
DeepSeek 偷偷更新了!上下文飙到 100 万 token,V4 春节见?

DeepSeek 又搞事情了。
2 月 11 日,多位用户发现 DeepSeek 在网页和 App 端悄悄更新了版本——上下文窗口从原来的 128K 直接跳到了 100 万 token(1M)级别。
这是什么概念?《三体》三部曲加起来 90 万字,现在 DeepSeek 可以一口气读完全集,然后回答你关于三体世界的任何问题。
而这次更新,很可能只是个开胃菜。传闻中的 V4 旗舰模型,预计将在春节期间(2 月中旬)正式发布,带来两项底层架构创新——mHC 和 Engram,直接瞄准中国大模型的算力芯片和内存瓶颈。
100 万 token 有多强?实测《三体》全集
先说这次偷偷上线的更新。
实测发现,DeepSeek 在问答中确认自己现在支持 100 万 token 的上下文,可以一次性处理超长文本。此外,知识库截止时间也更新到了 2025 年 5 月。

不过新版本目前不支持视觉输入,也不具备多模态识别能力——专注做好长文本处理这一件事。
实测:《罪与罚》42 万字,几分钟搞定
提交了超过42万 token 的《罪与罚》小说文档,DeepSeek 可以正常识别和分析文档内容。
这意味着什么?意味着你可以把整本书、完整的研究报告、几十页的法律文件一次性丢给 DeepSeek,让它帮你分析、总结、提炼关键信息——不用再分段处理,不用担心上下文丢失。
100 万 token 在行业里什么水平?
目前能把上下文推到 100 万级别的模型并不多,谷歌的 Gemini 系列和 Anthropic 的 Claude Opus 4.6 已经率先实现。
DeepSeek 这次跟上了第一梯队,而且值得注意的是,它在成本控制上一直比国际主流模型更有优势。100 万 token 的长文本处理,成本会是多少?这个答案可能会让很多人惊喜。
V4 春节见?两大技术创新曝光
这次的 100 万 token 更新,很可能只是为 V4 发布做铺垫。
据科技媒体 The Information 爆料,DeepSeek 将在今年 2 月中旬农历新年期间推出新一代旗舰 AI 模型 DeepSeek V4,将具备更强的写代码能力。

而野村证券在 2 月 10 日发布的研报中指出,V4 不会像去年的 V3 那样引发全球 AI 算力需求恐慌,但它可能通过两项底层架构创新——mHC 和 Engram 技术——进一步降低训练和推理成本,加速中国 AI 价值链创新周期。
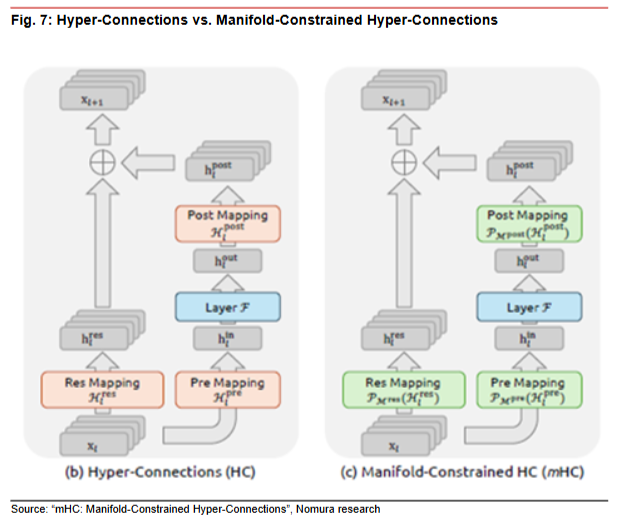
技术一:mHC(流形约束超连接)
全称流形约束超连接,主要解决 Transformer 模型在层数极深时,信息流动的瓶颈和训练不稳定问题。
简单说,它让神经网络层之间的对话更丰富、更灵活,同时通过严苛的数学护栏防止信息被放大或破坏。实验证明,采用 mHC 的模型在数学推理等任务上表现更优。
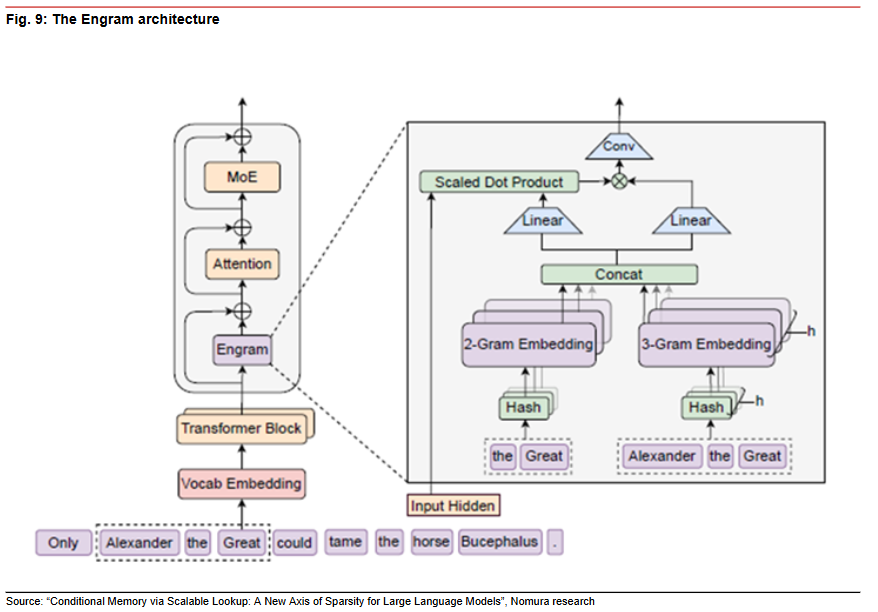
技术二:Engram(条件记忆模块)
这是一个条件记忆模块,设计理念是将记忆与计算解耦。
模型中的静态知识(如实体、固定表达)被专门存储在一个稀疏的内存表中,这个表可以放在廉价的 DRAM 里。当需要推理时,再去快速查找。这释放了昂贵的 GPU 内存(HBM),让其专注于动态计算。
对中国 AI 的战略意义
野村证券指出,这两项技术的结合对中国 AI 发展意义重大:
用更稳定的训练流程(mHC)弥补国产芯片可能存在的不足。
用更聪明的内存调度(Engram)绕过 HBM 容量和带宽的限制。
神秘的 MODEL1,藏在 GitHub 代码里的线索
除了 V4 的传闻,还有一个神秘的新模型代号曝光了——MODEL1。
1 月 21 日,R1 模型发布一周年之际,DeepSeek 官方 GitHub 仓库更新了一系列 FlashMLA 代码。有人用 AI 对全部 114 个代码文件进行分析,发现了一个此前未公开的模型架构标识 MODEL1,共被提及 31 次。
这个 MODEL1 到底是什么?是 V4 的内部代号,还是另一个全新系列?目前没有官方说法,但可以确定的是,DeepSeek 正在同时推进多个模型的研发。
V4 不会引发恐慌,但会加速商业化
野村证券的研报给出了一个明确判断:V4 不会像 V3 那样引发全球 AI 算力需求恐慌。
为什么?
因为全球主要云服务商正全力追逐通用人工智能,资本开支的竞赛远未停歇。V4 的发布不会改变这个大趋势。
但 V4 的真正价值在于:它可能帮助全球大语言模型和 AI 应用企业加速商业化进程,从而缓解日益沉重的资本开支压力。
硬件受益于加速周期
野村认为,V4 最直接的商业影响就是进一步降低大模型的训练与推理成本。这种成本效益的提升将刺激需求,届时中国 AI 硬件公司将受益于加速的投资周期。
软件迎来增值而非被替代
在应用侧,更强大、更高效的 V4 将催生更强大的 AI 智能体。
报告观察到,像阿里通义千问 App 等,已经能够以更自动化的方式执行多步骤任务。这意味着,AI 智能体正从对话工具转型为能处理复杂任务的 AI 助手。
这些能执行多任务的智能体,需要更频繁地与底层大模型交互,这将消耗更多的 Token,进而推高算力需求。因此,模型效能的提升不仅不会杀死软件,反而为领先的软件公司创造了价值。
市场格局变了,一家独大变群雄割据
野村的报告还回顾了 DeepSeek-V3/R1 发布一年后的市场格局。
在 2024 年底,DeepSeek 的两个模型曾占据 OpenRouter 上开源模型 Token 使用量的一半以上。但到了 2025 年下半年,随着更多玩家加入,其市场份额已显著下降。
市场从一家独大走向了群雄割据。这表明,仅凭单一模型的高效,已不足以统治快速演进的开源生态。如今 V4 面临的竞争环境,远比一年前复杂。
从 V3 到 R1,从 128K 到 100 万 token,从 mHC 到 Engram,DeepSeek 的每一次技术突破,都在改变行业对大模型的认知。
去年 V3 的发布,让全球看到了中国在大模型领域的创新能力。今年 V4 的到来,可能会进一步证明:在算力芯片和内存受限的情况下,中国依然可以通过算法创新走出一条自己的路。
100 万 token 的上下文窗口已经上线,V4 预计春节期间发布,MODEL1 在代码里露出端倪——DeepSeek 的动作越来越密集,节奏越来越快。
接下来的故事,会更精彩。
