
本地MD文档让AI获得永久记忆,行业规则即将改写!


深夜,一位开发者盯着屏幕上与AI助手的对话历史陷入沉思——过去三个月的项目细节、技术决策和用户偏好,都散落在无法检索的一次次对话中。他意识到,这个看似聪明的AI,其实患着严重的“数字失忆症”。
你是否也曾疑惑,为什么每次和AI聊天,它都像第一次认识你?为什么昨天刚讨论过的项目细节,今天就需要重新解释?这背后是当前AI应用一个根本性缺陷:它们没有真正意义上的记忆。
2026年初,随着Clawdbot(现OpenClaw)将其独特的“基于Markdown文件的记忆系统”公之于众,一个清晰的解决方案浮出水面。这不仅仅是一个技术特性,更可能预示着AI Agent发展的下一个关键转折点——从“瞬时对话工具”向“拥有终身记忆的合作伙伴”演进。而这场演进的核心战场,不在云端,而在每个用户的本地硬盘里。
01 为什么今天的AI总是“健忘”?
要理解这场变革的意义,首先要看清现状无奈。今天的AI记忆系统存在三重困境:
第一重:云端黑箱,你的记忆正在被收集。绝大多数AI服务将你的对话历史、偏好数据存储在它们的服务器上。你使用越多,它们对你的了解越深,但这些记忆完全由服务商控制。你无法导出、无法修改、甚至无法确切知道它们记住了什么。这创造了一种新型依赖——你的数字记忆被托管在别人的地盘上。
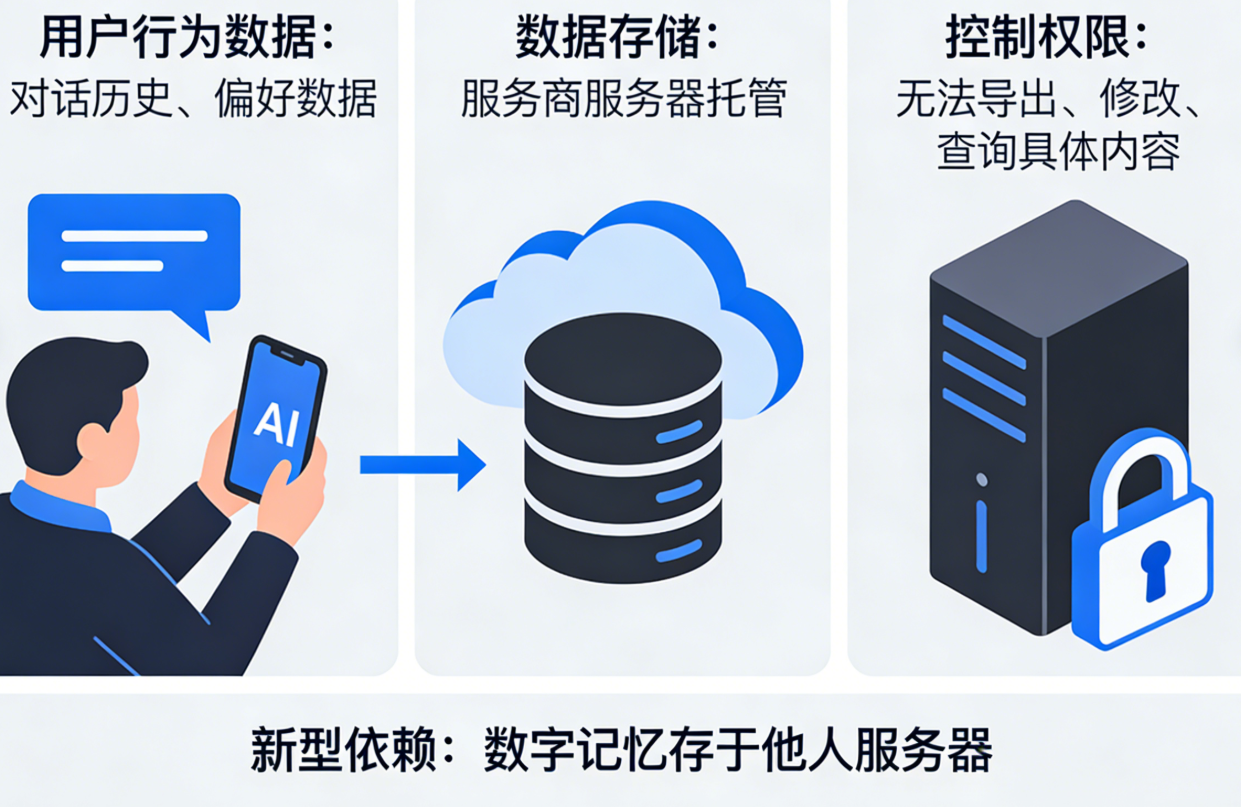
第二重:“7秒”的金鱼记忆。即使服务商“慷慨”地提供了对话历史功能,这些记忆也受限于模型的“上下文窗口”。无论是GPT-5.2的100万Token,还是Claude的20万Token,本质上都是按次付费的短期工作内存。一旦对话超过这个长度,早期的内容就会被丢弃或压缩。想长期记住一个项目的完整演变?那意味着持续的、高昂的API调用成本。
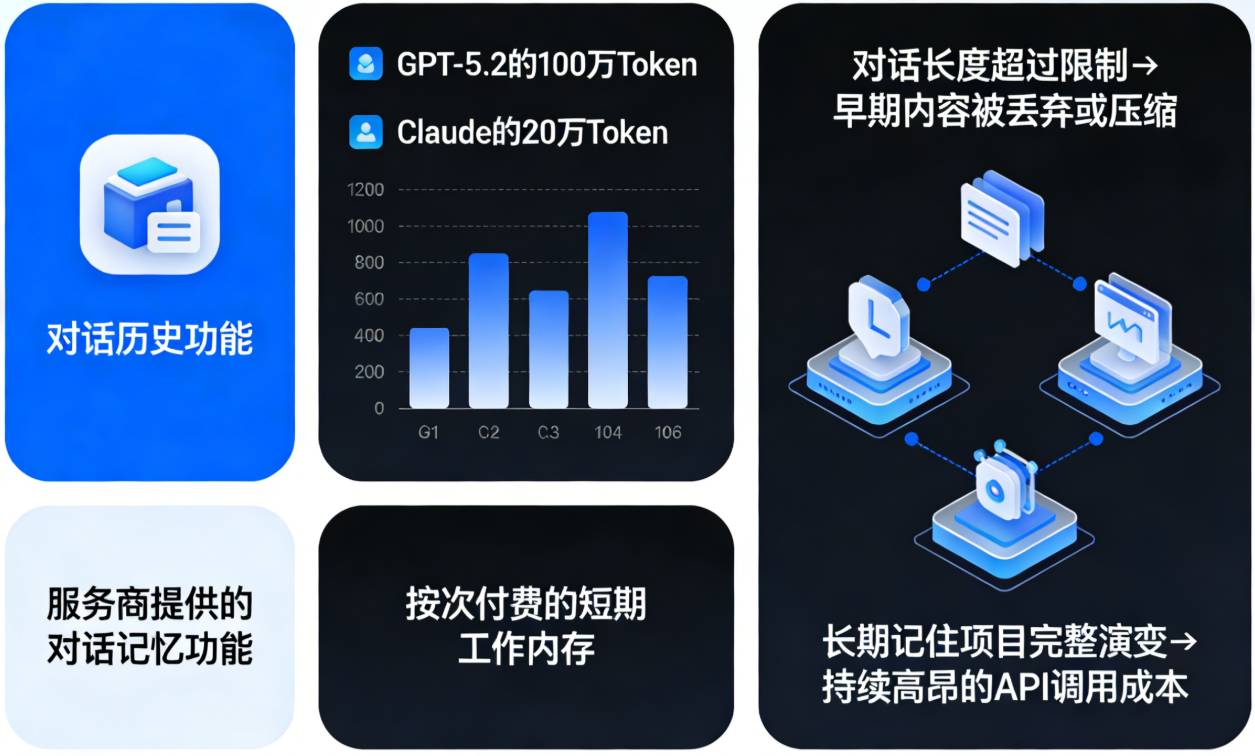
第三重:不可控的“记忆幻觉”。当AI试图从漫长的对话历史中检索信息时,其效果如同在杂乱的阁楼里摸黑寻找一件物品。没有可靠的索引机制,AI可能会“记错”或“捏造”细节,这在专业场景中是致命的。

正是这些痛点,让Clawdbot提出的“记忆即本地Markdown文件”方案显得如此颠覆。它直接挑战了一个行业潜规则:为什么AI的记忆必须由服务商掌控?
02 Clawdbot 把记忆“外置”为普通人可读的文件
Clawdbot的方案简单到令人惊讶:让AI把所有需要记住的东西,都写进你电脑上的Markdown(.md)文件里。这套系统包含两个层次:
- 每日日志 (
memory/2026-01-26.md):就像一个工作笔记,AI随时往里添加碎片信息:“用户今天更喜欢TypeScript”、“下午部署了v2.3版本”。 - 长期记忆库 (
MEMORY.md):经过筛选的重要知识,如“核心用户偏好”、“关键技术决策”、“项目联系人”。

图片来源:博客园
Clawdbot保存记忆的工作流程
这些不是加密的数据库条目,而是任何文本编辑器都能打开、阅读、修改的纯文本文件。你可以手动增删改,AI也会自动更新它们。当AI需要“回忆”时,它通过一套本地索引系统(结合语义向量和关键字搜索)快速从这些文件中找到相关信息。
这意味着,你的AI记忆第一次变得透明、可审计、可移植。你可以把MEMORY.md文件拷贝到另一台电脑,你的AI助手就带走了全部“人生经验”;你可以查看它到底记住了什么,并纠正其中的错误。这套系统在GitHub上开源后,迅速获得了大量开发者的关注,因为它解决了一个根本性的信任和可控性问题。
03 为什么“本地化记忆”可能成为下一个标配?
Clawdbot的方案并非孤例,它呼应了多个正在汇聚的趋势信号:
信号一:隐私与主权。欧盟的《人工智能法案》和全球各地收紧的数据法规,使“数据本地化”和“隐私设计”成为产品刚需。将敏感的记忆数据留存在用户本地,而非跨洋过海的云端,能极大地简化合规负担。正如Clawdbot的设计者所言:“不搞那种基于云端、由大公司控制的记忆,而是把所有东西都留在本地,让用户完全掌控自己的上下文和技能。”
信号二:个性化需求的深度化。未来的AI竞争,将越来越转向个性化能力的深度。一个能记住你所有项目细节、编码习惯、沟通偏好的AI,其生产力远超一个每次都要重新介绍的“新手”。本地记忆库使得这种深度个性化可以脱离服务商——即使你更换AI服务,你的记忆文件可以迁移,继续在新平台上发挥作用。
信号三:成本结构的倒逼。长期依赖云端大模型来承载记忆,其成本模型是不可持续的。Clawdbot的方案展示了一条路径:用廉价的本地存储和检索,替代昂贵的大模型上下文。将记忆“卸载”到本地,只在需要时注入相关片段,这能削减90%以上与记忆相关的API成本。
信号四:开发者生态的偏好。开源、透明、可集成、可调试的方案,正在赢得开发者社区的心。MD文件格式是通用、人类可读的,这使得AI记忆能够无缝接入现有的笔记系统(如Obsidian)、知识库和版本控制(Git)。它降低了开发者使用上的门槛。
04 大厂会拥抱还是封杀这种“去中心化记忆”?
如果“本地记忆文件”成为趋势,将对现有AI巨头的商业模式构成挑战。
目前,用户的对话历史和记忆是锁定用户、构建竞争壁垒的核心资产之一。如果记忆可以轻松导出并迁移到竞争对手的平台,那么用户的切换成本将大大降低。可以预见,拥有封闭生态的大厂(如拥有完善云端套件的谷歌、微软)可能缺乏动力主动推动这一标准。
然而,市场压力可能迫使他们做出改变。像Clawdbot这样的开源项目,如果获得足够大的用户基数,就可能形成事实标准。届时,大厂将面临选择:是继续维护封闭的“记忆工厂”,还是兼容开放标准以吸引那些珍视数据主权的用户?一些公司可能采取混合策略:提供基础本地记忆功能,同时通过更高级的云端协同分析服务来创造附加值。
此外,一个开放的“记忆文件格式”标准,可能催生出全新的中间件和工具生态——专门的记忆分析工具、跨平台同步服务、记忆安全加密方案等。这会让整个生态更加繁荣,而非被几家巨头垄断。
05 未来会怎样?
展望未来,如果这一趋势成为现实,我们与AI的交互方式将发生深刻变化:
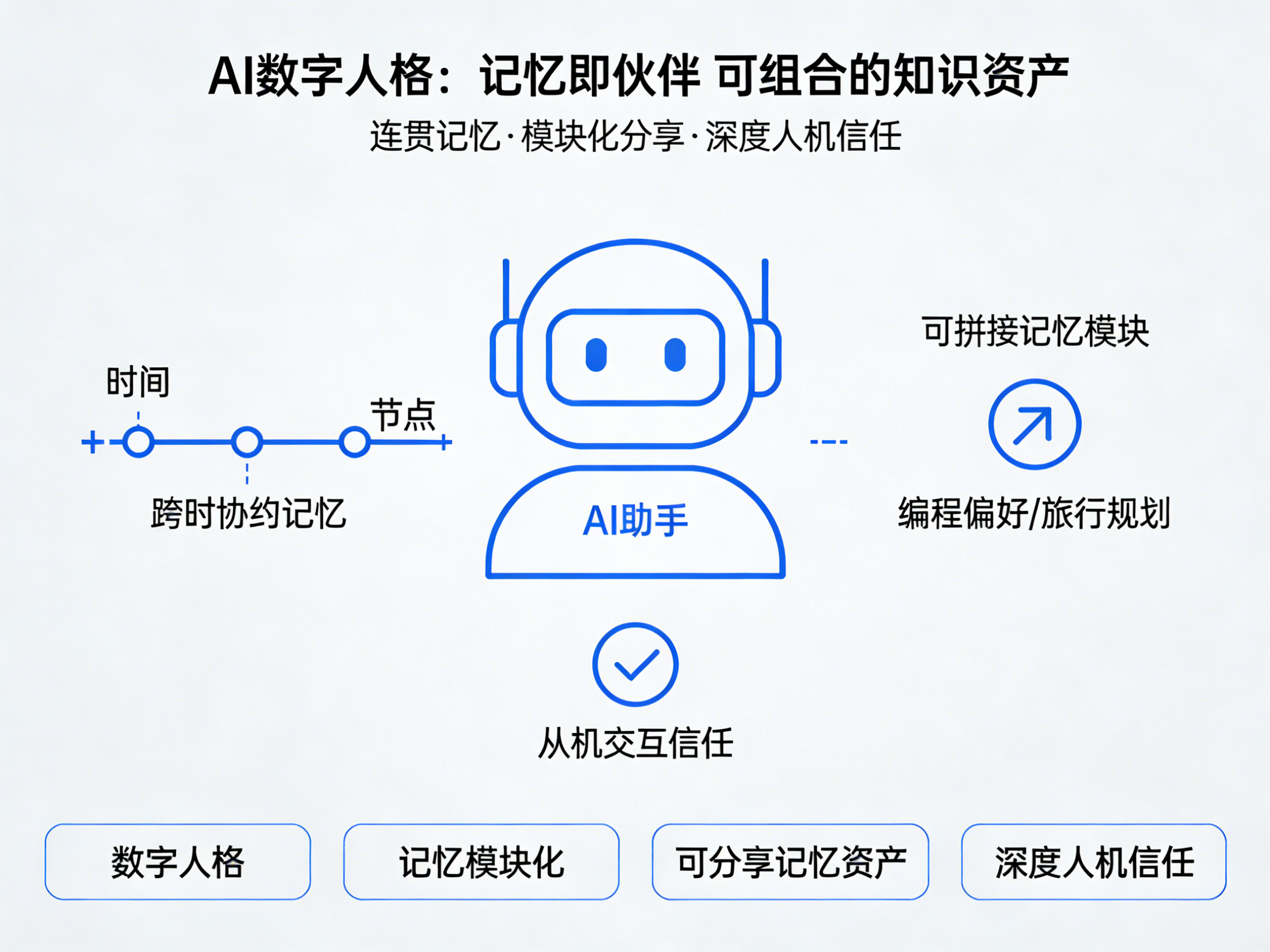
- AI将具备连贯的“数字人格”:你的AI助手会记得一年前你们共同开始的某个业余项目,并在你重新提及它时,无缝接上当时的上下文。它将真正成为一个跨越时间的合作伙伴。
- 记忆将成为可组合、可分享的资产:你可以将“编程偏好记忆”模块分享给同事,将“旅行规划记忆”打包发给家人使用的AI。记忆文件可能成为一种新的、轻量化的知识传播媒介。
- 人机信任将达到新高度:因为你可以随时检查、修正AI的“记忆基础”,你会更愿意委托它处理复杂和长期的任务。你知道它的决策是基于你们共同认可的事实记录。
当然,挑战依然存在:本地存储的安全性问题、不同AI系统间记忆格式的互操作性、海量记忆文件的有效组织等。但Clawdbot已经用极其简洁的MD文件方案,为所有挑战指明了一个可行的起点。
这场记忆革命的本质,是将AI的记忆所有权从云端服务器移交回用户手中的本地文件。它不追求技术的极度复杂,而是追求架构的极度清晰与用户主权。当你的AI助手的全部“人生经验”都能安静地躺在一个你用记事本就能打开的文件夹里时,一种新的关系便建立了:它不再是一个遥不可测的黑箱服务,而是一个真正属于你、与你共同成长的数字伴侣。这或许才是人工智能“个性化”的最终形态。
