
春节AI大战:OpenAI和Anthropic撞车发布,一个让AI造AI,一个给AI开了个16人Team
20分钟,一场教科书级的"火速回击"
2026年2月5日晚上6点40分,Anthropic发布了Claude Opus 4.6。
仅仅20分钟后,晚上7点整,OpenAI就发布了GPT-5.3-Codex。
两份公告,两个破纪录的模型,一个明确无误的信息:AI战争进入了新阶段。
这不是巧合,这是一场教科书级的"火速回击"。
OpenAI宣布GPT-5.3-Codex是公司迄今为止最强大的自主编程模型,并透露了一个象征性里程碑:GPT-5.3-Codex的部分功能是使用模型早期版本自己优化的——这是一种AI辅助的自我改进。
换句话说:AI已经学会了造AI。
二、OpenAI的杀手锏:AI开始"自己生自己"
OpenAI技术文档里有句极具分量的话:"这是我们第一个在创造自己的过程中发挥了关键作用的模型。"
说人话就是:
- AI已经学会了自己写代码
- 自己找Bug
- 甚至开始自己训练下一代的AI了
更关键的是,这种自我进化能力能够直接用跑分数据体现。
在OSWorld-Verified基准测试(模拟人类操作电脑)上,前代模型只有38.2%的准确率,完全不及格。但这次,GPT-5.3-Codex直接跳涨到了64.7%。要知道,人类的平均水平也就72%。
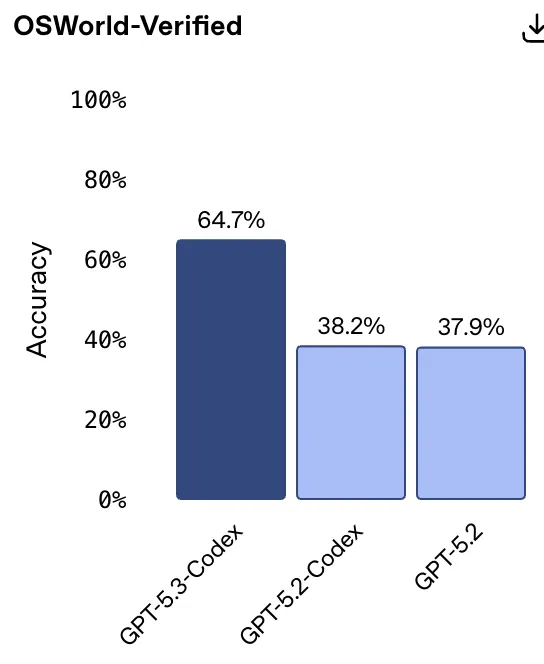
这意味着:AI距离像你一样熟练地甩鼠标、切屏、操作软件,已经很近很近了。
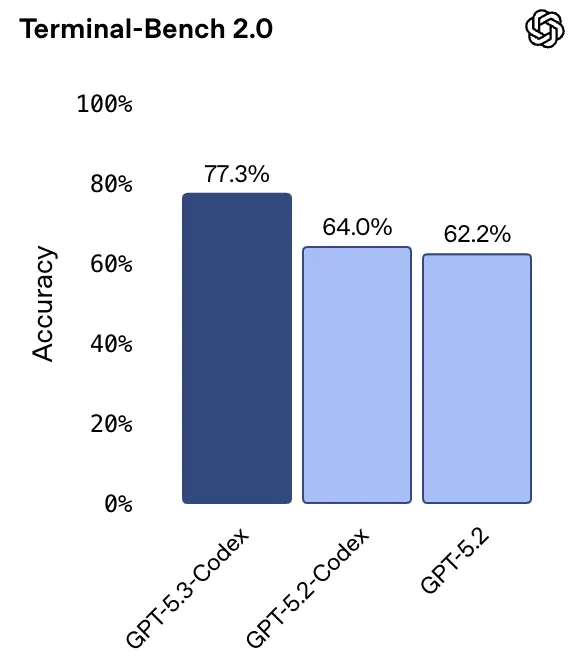
在Terminal-Bench 2.0(命令行操作基准测试)中,它更是拿下了77.3%的高分,把GPT-5.2(62.2%)远远甩在身后。
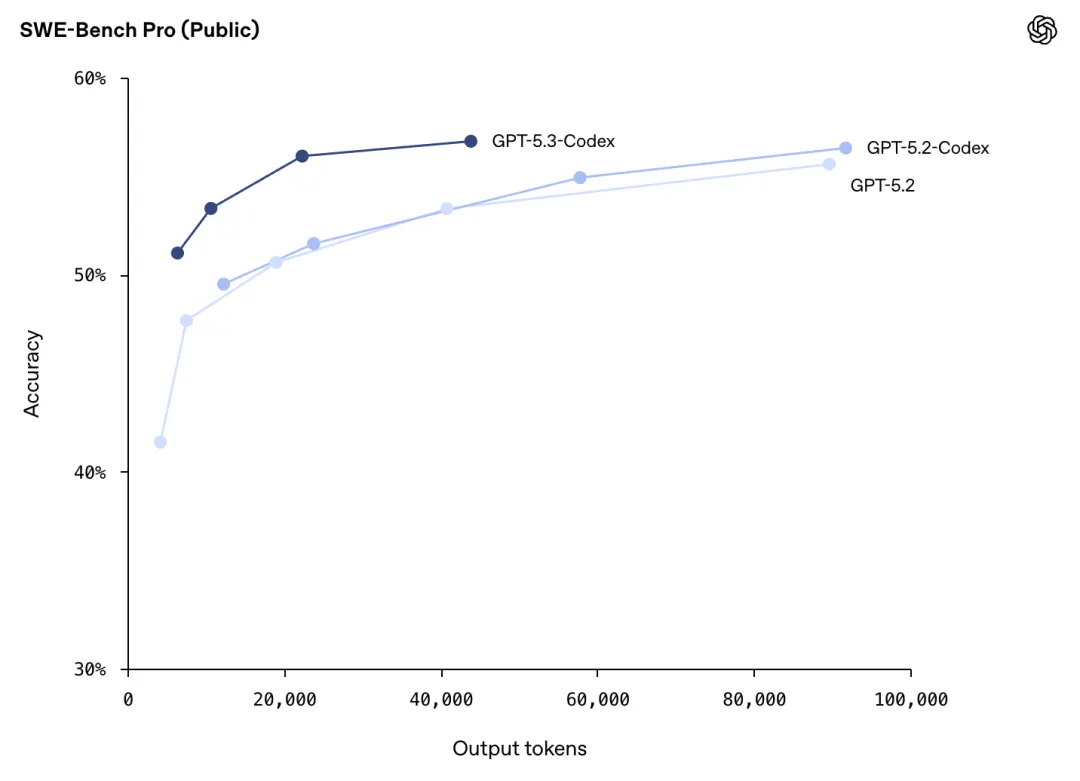
在SWE-Bench Pro基准测试(覆盖四种编程语言,不仅抗污染,还全是真实世界的硬核工程难题)当中,GPT-5.3-Codex也稳定实现SOTA水准,token用量远比以往模型更低。
GPT-5.3-Codex还展示了从零构建的能力:
在OpenAI的测试中,用它在几天时间里从零构建了一款包含多张地图的赛车游戏v2,顺手还搞定了一款管理氧气系统的深海潜水游戏。

还有个有趣的细节:
此前外界盛传OpenAI对英伟达的AI芯片颇有微词,但这次官方博客特地强调:GPT-5.3-Codex的设计、训练和部署都在NVIDIA GB200 NVL72系统上完成。
这一波高情商操作,属实是给足了黄仁勋面子。
三、Claude Opus 4.6:告别"金鱼记忆"的绝地反击
在GPT-5.3-Codex发布的几乎同时,Anthropic也端出了自己的春节大礼包。
核心亮点1:1M上下文窗口
Claude Opus 4.6是Opus系列首个支持100万token上下文窗口的模型,极大扩展了处理和推理大量文档集合的能力。实际上,它现在可以一次性摄入相当于多本书的内容,而不会出现性能崩溃。
这意味着什么?
你可以把几百页的财报、几十万字的代码库直接扔给它,它不仅能读完,还能精准地保存和定位上下文细节,告诉你第342页脚注里的那个数字有问题。
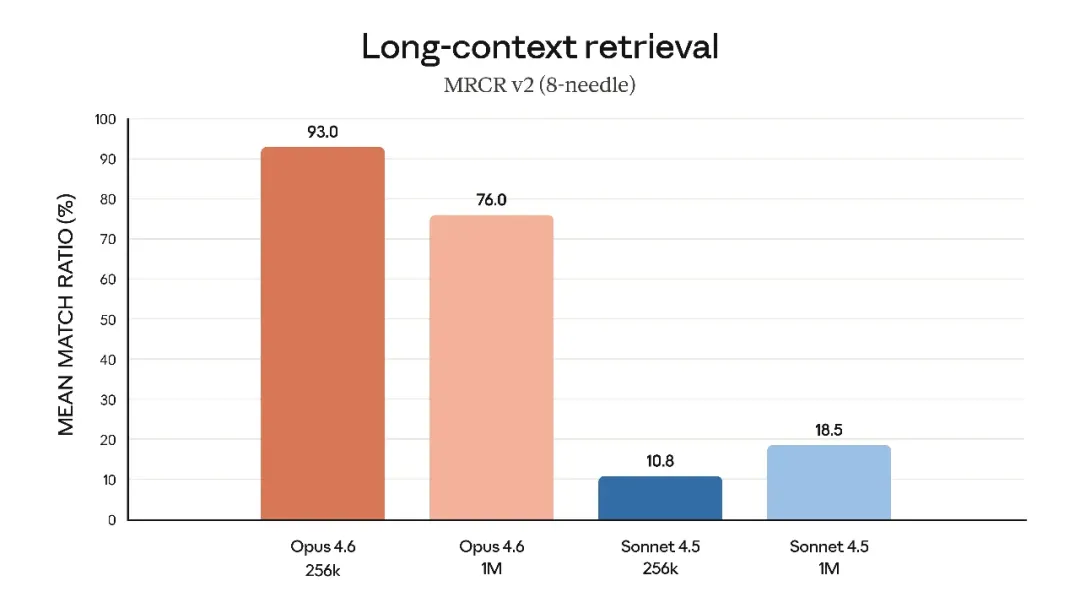
在MRCR v2(长文本大海捞针)测试中,Claude Opus 4.6的召回率高达76%。作为对比,上一代Sonnet 4.5只有惨不忍睹的18.5%。
从某种程度上说,这是一个从基本不可用到高可靠的质变。
核心亮点2:智商碾压
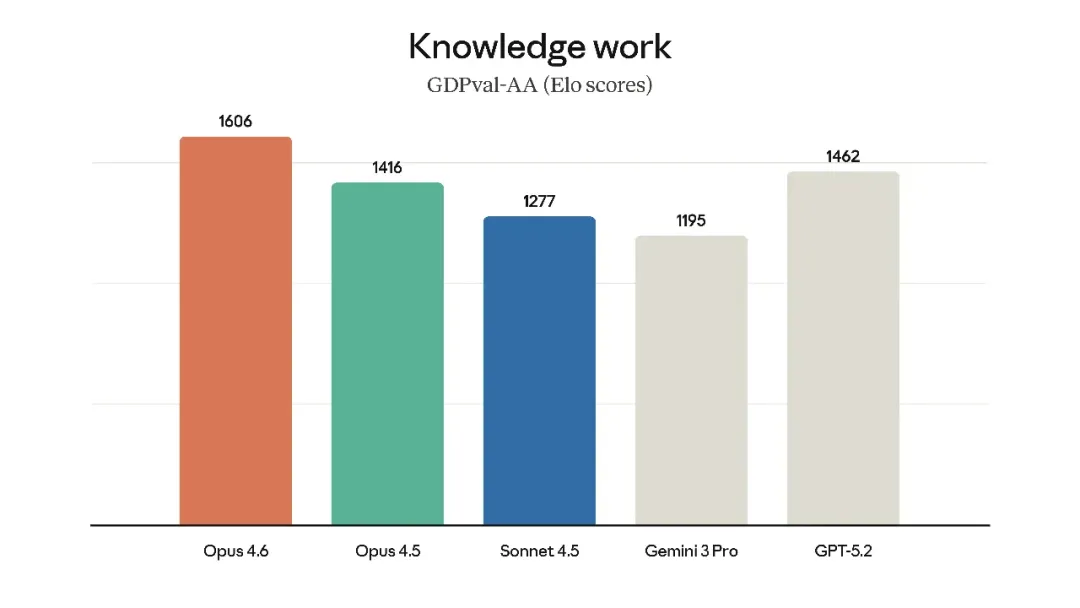
在GDPval-AA(针对金融、法律等高经济价值任务的评估)中,Opus 4.6的Elo得分比业界第二(OpenAI的GPT-5.2)高出了整整144分。
在复杂的多学科推理测试Humanity's Last Exam中,它领先所有前沿模型。
换言之:如果你要处理复杂的商业决策、法律文书或金融分析,Claude是目前唯一的优秀选择。
核心亮点3:Agent Teams(智能体团队)
Anthropic在Claude Code中推出了实验性的Agent Teams功能:你可以指定一个Claude Session担任Team Lead(组长),它不干脏活累活,专门负责拆解任务、分配工单、合并代码;其他的Session则是队友(Teammates),各自领任务去干。
这有什么用?
Rakuten部署了这一功能,看着它自主管理跨6个代码库的50人组织,一天之内关闭了13个issue。
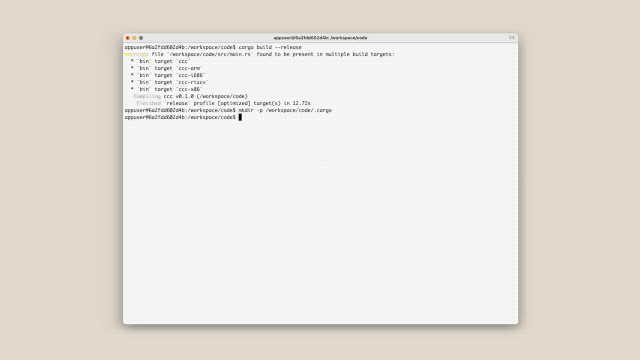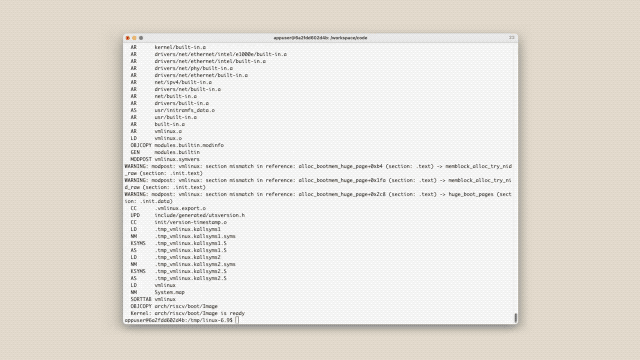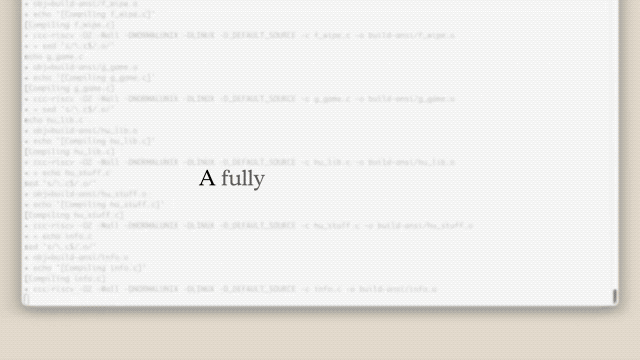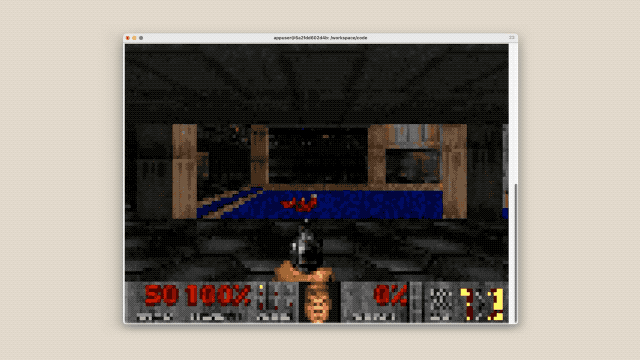
为了展示Opus 4.6的极限,Anthropic研究员Nicholas Carlini做了个疯狂的实验:充值了2万美元的API额度,让16个Claude Opus 4.6组成一个"全自动软件开发团队"。结果在短短两周内,这群AI自主进行了2000多个编程会话,从零手写了一个10万行代码的C语言编译器(基于Rust)。
这个AI写的编译器,还成功编译了Linux 6.9内核,甚至跑通了Doom游戏。
四、一个是激进天才,一个是靠谱老牛
知名AI评测人Dan Shipper在第一时间搞了个"盲测"(Vibe Check),他的评价非常精准:
Claude Opus 4.6是"高上限,高方差"(High Ceiling, High Variance)。
它像是一个才华横溢但偶尔跳脱的天才。在测试中,它直接解决了一个让iOS团队卡了两个月的功能难题。
但它偶尔也会"过度自信",一本正经地胡说八道。
GPT-5.3-Codex则是"高可靠,低方差"(High Reliability, Low Variance)。
它像是一个经验丰富、绝不掉链子的资深工程师。推理速度提升25%,几乎不犯低级错误,稳健得让人心安。
虽然在创造性任务上略逊一筹,但在日常的Coding和运维任务中,它是最高效的老黄牛。
五、这场"撞车"背后的真相
真相1:春节AI大战,先从硅谷开打
Anthropic在2月5日发布Opus 4.6,仅仅3天前,OpenAI刚刚发布了Codex AI编程系统的新桌面应用。
这个时间点的选择,绝非偶然。
两家公司都将在超级碗期间播放竞争性广告,这标志着两家领先AI实验室之间市场竞争的激烈程度。
真相2:AI正在从"工具"变成"员工"
AI正在从"你咨询的工具"毕业为"你委派工作的同事"。问题不是AI是否会做知识工作,而是哪个AI能为你的具体需求做得最好。
比起选择哪款模型,更重要的是:
当ChatGPT可以自主修Bug甚至操作你的终端,当Claude可以一次性吞吐海量文档并精准定位细节时,Prompt Engineering(提示词工程)的重要性正在下降,而Agent Management(智能体管理)的能力开始浮出水面。
我们不再需要像教小学生一样,把指令拆解得碎碎念。相反,我们需要做的,是学会如何以管理者的身份,去定义目标、审核结果、以及决定在什么时候,把什么任务交给哪位AI员工。
六、结语:2026年的新职场
企业平均LLM支出在2025年达到700万美元(比2024年的250万美元增长180%),预计2026年将达到1160万美元。
根据Andreessen Horowitz最近的调查,44%的企业现在在生产环境中使用Anthropic——而2024年3月这一比例几乎为零——而OpenAI仍是使用最广泛的AI提供商,截至2026年1月有77%的受访公司在生产环境中使用它。
这就是2026年的新职场:
你的团队里混入了一群硅基天才,而你是唯一的碳基老板。
