
拒绝人肉纠错!谷歌Agentic Vision清场:AI学会自己打假,把真相喂你嘴里
如果你雇佣了一名身价百万的资深精算师,请他审计一份关乎企业生死的建筑蓝图或财务报表。然而,这位精算师仅在离图纸三米远的地方“扫视”一眼,然后就信誓旦旦地告诉你:“左下角的承重梁参数没问题。”
你敢签这个字吗?
这就是当前多模态大模型(LMM)在商业应用中面临的尴尬真相。无论是OpenAI的GPT-4o还是之前的Gemini系列,在处理视觉信息时,本质上都在玩一场高级的猜谜游戏。它们通过单次前向传播(Single Pass)将整张图片吞入,如果图片分辨率过高,细节就会在压缩中丢失。面对模糊的像素点,AI不会诚实地认错,而是会根据概率分布脑补出一个错误的数字。这种现象,在工程、医疗、金融审计等容错率为零的领域,被称为“视觉幻觉的灾难”。
近日,谷歌在 Gemini 3 Flash 中悄然上线的 Agentic Vision(代理视觉) 功能,标志着AI视觉从印象派向实证派的决定性跨越。它不再让AI坐着空想,而是给了它一副放大镜和一台计算器,让它学会了“先调查,后发言”。
为什么身价亿万的视觉AI总在细节上翻车?
此前,市场对AI视觉的认知大多停留在社交级语义的调情阶段——它能对着一张落日余晖感叹意境深远,或是在识图百科里准确报出宠物的品种。但在需要赌上真金白银的商业实战中,这种只能看个大概的直觉式理解,与真正能落地的生产力之间,隔着一道名为“精确性”的天堑。
首先是感知维度的降级。为了维持运行效率,高精度图纸在进入AI内核前会被强制压缩。这就好比让一个视力1.5的专家戴上一副800度的近视镜去读报纸,无论大脑多聪明,物理层面的“视觉近视”决定了输出结果必然跑偏。
其次是一次性博弈的逻辑缺陷。传统模型看图是单向的,它没有“反复推敲”的机制。在人类专家的工作流中,看不清会凑近看,算不准会重算,但AI以往只会被动接受那一组被压缩后的像素点。在商业逻辑中,这种缺乏纠错链条的决策模式,充其量只是个高阶版的识图搜索,远未触及工业生产的痛点。
深度解构 Agentic Vision:引入外部逻辑脑,用代码解剖像素
要领略 Agentic Vision 的革命性,可以理解为谷歌给 Gemini 3 Flash 配备了Python私人助手。AI不再是孤军奋战,它拥有了操作工具的能力。这一过程被定义为 思考-行动-观察(Think-Act-Observe) 的循环。
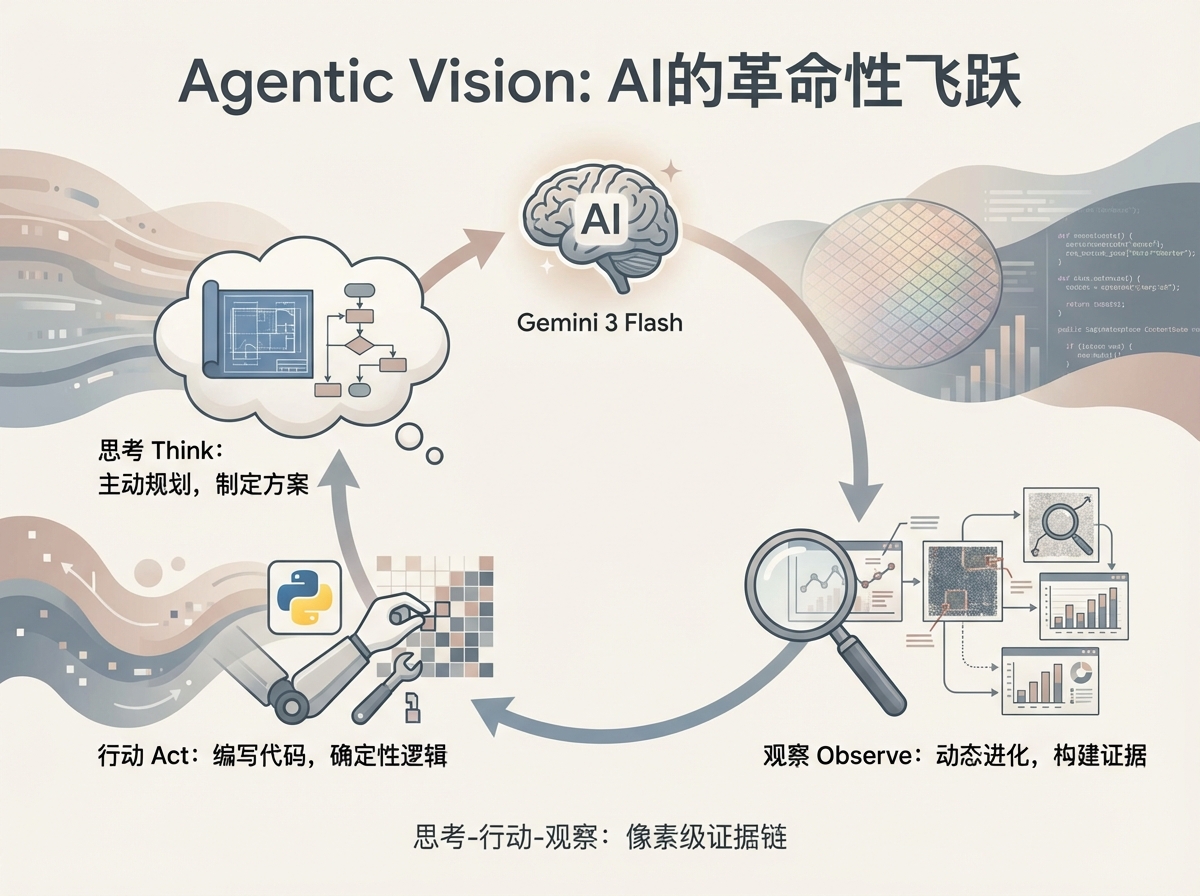
1. 思考:从单纯回馈到主动规划
当用户上传一张密密麻麻的半导体晶圆检测图并询问是否存在缺陷时,Agentic Vision 不再试图直接给出答案。模型的“思考”模块会首先自省:“这张图信息密度太高,全图观察无法确认细节。”
随后,它会制定一个多步骤的探测方案。它会识别出图像中可能有问题的坐标区域,并决定:“我需要对A1、B4区域进行三倍放大,并对比其边缘灰度值。”这种从“给答案”到“定方案”的转变,是代理思维的核心。
2. 行动:用确定性逻辑终结“脑补”
这是该技术最硬核的部分。Gemini 3 Flash 会当场编写并运行 Python 代码。AI不再是用“感觉”去理解图像,而是调用代码库(如OpenCV或PIL)对原始图像进行精准的数学处理。
- 物理级精准裁剪: 如果全图中一个微小的零件看不清,AI会通过代码直接截取原始图像中那 1% 面积的未压缩像素,并作为新图再次输入。这意味着 AI 看到的不再是模糊的马赛克,而是原汁原味的、连划痕纹理都清晰可见的工业原图。
- 确定性逻辑替代概率预测: 面对复杂财报,AI 不再靠“看”来猜数字,而是写代码提取像素坐标,在 Python 的确定性环境里完成四则运算。1.01 乘 1.05 在这里永远等于 1.0605,不再会有神经网络里那种“大概是1.06”的模糊推测。通过代码,AI将模糊的视觉信号转化为了严谨的数学事实。
3. 观察:构建动态进化的证据链
代码执行后产生的所有结果(比如放大的局部图、标注了序号的检测图、或者是生成的统计图表)都会被重新喂回模型的上下文窗口。此时,模型面对的是一套由它自己亲自采集的高清证据链。如果第一轮取证仍有疑点,AI 会发起第二轮、第三轮调查。这种“基于证据、多次取证”的循环,让最终给出的每一个结论都挂载着对应的、可被人类复核的像素级证据。
5%-10%的跨越,是实验室与工业界的生与死
谷歌在技术报告中给出的数据非常惊人:启用代码执行的 Agentic Vision,在大多数视觉基准测试中带来了 5% 到 10% 的质量提升。在商业世界,这绝非一个小数字,它往往代表着产品能否跨过“商用门槛”。为了验证这种提升在现实生意中意味着什么,谷歌重点展示了两个源自真实合作伙伴与官方演示的应用样本。
1. 建筑蓝图的法医级穿透:在万倍缩放中拦截返工风险
在建筑工程领域,有一家名为 PlanCheckSolver 的平台。它的核心业务是利用 AI 自动审核海量的建筑设计图,确保每一处细节都符合严苛的消防与结构规范。 过去,这种审核非常依赖人工,因为 AI 常因为看不清图纸中细如发丝的标注文字而导致审计失败。 借助 Agentic Vision,AI 会主动生成 Python 代码,将屋顶边缘、承重连接点等敏感区域切成超高清的“切片”进行深度过筛。
启用这种取证式的检查流后,其合规检查的准确率提升了 5%。对于大型工程项目,这 5% 的精度跨越,意味着在动工前拦截掉数百万美元的返工成本。
2. 像素级计数与数据处理的工业重塑
数清照片里的物件听起来简单,但在精密物流盘点中,这是极高难度的任务。为了防止漏算,Gemini 3 Flash 会编写代码在图像上进行“标注(Annotating)”,在每个检测出的零件上画框、编号,形成一张视觉草稿本。 此外,在处理高密度的行业性能图表时,AI 不再只是读数。谷歌的演示显示,模型能瞬间编写 Matplotlib 代码,将提取出的原始数值生成一张全新的对比图。
这意味着 AI 完成了从感知到加工再到决策支持的全链路闭环。它不再只是读报员,而是成为了能够提供证据支撑的分析师。
为什么说视觉AI的大模型时代正在谢幕?
谷歌选择在 Gemini 3 Flash 这个定位“快、准、轻”的模型上大规模落地 Agentic Vision,背后隐藏着深刻的行业洞察和市场趋势变化。
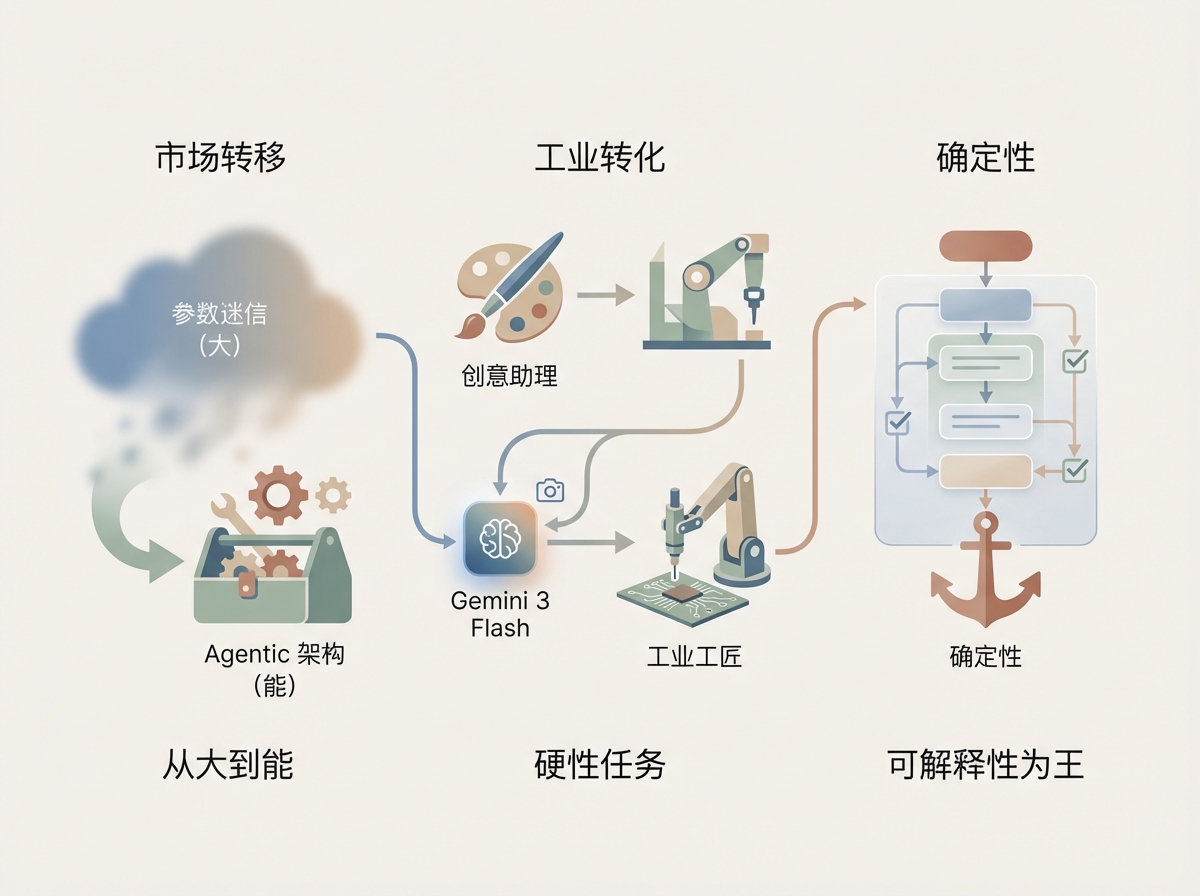
首先,市场正在从追求“大”转向追求“能”。 过去一年,行业迷信参数量,认为只要模型够大,就能解决一切问题。但谷歌证明了,给一个中轻量级的模型配备工具箱和工作流,其表现可以轻易碾压那些只会坐而论道的巨型模型。这种Agentic(代理化)的架构,极大地降低了企业的推理成本。Gemini 3 Flash 本身就以低成本著称,配合这种高效的视觉循环,它让大规模自动化图像审计变得在经济上“有利可图”。
其次,AI 正从创意助理转型为工业工匠。 之前的视觉 AI 主要用于生成漂亮的图片或者写简单的描述,那属于软性任务。而 Agentic Vision 攻克的是硬性任务——需要精确读数、需要逻辑闭环、需要确定性结果。这种转变意味着 AI 终于准备好进入制造业、法律合规、精密医疗检测等那些以前它“进不去”的深水区。
最后,确定性将成为 AI 溢价的核心。 在未来的 AI 采购中,首席信息官(CIO)们关心的不再是“这个 AI 有多聪明”,而是“这个 AI 的每一步操作是否有据可查”。Agentic Vision 这种“感知归感知、计算归代码”的分离逻辑,顺应了人类对 AI 可解释性和确定性的迫切需求。
结语:当 AI 学会了三思而后行
诺贝尔经济学奖得主丹尼尔·卡尼曼在《思考,快与慢》中提到,人类有依靠直觉的“系统 1”和依赖逻辑的“系统 2”。
过去的视觉大模型,一直是一个只有“系统 1”的冲动型选手:它反应极快,却经常因为直觉而犯错。谷歌的 Agentic Vision,本质上是为 AI 强行开启了“系统 2”。它让 Gemini 3 Flash 学会了在给出答案前,先停下来,想一想,拿起工具去验证一下。
对于开发者和商业领袖而言,这是一个明确的信号:AI 视觉的暴力计算时代已经过去,一个由“工具、逻辑和闭环”驱动的代理化时代已经到来。未来的胜出者,不一定是那个眼睛最大的模型,但一定是那个最会使用放大镜和计算器的模型。
这种从“快思考”向“慢思考”的进化,看似终结了 AI 睁眼说瞎话的时代,却也带来了一个细思极恐的逻辑陷阱:如果 AI 在第一眼观察时就产生了偏差,而随后用来取证的代码又是它自己编写的,这是否会变成一种更难察觉的“自圆其说”?
这就好比一个学生在考卷上写错了答案,但他又获准自己编写一套评分标准来给自己批改,结果可能依然是满分,但真相却被掩盖在了看似严谨的程序之下。
对于决策者而言,Agentic Vision 的落地绝不意味着人类可以从此当甩手掌柜。相反,商业竞争的焦距已经发生了质变:以前我们比的是谁家 AI 的眼力更好,以后比的则是谁更懂如何“审计”AI 的逻辑过程。在机器学会自我取证的时代,人类最核心的财富,依然是那份不可替代的、代表终审权的怀疑精神。AI 负责提供证据,而人类必须守住最后那枚代表“定案”的印章。
