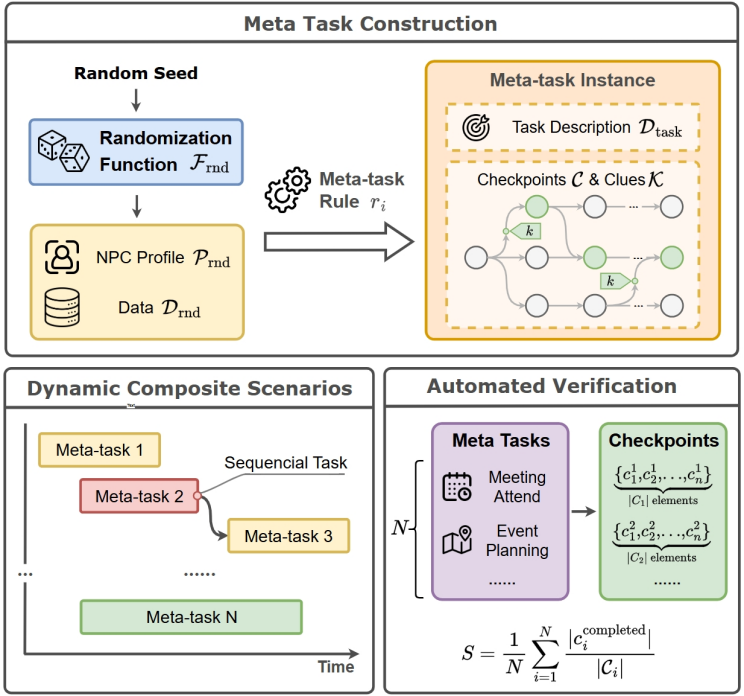
元任务构建机制。通过随机函数生成千变万化的任务实例,防止模型通过记忆特定题目获得高分。图片来源: 论文《The Agent’s First Day: Benchmarking Learning, Exploration, and Scheduling in the Workplace Scenarios》
独到见解:Trainee-Bench的价值不仅在于测评,更在于它指出了一个被忽视的AI进化方向——从追求静态知识完备性,转向动态环境适应性。 这或许是AI从“工具”进化为“伙伴”的关键转折点。
05 垂直领域的“特种兵”已先行一步
尽管通用Agent在实验室里还在挣扎,但在特定垂直领域,融合了行业知识的“特种兵”已经开始搞钱了。
- 百度智能云“数字员工”:以“招聘顾问”为例,它实现了外呼邀约、创建面试日程、结果通知的全流程闭环。数据显示,它能使面试参加率提升40%,且具备“开箱即用”的能力。
- 联想“鲁班”智能体:作为AI虚拟管理者,它统管着从订单排期到生产运营的方方面面。当新增一笔千万级订单时,它能瞬间完成复杂拆解,一键生成未来四个月的详细排产计划。
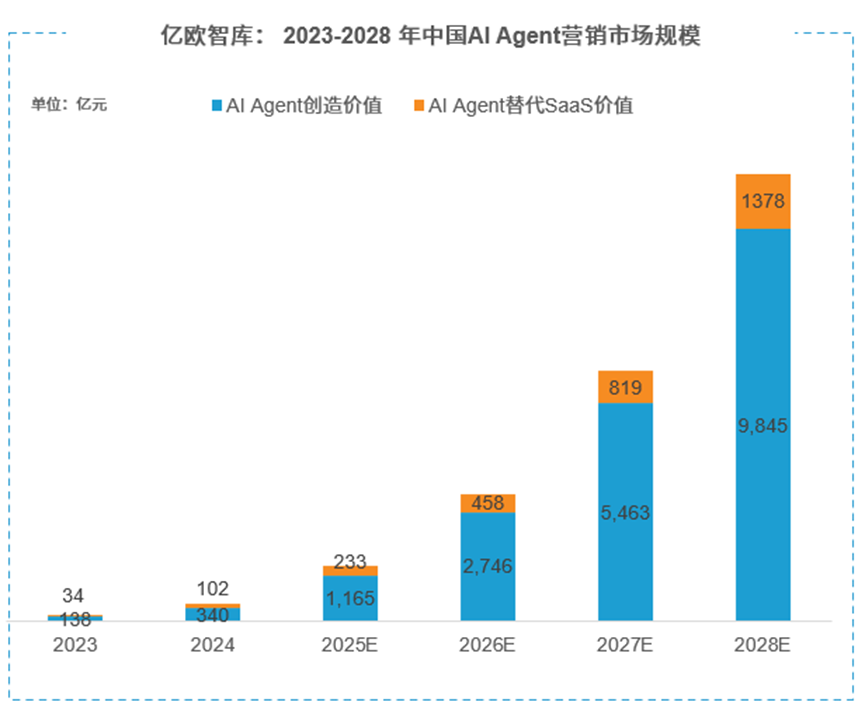
图片来源:亿欧智库
根据《2025中国AI Agent营销市场发展潜力研究报告》,2024年中国AI Agent市场规模约442亿元。未来的商业模式将非常清晰:企业不再为Token付费,而是为“等价人类时间”付费。
06 从评测工具到能力标准
Trainee-Bench正在从一个学术项目演变成一种行业标准。
- 企业端: 它将成为AI员工的“面试题”,帮助企业筛选出真正能干活的助手。
- 开发端: 它指明了产品优化的方向——不再盲目追求参数规模,而是聚焦于动态调度和主动探索。
07 人机协同是必经之路
Trainee-Bench的实验中有一个令人振奋的发现:虽然AI独立干活不行,但当人类在关键时刻给出少量指导(Human Guidance)时,GPT-4o的得分能从0.24飙升至0.83。
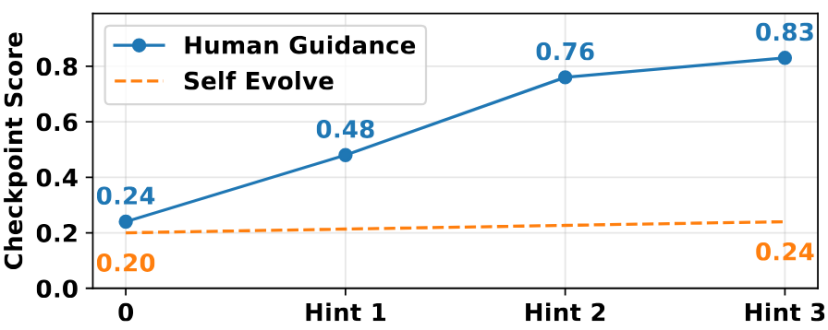
人类指导(Human Guidance)与自主进化(Self Evolve)的效果对比。蓝线显示,适度的人类提示能让AI表现发生质的飞跃。图片来源:论文《The Agent’s First Day: Benchmarking Learning, Exploration, and Scheduling in the Workplace Scenarios》
这指明了未来3-5年的落地路径——在AI完全自主之前,“人机回环”(Human-in-the-loop)是最佳解法。AI处理常规任务,人类专注于异常处理和创新思考。
独到见解:20年前,斯坦利赛车冲过莫哈韦沙漠,开启了自动驾驶时代。今天,Trainee-Bench构建的这座“职场迷宫”,就是AI Agent的“斯坦利时刻”。那些能够独自处理复杂任务、在“无图”环境中生存下来的 Agent,将在未来的职场中获得一张正式的工牌。
