
告别“人工”智能:北大发布机器人防伪标准,马斯克们的好日子到头了?
当马斯克誓言 2026 年量产 Optimus 时,华尔街的狂欢与技术圈的冷思考形成了鲜明反差。所谓“iPhone 时刻”背后,实则是一场信任赌局:若剥去视频加速与远程操控的伪装,那些看似灵巧的机器人可能瞬间退化为人工智障。
这正是具身智能赛道的痛点:我们拥有了越来越强的模型,却仍用石器时代的尺子衡量它们。单一的成功率指标不仅掩盖了动作僵硬等隐患,更助长了Demo 造假泡沫。就在行业急需审计风暴之际,北大与中科院团队推出了 Eval-Actions 与 AutoEval 架构。这不仅是技术革新,更是一把切开评估黑箱的手术刀,为市场提供了一把刺破泡沫、筛选真正独角兽的防伪利刃。
这不再是学术象牙塔里的游戏,而是即将改写行业估值逻辑的规则变迁。当评估不再唯结果论,谁在裸泳,谁是真金,都将在这套新范式下无所遁形。这场具身智能的审计革命,正重新定义商业化的起跑线。
被二元成功率掩盖的产业隐患
在商业世界里,如果一家自动驾驶公司告诉你:“我们的车只要能开到终点就算成功,不管中间是否撞了护栏、压了草坪或让乘客呕吐”,你敢坐吗?遗憾的是,这就是目前机器人操作评估的真实写照。
随着 Vision-Action (VA) 和 Vision-Language-Action (VLA) 模型的爆发,机器人看似脑子变聪明了,但我们考核它的逻辑依然停留在二元对立的粗糙阶段。这种落后的评估范式,在产业落地中挖下了两个巨大的深坑:

1. 执行质量的灰度陷阱:不仅要看结果,更要看体态
目前的评估体系是一个典型的“唯结果论”者。在传统的二元评价体系下,评估逻辑极其简单粗暴:任务完成了就是 1,没完成就是 0。
两个机器人同时执行倒咖啡任务。模型 A 动作行云流水,杯身稳定,液面平滑;模型 B 虽然也把咖啡倒进了杯子,但过程中机械臂剧烈抖动,咖啡差点洒出,甚至因为动作僵硬导致电机发出刺耳的啸叫。按照现有的评价体系,A 和 B 的得分都是 100% 成功。
这种灰度在实验室里也许只是不够优雅,但在商业落地中却是致命的。在工业场景,抖动意味着精密零件的良品率下降和机械臂关节寿命的缩短;在家庭场景,面对老人和小孩,这种不稳定的成功随时可能演变成拿刀伤人或打碎贵重物品的安全事故。无法区分平滑成功与抖动成功,就意味着无法为机器人颁发进入人类社会的安全通行证。
2. 来源真实性的信任黑洞:是 AI 进化,还是“人工”智能?
这是目前一级市场投资人最头疼,也是最为讳莫如深的问题。
为了在路演中展示智能,或者为了在学术论文中刷高分数,行业内存在一种潜规则——利用人类远程遥操作来冒充 AI 自主决策。这种“Wizard of Oz(绿野仙踪)”式的操作,使得视频中的机器人表现出惊人的灵巧度。
对于非技术背景的观察者,甚至是一般的审核人员,很难通过肉眼分辨一段视频究竟是模型推理的结果,还是人类在后台“提线木偶”般的表演。
这种来源模糊性直接导致了估值泡沫。一家可能只具备 PPT 造车能力的公司,凭借几段精心录制、人工操控的 Demo 视频,就能骗取巨额融资。这导致市场无法分辨谁是真技术,谁是剪辑大师,不仅造成了资本的无效配置,更让真正踏实做研发的企业面临“劣币驱逐良币”的窘境。
Eval-Actions 与 AutoEval —— 机器人的全身体检
为了终结这场“差不多先生”的游戏,北大与中科院团队没有选择修补旧船,而是重新造了一艘船。他们提出的方案由两部分组成:一套是以最大化故障覆盖与来源混合为特征的诊断性基准(Eval-Actions),一套是集成细粒度动作捕捉与逻辑一致性校验的自动化评估架构(AutoEval)。
1. Eval-Actions 基准:打破“唯成功论”,首创故障诊断机制
以往的主流数据集(如 Open X-Embodiment)主要是为了训练模型而生,它们追求数据量的庞大,倾向于只收录成功的演示视频。但 Eval-Actions 的设计哲学完全不同,它是为了诊断而生。
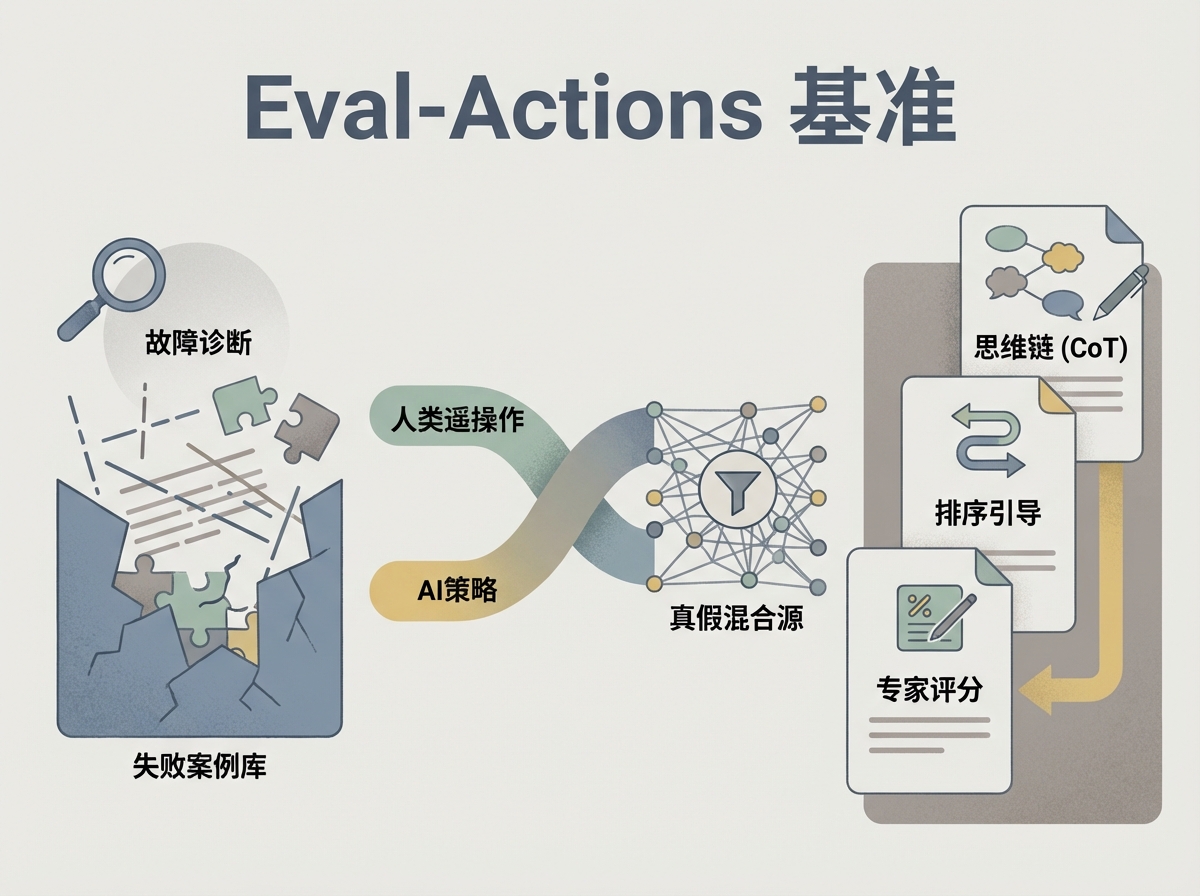
- 引入失败案例库: 这是一个反直觉但极具价值的创新。该数据集不仅包含成功轨迹,还特意引入了约 2800条失败数据。在商业逻辑上,这相当于汽车碰撞测试。只有知道机器人在什么情况下会失败、如何失败,模型才能真正学会错误恢复和鲁棒的失败检测。
- 构建真假混合源: 它是首个混合了人类遥操作数据与多种策略(VA 及 VLA 模型)生成轨迹的数据集。这实际上是为鉴伪算法提供了完美的训练场,专门用来训练鉴别“李鬼”的能力。
- 多维度的精细批注: 它不再满足于简单的打分,而是提供了专家评分(Expert Grading)、排序引导(Rank-Guided)以及思维链(Chain-of-Thought, CoT)三种层次的注释。这就像老师改卷子,不仅给分数,还写评语,甚至指出解题逻辑的漏洞。
2. AutoEval:双引擎破解细节盲区与逻辑幻觉
如果说 Eval-Actions 构建了包含各类极端工况的底层数据基准,那么 AutoEval 则是基于这一基准执行精准判定的核心算法引擎。针对传统通用大模型(VLM)在评估时“看不清细节”和“乱瞎说”的两大通病,团队创新性地设计了双分支架构:
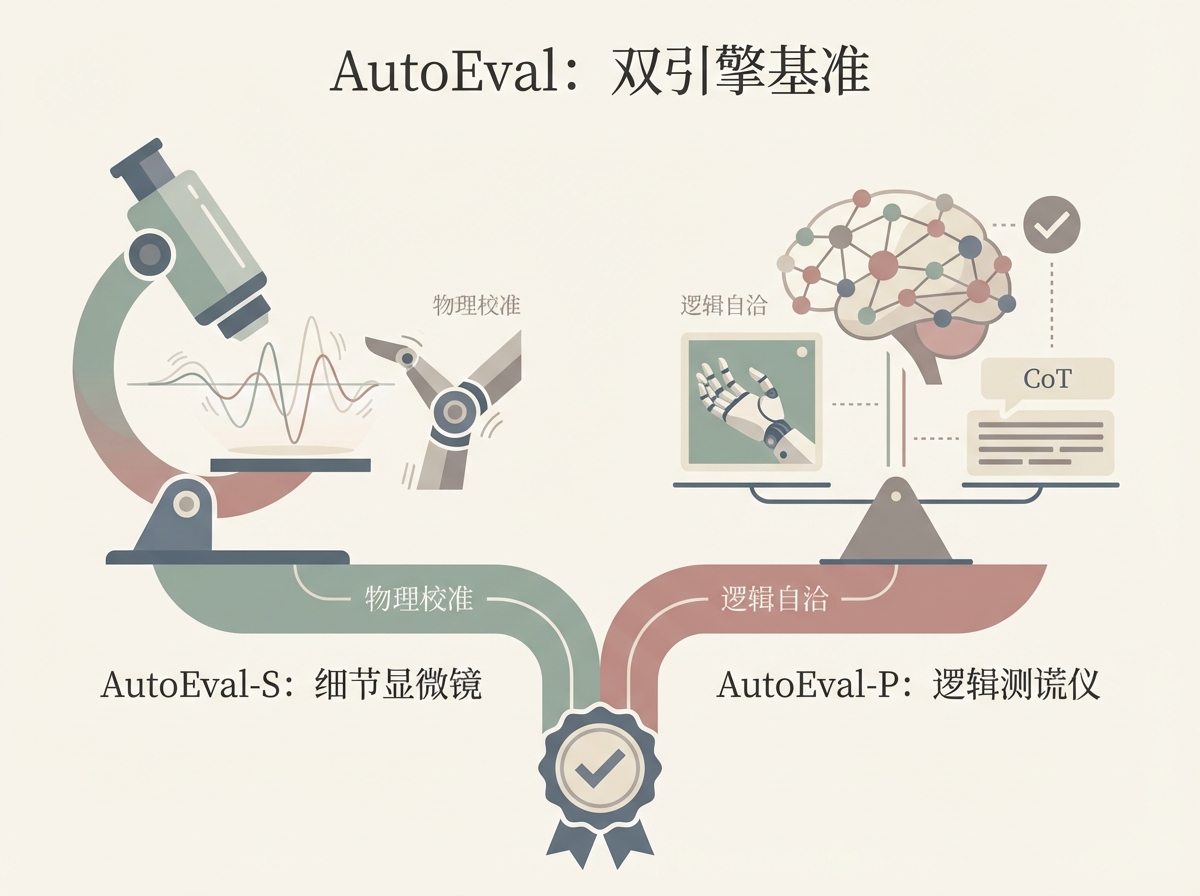
- AutoEval-S(Small):专治动作僵硬的显微镜
传统的 VLM 往往只看关键帧,容易忽略过程。AutoEval-S 引入了时空聚合策略,将高频的运动细节“压缩”进视觉 Token 中。更绝的是,它辅以物理校准信号,直接利用速度、加速度方差等运动学数据来校准视觉评估。
核心价值: 哪怕是肉眼难以察觉的微小抖动,它也能通过物理数据捕捉到。
- AutoEval-P(Plus):专治“逻辑幻觉”的测谎仪
大模型经常出现幻觉,嘴上解释说动作完美,实际上物体已经掉了。AutoEval-P 引入了 GRPO(组相对策略优化) 强化学习范式。它通过混合奖励函数,强制模型“言行一致”。AutoEval-P 被训练成必须在生成评分的同时,给出逻辑自洽的物理推理(CoT)。如果推理逻辑与物理事实不符,就会受到惩罚。
一把标尺的诞生,及其可能锁死的未来?
然而,在为新范式欢呼之前,我们必须保持清醒:技术标准从来不只是技术问题,更是权力与叙事的话语权之争。
当北大与中科院试图为行业树立一把标尺时,这把标尺本身是否绝对中立?它所定义的“平滑”“安全”“高效”,是否在无形中确立了某种技术路线的正统性,从而压抑了其他可能更具创造性、却暂时不规范的探索?评估范式的统一,在终结混乱的同时,也可能悄然构筑新的技术霸权。
更进一步,AutoEval 高达99.6%的辨伪能力,在刺破旧泡沫的同时,是否会催生更高级的造假?就像反作弊技术总与作弊技术共同进化,当评估本身成为目标,研发精力是会导向真正的鲁棒智能,还是仅仅为了在“全身体检”中刷出漂亮分数?我们防止了AI幻觉,但可能正在制造“考试机器”。
更深层的悖论在于:我们试图用一套确定的、可量化的框架,去框定智能本身固有的不确定性和涌现性。 这或许是工程化落地的必经之路,但也可能是对智能本质的一次粗暴简化。当评估聚焦于动作的物理平滑度时,是否忽略了任务背后意图理解的模糊性与上下文依赖性?一个在物理指标上稍显抖动但能灵活应对突发状况的机器人,与一个动作标准却僵化死板的机器人,谁更智能?新范式尚未回答。
因此,Eval-Actions 与 AutoEval 的真正价值,或许不在于它给出了终极答案,而在于它第一次为行业提供了可争议、可检验、可迭代的公共讨论基础。它将评估从黑箱中拖出,暴露在阳光之下,允许所有人审视、质疑并改进这把“手术刀”本身的锋利与偏差。
马斯克的2026年宣言,与其看作一个技术里程碑,不如视为一道迫使我们直面信任危机的最后通牒。在这场具身智能的审计革命中,比甄别裸泳者更重要的,或许是整个行业必须共同建立一种新的心智模式:真正的安全与信任,并非源于一份无可挑剔的体检报告,而是源于我们对技术限度的深刻认知,以及为这套评估体系注入持续反思与人文审视的集体自觉。
毕竟,当机器人最终走入我们的客厅和工厂时,我们需要的不仅是不会洒出咖啡的机械臂,更是一个我们理解其如何失败、并能与之共担风险的可对话伙伴。这最后的信任,无法被任何算法评分所证明,它只能在技术透明与人类审慎的持续对话中,被艰难地构建。
