

OpenAI 与 Anthropic 同日亮剑,字节与 DeepSeek 紧随其后:这个 2 月,AI 杀疯了



2026 年 2 月,注定将被载入人工智能的史册。
仅仅过去 10 天,Anthropic、OpenAI、字节跳动等巨头纷纷投下重磅炸弹,发布的模型质量之高,让众多产品经理感到窒息。
2 月 5 日,Claude Opus 4.6 和 GPT-5.3-Codex 前后脚发布,相差不到一小时。紧接着,字节跳动的 Seedance 2.0 在推特刷屏。而传闻中将在 2 月 17 日亮相的 DeepSeek v4,更是让无数竞争对手睡不着觉。
2026 年 2 月有望成为人工智能最非凡的一个月。
已发布:
- Anthropic Opus 4.6 ✅
- OpenAI GPT-5.3-Codex ✅
- 字节跳动 Seedance 2.0 ✅
待发布:
- 谷歌 Gemini 3 Pro GA(预计发布日期:2 月 10 日左右)
- 字节跳动 Seedream 5.0(预计 2 月中旬发布)
- Sonnet 5(预计二月中旬)
- GPT-5.3(预计 2 月 12 日左右发布)
- Qwen 3.5(预计 2 月中旬)
- GLM 5(预计约 2 月 15 日发布)
- DeepSeek v4(预计 2 月 17 日左右发布)
- Grok 4.20(预计 2 月下旬发布)
- Meta Avocado(预计二月/上半年,具体时间待定)
一、双雄对决
这个 2 月的一开场,就是 Anthropic 和 OpenAI 这对宿敌的贴身肉搏。
1. Anthropic

2 月 5 日,Anthropic 发布的 Claude Opus 4.6,祭出了一个名为智能体战队的概念。
在过去,我们使用 AI 是给一个指令,AI 给一个回复。但 Opus 4.6 不同,它可以瞬间分裂出多个子 Agent,有的负责查资料,有的负责写代码,有的负责润色文档,最后由主脑汇总。
Anthropic 赌的是复杂任务流,它想做企业的外包团队。如果你是一个 CTO,你是愿意招 10 个初级程序员,还是愿意租用一个永远在线、永不疲倦、且配合默契的 AI 战队?
Opus 4.6 就是那个团队,它把活干得漂亮、安全、稳定。
2. OpenAI
仅仅一小时后,OpenAI 用 GPT-5.3-Codex 予以回击。
这款模型的发布,揭示了 OpenAI 自我进化的野心。内部人士透露,GPT-5.3-Codex 被用来调试自己的训练代码。在 OpenAI,AI 已经开始参与到自身的迭代中去了。
再通过与 Cursor 和 GitHub Copilot 的深度绑定,OpenAI 试图把全球数千万开发者锁死在自己的生态里。Codex 就是那个执行者。它自己就能把代码写完、测试跑通、环境部署好,一个全能的独行侠。

GPT-5.3-Codex 生成的游戏演示
二、字节跳动的突围
就在硅谷双雄打得难解难分时,字节跳动的 Seedance 2.0 震撼全场。
在推特上,Seedance 2.0 的演示视频引发了病毒式传播。无论是短剧还是漫剧,Seedance 2.0 都展示出了颠覆行业的恐怖潜力。
为什么?因为抖音背靠百亿数据。
字节跳动不需要做通用的 GPT,它只需要在视频领域做到极致。依托抖音和剪映的视频生态,Seedance 2.0 将成为无数创作者手中的自动工厂。

Seedance 2.0 生成的同人动画
三、期待中的中国力量与马斯克
如果说 2 月初的双雄对决和字节跳动的视频突围只是序幕,那么接下来的两周,才是这场战役的白热化阶段。
1. DeepSeek v4

最让国外感到不安的变量,来自中国。
传闻将于 2 月 17 日发布的 DeepSeek v4,正在打破西方对开源模型的固有认知。在过去一年里,开源意味着便宜但平庸,闭源意味着昂贵但顶尖。但泄露的测试数据显示,DeepSeek v4 在复杂编程任务上的得分可能突破了 90%,这一数据直接威胁到了 Claude Opus 4.6 和 GPT-5.3-Codex。
DeepSeek v4 的架构创新让国外胆寒,Engram 记忆技术。
传统模型面对超长上下文时,往往会出现"迷失中间"的现象,推理效率也会随着长度增加而指数级下降。而 Engram 架构通过优化记忆检索机制,不仅能实现了 100 万 token 级别的超长上下文,还能保证在处理海量信息时的准确率和推理效率。
这让 DeepSeek 不再只是性价比,它正在试图成为性能上的新王。如果它能以低成本提供超越 GPT-5 级别的代码和推理能力,那么全球企业级市场的采购逻辑将被彻底重写。
2. GPT-5.3

OpenAI 显然不会坐视不管。Codex 只是前菜,代号为 Garlic 的 GPT-5.3 通用版预计将在 2 月 12 日左右登场。
与专注于编程的 Codex 不同,GPT-5.3 旨在实现通用推理能力的跃迁。据内部消息,该模型采用了更高密度的训练技术,意在更小的参数规模下实现接近 GPT-6 的能力。其核心升级在于输出端的释放,并支持高达 128K 的输出长度。
这是一个质的飞跃。目前的模型在生成长篇小说或完整代码库时往往会中断,而 128K 的输出能力让 GPT-5.3 可以一次性生成一本中篇小说或一个复杂的软件系统。此外,它继承并强化了 Codex 的自我改进循环,能够通过自我博弈来提升逻辑链条的严密性。
对于 OpenAI 而言,GPT-5.3 是一场必须打赢的防御战。它需要证明,在 Google 和 Anthropic 的围剿下,自己依然拥有定义"SOTA(当前最佳)"的解释权。
3. Qwen 3.5
Qwen 3.5 在 HuggingFace 泄露
视线转回国内,阿里的 Qwen(千问)3.5 预计将在 2 月中旬发布。
不同于市面上大多数通过"拼接"视觉编码器来实现多模态的模型,Qwen 3.5 主打原生多模态。它不需要额外的适配器,就能直接理解和生成文本、图像、音频和视频。这种架构上的统一,使得模型在处理跨模态复杂任务时的损耗降到了最低。
阿里还准备了 MoE 变体(约 35B 参数)和小参数版本(约 9B 参数),意图非常明显:通过开源策略,将 Qwen 植入从手机端侧到云端集群的每一个角落。Qwen 3.5 的发布,将进一步巩固阿里云在全球开源生态中的地位,挑战 Llama 的霸主地位。
4. Grok 4.20
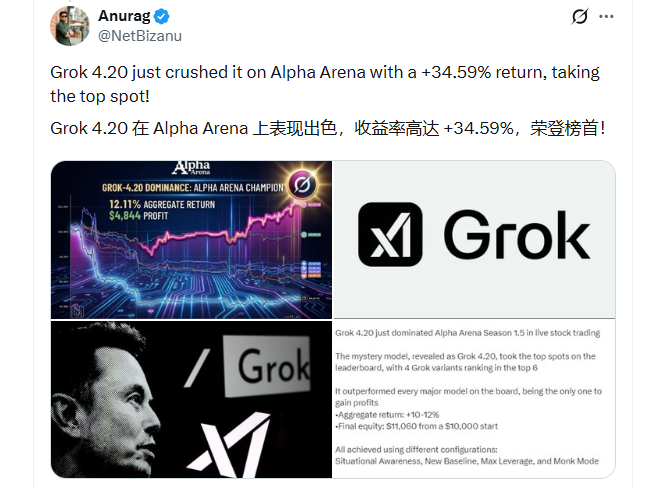
在这一片混战中,马斯克的 xAI 显得特立独行。预计于 2 月下旬发布的 Grok 4.20,剑走偏锋,主打 Real-world Utility(现实世界效用)。
Grok 4.20 已经在真实的预测市场和金融交易中证明自己。预览数据显示,该模型在模拟预测和交易场景中实现了 34% 的回报率,展现出了惊人的现实推理能力和工具调用能力。
Grok 的背靠实时的 X(推特)数据。当其他模型的知识还在停留在 2025 年时,Grok 4.20 能够实时接入全球舆论。对于需要捕捉瞬时热点、进行金融决策或危机公关的用户来说,这种能力是其他任何模型都无法比拟的。
四、结语
2026 年 2 月的下半场,将呈现出一种百家争鸣的态势。
中美之间的差距正在缩小,通用与垂直的路径正在分化。
DeepSeek 的效率、OpenAI 的通用性、Grok 的实时性、Qwen 的原生多模态,每一家公司都在用自己的方式定义 AI 的未来。
在这个拥挤的赛道上,没有一家公司敢说自己拥有绝对的安全距离。技术的迭代周期已经从"年"被压缩到了"周",任何一次落后,都可能意味着在下一个时代的出局。
