
国产GLM-OCR真狠!0.9B小模型拿下全球第一,巨头们慌了?

还在为堆积如山的发票报销头疼吗?还在熬夜把纸质文件一个字一个字敲进电脑吗?或者,你开发的APP总被用户吐槽:手写体识别不了、表格图片转不了Excel?
告诉你个好消息,这些苦日子可能要到头了。最近,国内AI大厂智谱AI放了个“大招”,正式开源了一款名叫GLM-OCR的“文字扫描神器”。它最让人吃惊的地方在于,本事大得吓人,但体格却非常轻巧,而且便宜到离谱,目标就是要把所有繁琐的工作在电光火石间自动完成。
01 OCR不是新鲜事,但好用的太贵,便宜的又“眼瞎”
先把OCR说简单点,它就是让电脑看懂图片里文字的技术。这技术其实不新,但过去的方案总是让人左右为难。

传统的开源工具,比如老牌的Tesseract,虽然不要钱,但“眼神”不太好。一旦遇到稍微复杂点的场景,比如字迹潦草的手写体、背景杂乱带印章的发票、结构复杂的表格,或者中英文混排的文档,它就很容易抓瞎,识别出来的结果错漏百出,后面还得人工花大量时间去核对。一份国外2025年的技术评测也显示,传统OCR工具在复杂图像上的单词错误率(WER)可能高达0.7以上(数值越高越差,1代表全错)。
另一边,那些识别率很高的OCR服务,通常是谷歌、微软、亚马逊这些国外大厂提供的云端服务,用起来效果是不错,但价格也相当“美丽”。处理海量文档时,账单会飞快上涨,而且你的所有文件都得上传到别人的服务器,对一些涉及敏感数据的企业来说,心里总不踏实。
所以,市场一直在等一个答案:有没有一款工具,既能像顶级服务一样“眼力好”,又能像开源软件一样“成本低、自己可控”?
02 0.9B小身材,如何拿下全球顶级榜单?
智谱开源的GLM-OCR,就是冲着这个终极问题来的。它的第一个震撼点,是极其“迷你”的体型——参数量只有0.9B。你可以把它理解成模型的“脑容量”,这个数字在动辄成百上千亿参数的大模型时代,简直是个“小不点”。
但千万别小看这个“小不点”。在衡量文档解析能力的全球权威榜单OmniDocBench V1.5上,GLM-OCR一战封神,综合得分高达94.6分,拿下了第一名的成绩(SOTA)。这意味着它的综合识别能力,已经超过了榜单上许多专门用于OCR的大模型,甚至接近谷歌最强的通用大模型Gemini-3-Pro的水平。
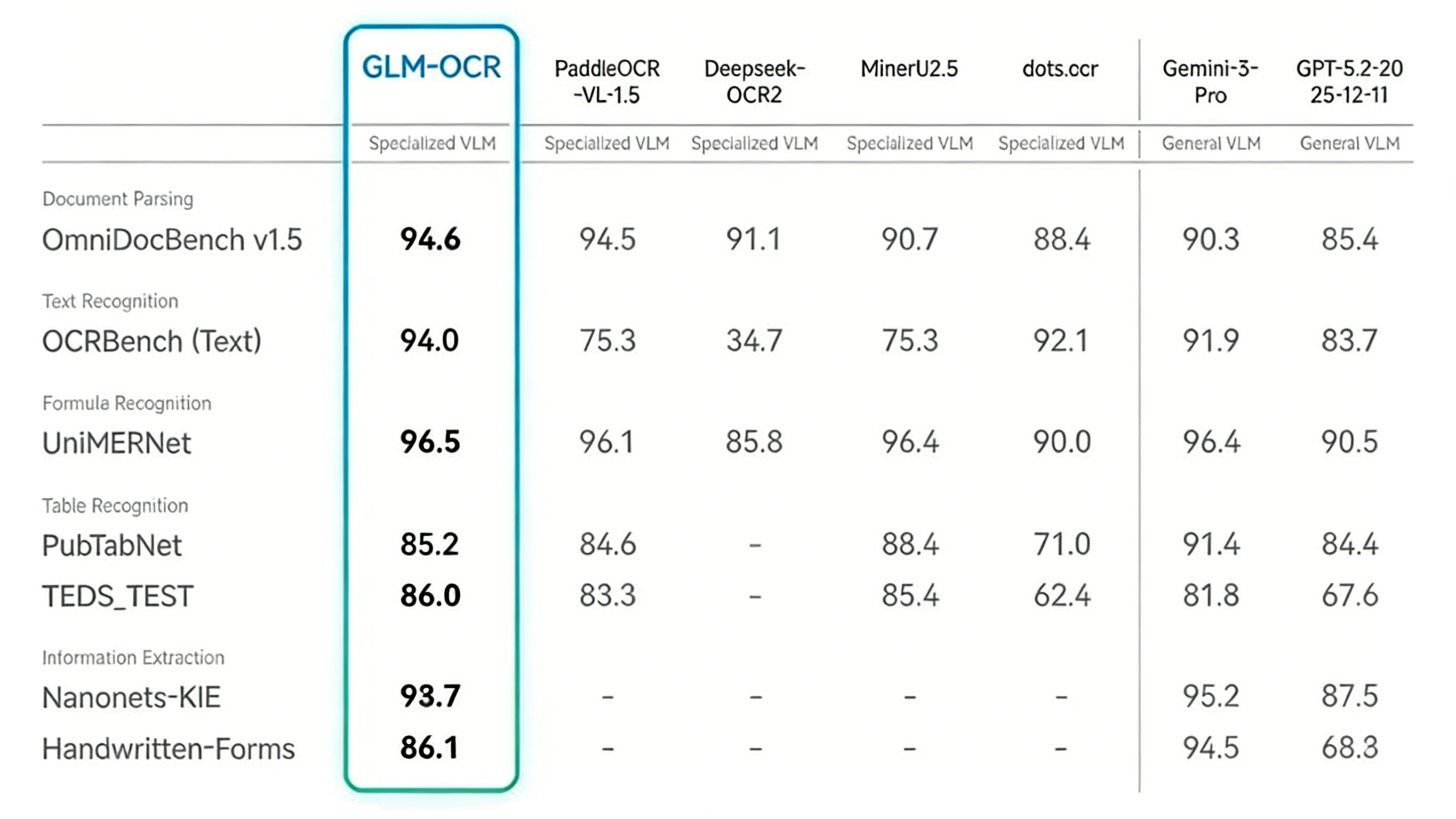
一个轻量模型做到顶级性能,这本身就是对行业规则的一次颠覆。它证明了一件事:做好OCR,未必需要巨无霸一样的模型,精巧的设计和针对性的训练同样可以创造奇迹。
03 专治各种“不服”,速度还快得像闪电
光有高分还不够,GLM-OCR真正厉害的是它能解决那些让人抓狂的具体问题。它的设计目标非常明确:专治各种“不服”的疑难杂症。
- 手写体“天书”:医生潦草的处方、学生的手写笔记,它都能努力看明白。
- 复杂表格“迷宫”:无论是合并单元格、还是跨页表格,它都能理清结构,并直接输出成规整的HTML代码,轻松变网页。
- 印章和文字“打架”:发票上红色的盖章压住了文字,它也能把下面的信息准确提取出来。
- 代码截图“秒变文本”:程序员截了一张代码图,它能高保真地还原成可复制的代码文本。

更让人省心的是,它处理这些复杂任务的速度飞快。根据官方测试数据,它处理PDF文档的吞吐量可以达到 1.86页/秒。也就是说,你喝一口水的功夫,它已经帮你处理好了好几页文件。而且因为它体量小,支持vLLM、Ollama等主流推理框架,用普通的电脑甚至手机就能部署起来,不用非得买昂贵的专业显卡。
04 从“用不起”到“随便用”,价格直接“打骨折”
如果说高性能是“矛”,那么GLM-OCR的低成本就是击穿市场的“盾”。它通过智谱开放平台提供API服务,价格是 0.2元/百万Tokens。
这个概念可能有点抽象,我们算笔账:官方有资料称,大约1元人民币就可以处理2000张A4扫描件或者200份10页的简单PDF。相比动辄按页数或调用次数高价收费的传统商业OCR方案,这个成本可能只有它们的十分之一甚至更低。对企业来说,这意味着原本因为成本问题而无法自动化的海量纸质档案数字化工作,现在可以轻松提上日程了。
05 开源开放,携手国产硬件“发布即可用”
GLM-OCR的另一个关键选择是“开源”。这意味着任何开发者都可以免费获取它的全部代码,根据自己的需要进行研究、修改和部署。这一步棋,极大地降低了企业和开发者的使用门槛和技术锁定风险。
它的出现,也搅动了整个OCR市场的格局。相比于老牌但力不从心的Tesseract、PaddleOCR,它在复杂场景下的准确率有了质的飞跃。相比于同期开源的另一个明星模型DeepSeek-OCR-2,GLM-OCR以更小的参数(0.9B vs 2B)、在综合性榜单上取得了顶级成绩,形成了差异化竞争。
更值得关注的是其生态拓展。就在发布当天,国产GPU厂商沐曦就宣布,其曦云系列GPU已经完成了与GLM-OCR的“Day 0适配”。这展现了一个强大的趋势:优秀的国产软件模型,正在和国产硬件算力快速融合,构建自主可控的技术生态,实现“发布即能用”。
06 从“识别工具”到“智能文档助手”
GLM-OCR的价值远不止于把图片变文字。它能将表格直接转为HTML,把票据信息提取为规整的JSON数据,这相当于给原始文档数据打上了智能标签。
这使得它能无缝嵌入到更高级的业务流程中。例如,它可以成为企业“智能文档中枢”的起点:自动处理所有进项的发票和合同,提取关键信息后直接进入财务或法务系统。它生成的结构化结果,也能为当下热门的RAG(检索增强生成)系统提供高质量的知识原料,让AI在准确理解公司内部文档的基础上,给出更靠谱的回答和建议。
总结来说,GLM-OCR就像一位突然出现的“全能型助理”。它视力顶尖,能看懂最乱的文档;它效率超高,处理速度飞快;它工资要求极低,成本近乎“白菜价”;而且它带着完整的工具箱(开源代码)入职,允许你随意调整。它的出现,或许正标志着文档处理从一项昂贵、专业的外包服务,转变为一项人人可及、轻松嵌入业务的基础设施。当识别文字不再成为障碍,我们或许才能真正开始思考,如何利用这些被释放出来的信息创造更大的价值。
