
暴打谷歌Genie?蚂蚁灵波LingBot-World开源:让AI像玩3A大作一样“造世界”

2026年才刚开局,AI圈的火药味就浓得呛人。
当大洋彼岸的谷歌还在把Genie 3捂在怀里,搞神秘的“闭源秀”时,蚂蚁灵波(Robbyant)直接把桌子掀了——就在1月底,他们一口气开源了具身智能的三大件,其中最炸裂的当属世界模型LingBot-World。
这不是那种只能看几秒钟的“GIF生成器”,而是一个能让你用键盘鼠标实时操控、物理规律长期在线的“虚拟世界”。对于苦于没有训练数据的机器人行业来说,这简直就是天上掉馅饼。
先别听那些晦涩的技术名词,直接来看这个“世界”到底有多真。在第一人称视角下,你甚至可以骑在龙背上俯瞰丛林,画质极其细腻,且支持实时交互:
LingBot-World的第一人称视角演示,展示了极高的动态保真度,左下角显示支持WASD实时操控。视频来源:LingBot-World
01 AI懂画面,但不懂“物理”
目前的AI视频行业,最大的尴尬在于“有皮没骨”。
- 无法交互: 视频生成了就是定局,用户无法干预走向。
- 逻辑崩塌: 短时间看挺美,时间一长,物体这就穿模、那儿消失,AI根本不懂因果律。
- 数据孤岛: 具身智能(机器人)训练太贵太慢,在真实世界里试错成本高得吓人。
行业急需的,不是画质更卷的“画家”,而是懂物理、能交互的“模拟器”。
02 言出法随的“造物主”视角
LingBot-World的核心能力,简单说就是“可玩的视频”。它不仅仅是生成一段影像,而是允许你深度参与其中。
不仅能“动”,还能“改”
LingBot-World最惊艳的功能之一是Promptable World Event(可提示的世界事件)。如下图所示,给定一个初始场景(左侧),你可以通过文字指令彻底改变它的走向。
- 风格突变: 输入“Ice world”,丛林瞬间冰封,但地形结构保持不变。
- 因果干预: 输入“Fireworks”(放烟花),天空中炸开绚烂的火花;在罗马许愿池输入“Fish”,水中就会游出锦鲤。这种局部干预(Local Interventions)与全局环境迁移(Global Environmental Shifts)的结合,展示了极强的可控性。

图片来源:论文《Advancing Open-source World Models》
惊人的“记忆力”:生成即记住
对于机器人训练来说,最怕的就是“灾难性遗忘”——镜头一转,刚才的路就不见了。 LingBot-World解决了这个问题。如下图所示,在长达60秒的交互中,当镜头移开巨石阵(Stonehenge)再转回来时,巨石的排列结构纹丝不动;当相机向前移动后回头,远处的桥梁依然在它该在的位置。这种长时序一致性(Long-term Consistency),让它不仅仅是视频生成,而是真正的空间模拟。

图片来源:论文《Advancing Open-source World Models》
03 它是如何“理解”世界的?
为什么LingBot-World能做到谷歌Genie 3都还在攻克的难题?根据蚂蚁灵波发布的论文《Advancing Open-source World Models》,团队并没有从零开始“硬Train”,而是走了几步巧棋。
第一步:混合数据引擎(Hybrid Data Engine)
这是它懂物理的关键。团队不仅用了海量的真实视频,还创新性地引入了虚幻引擎(Unreal Engine)生成的合成数据。如下图所示,系统将计算资源与游戏引擎结合,捕获与动作信号(WASD)和相机状态时间对齐的视觉观测数据。这相当于给模型开了“天眼”,让它直接学习动作与环境变化的因果关系。
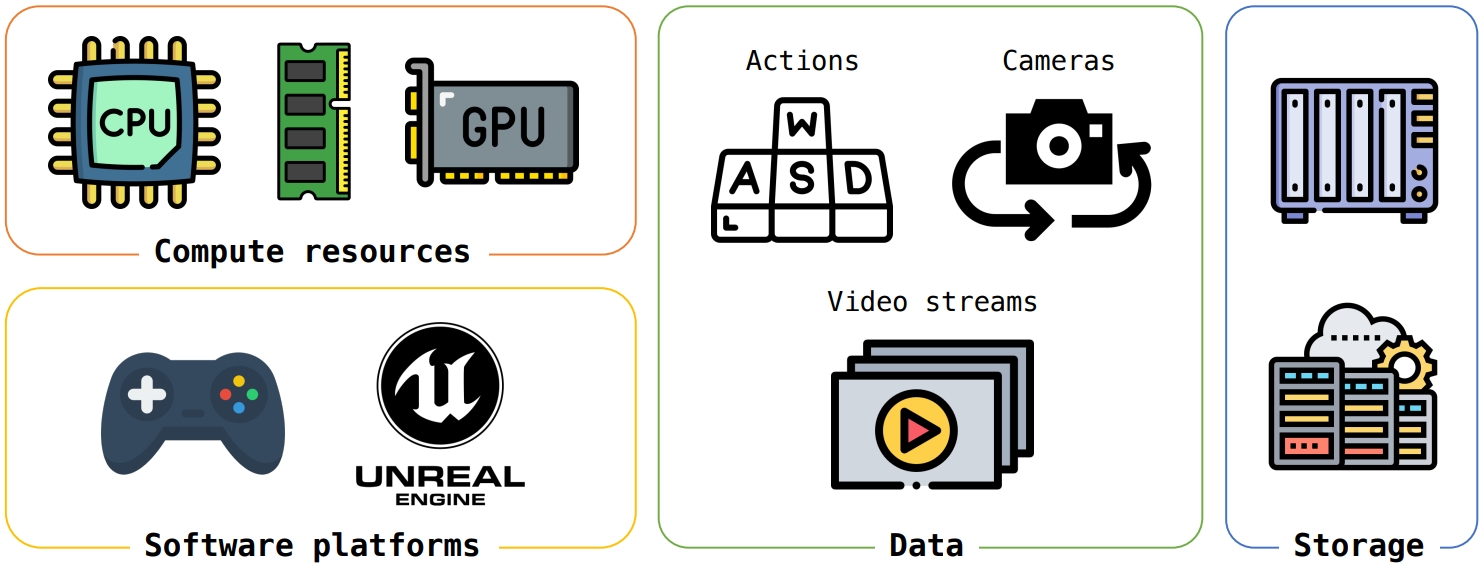
图片来源:论文《Advancing Open-source World Models》
第二步:精细化的数据“清洗”与标注
为了让模型听得懂人话并理解物理世界,LingBot-World建立了一套严密的数据分析引擎。从原始数据(Raw Data)出发,经过属性提取、质量过滤,再到语义分析(VLM Profiling)和几何标注,最终生成分层的描述(Caption)。 这种分层标注策略将描述拆解为:叙事描述(讲故事)、静态场景描述(只看环境)和时序描述(精确动作),从而实现对背景与运动的完美解耦。
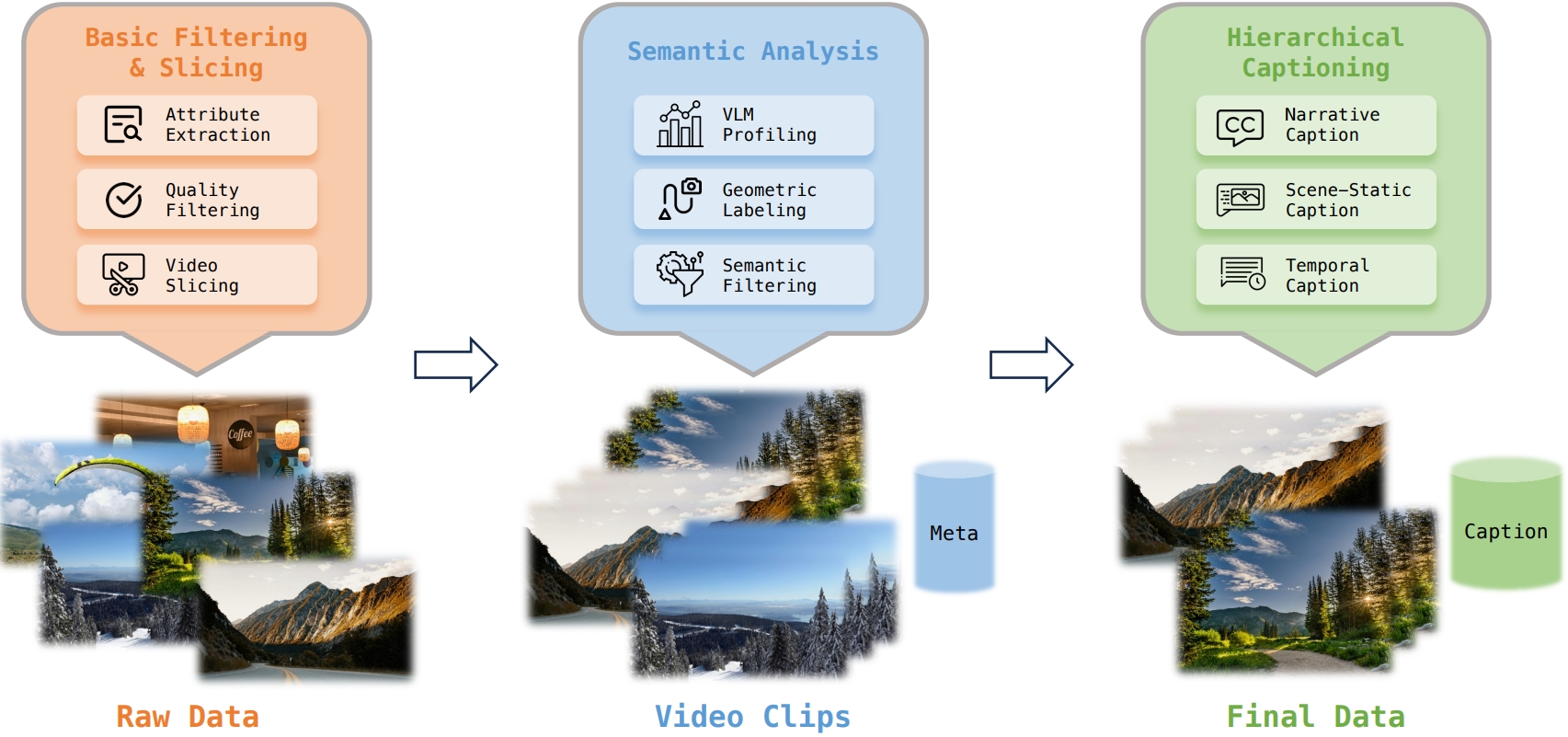
图片来源:论文《Advancing Open-source World Models》
第三步:三阶段进化与DiT架构
模型经历了从“预训练”(学会画画)、“中训练”(注入物理规律)到“后训练”(剑指实时性)的三个阶段。 为了实现精准控制,团队采用了DiT(Diffusion Transformer)架构,并设计了独特的动作注入机制。如下图所示,动作信号通过 Plücker 编码器注入,直接调制视频生成的潜变量(Latent),确保了每一次按键都能精准反馈到画面上。
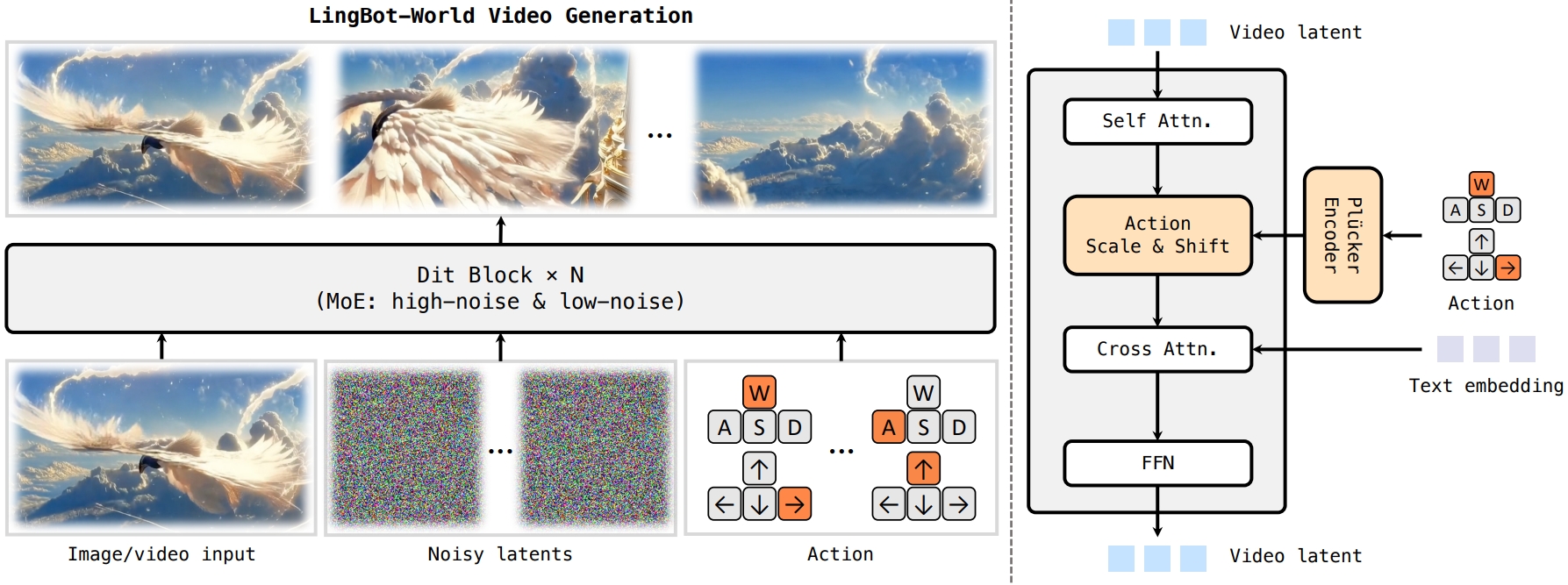
图片来源:论文《Advancing Open-source World Models》
04 性能碾压竞品
光说不练假把式,我们整理了LingBot-World与行业标杆(如Matrix-Game, Genie 3等)的关键实测数据对比。 从下表可以看出,LingBot-World是唯一同时兼顾了“通用领域(General Domain)”、“长生成视窗(Long Horizon)”、“高动态度(High Dynamic)”且完全开源的模型。

与近期交互式世界模型的参数对比(Table 1)。LingBot-World 在生成时长、分辨率、实时性及开源属性上全面优于竞品。图片来源:论文《Advancing Open-source World Models》
关键指标解读:
- 交互延迟 < 1秒: 真正实现了 Real-time Playable。
- 生成时长 10分钟+: 解决了长时序任务训练难题。
- 帧率 16 FPS: 保证了流畅的交互体验。
- 开源(Open-source): 打破了大厂的技术垄断。
05 Sim-to-Real的降维打击
LingBot-World 的开源,本质上是蚂蚁灵波在构建具身智能的基础设施。它的野心不仅仅是生成视频,而是理解三维空间。
最令人信服的证据来自下图的3D重建测试。LingBot-World 生成的视频不仅仅是像素的堆叠,它具有严谨的空间几何一致性。通过算法,可以直接将生成的视频转化为高质量的3D点云(Point Clouds)。
这意味着,机器人在这个虚拟世界里学到的导航和避障技能,是可以直接迁移到真实(Real)世界的。这才是 Sim-to-Real 的终极奥义。

图片来源:论文《Advancing Open-source World Models》
独到见解:蚂蚁灵波这盘棋,以具身智能为起点,最终指向的很可能是AGI(通用人工智能)的终极形态——理解并模拟整个物理世界。当开发者都习惯了在这套架构上跑数据、训机器人,蚂蚁就成为了具身智能时代的“安卓”。
目前,该项目代码、模型权重及论文已全部在GitHub和Hugging Face开源,感兴趣的开发者可以前往体验:
- GitHub:
github.com/robbyant/lingbot-world - Hugging Face:
huggingface.co/collections/robbyant
