
蚂蚁开源全模态2.0:一条音轨生成人声+音效+配乐


你是否遇到过这样的AI“偏科生”?——有的能聊得火热,却对图片“脸盲”;有的修图堪称大师,但让它配段语音就立马“失声”;
就在2026年2月11日,蚂蚁集团甩出一张王牌——Ming-flash-omni 2.0,它不仅是业界首个能在同一条音轨里“边说话边放烟花”的AI,更用实测成绩狠狠击碎了“全模态必平庸”的偏见。这场开源,或许正是AI从“多模型缝合”走向“统一智能底座”的转折点。
我们为什么受够了“缝合怪”AI?
今天绝大多数标榜“多模态”的产品,本质上是“模型套娃”——视觉模型负责看,语音模型负责听,生成模型负责画,最后用一段代码把各家的“零件”拧在一起。
这种架构有三个谁都瞒不住的硬伤:
- 一是贵,串联多个专用模型意味着成倍的算力消耗和延迟;
- 二是傻,模态之间是“事后对齐”,比如AI修图时听不懂你想要“悲伤的氛围”;
- 三是脆,任何一个环节掉链子,整个任务就崩盘。
更致命的是,开源社区长期缺乏一个“全能型底座”。Ming-flash-omni 2.0的出现,正是对准了这个空无一物的“无人区”——用一套架构、一套权重,同时把看、听、说、画做到专业级。
和指哪改哪的“图像魔术师”
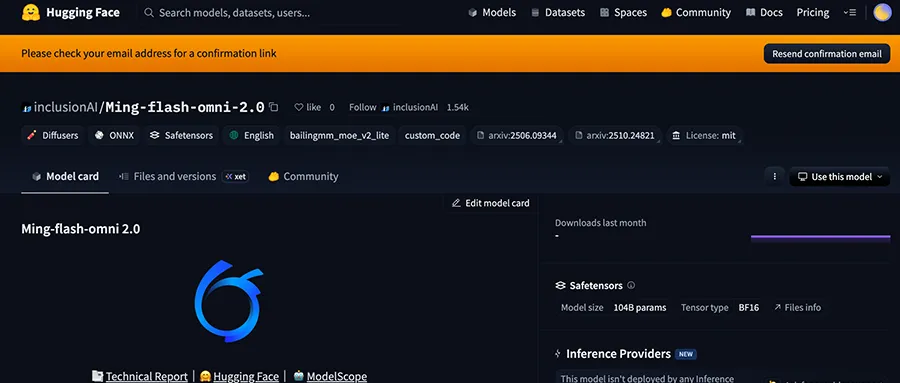
Ming-flash-omni 2.0不是简单的版本号更新,而是一次“感官总动员”。
它的核心能力可以拆成三块“杀手锏”:
1. 视觉百科:
上传一张青铜器的残片,它不仅能认出是“马踏飞燕”,还能像半个考古学家一样给你讲汉代铸造工艺和美学特征-1。这种能力来自亿级细粒度数据+知识图谱对齐——模型不再是被动识别像素,而是主动调用背后的结构化知识,把“像素”翻译成“认知”。
2. 可控语音生成:
Ming-flash-omni 2.0直接在同一套神经网络里同步生成人声、音效、配乐,并且支持用自然语言调节“用四川话、语速慢一点、带一点忧伤、背景加下雨声”。官方展示的“春节报菜名”音频里,菜名报得抑扬顿挫,背景还有真实的烟花绽放音效——这种“声临其境”的统一生成,在全球开源模型中是独一份。
3. 高动态图像编辑:
你发一张站在天安门前的游客照,指令是“背景换成瑞士雪山,改成拍手的姿势”,它能在毫秒级运算中完成人物姿态重绘、光影重映射、背景无缝融合,且人物五官、衣着褶皱毫无违和感。这背后是原生单流架构将分割、生成、编辑三大任务统一打通,彻底摆脱了传统扩散模型在复杂指令下的“崩坏”顽疾。
数字不说谎,开源即王座
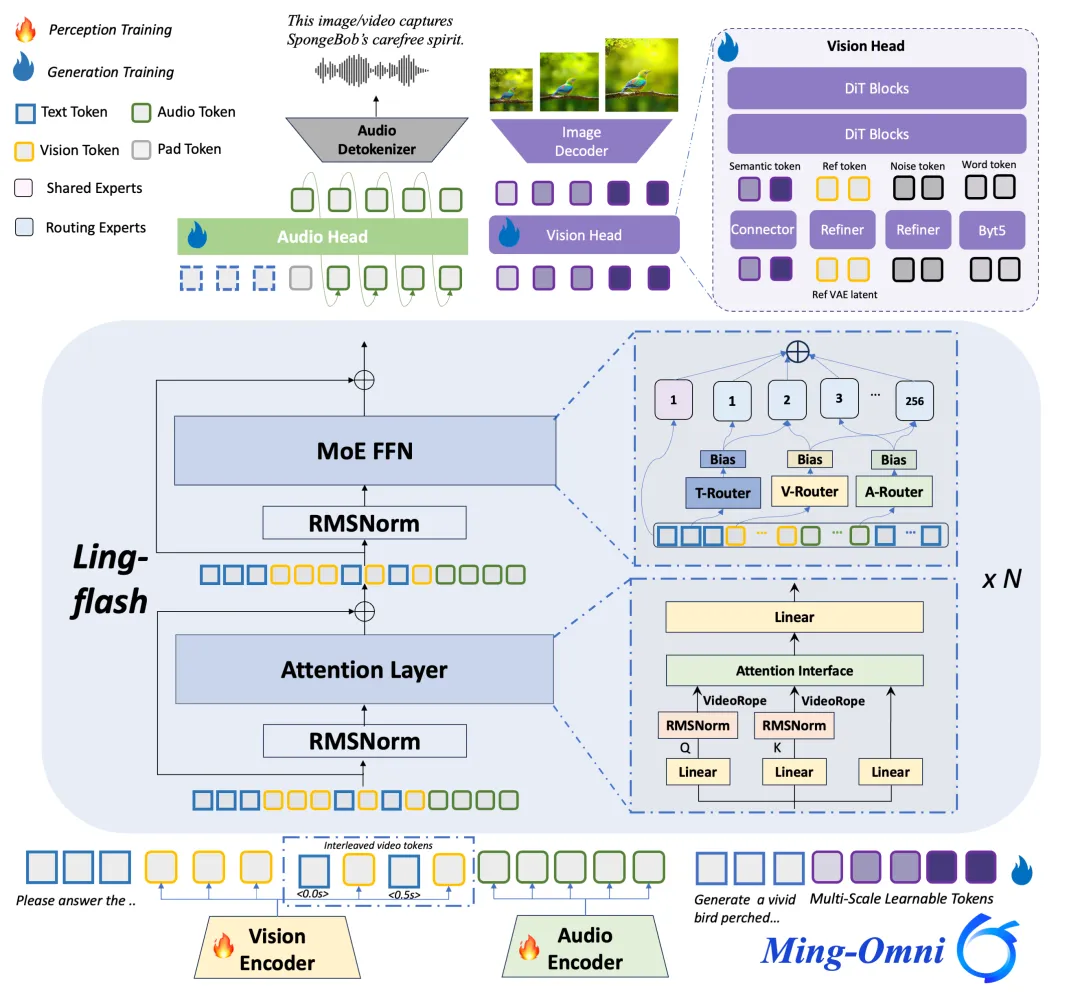
Ming-flash-omni 2.0交出的成绩单堪称“屠榜级”:
- 视觉理解:在HallusionBench、MMvet等反幻觉测试中得分超越Gemini 2.5 Pro,图像定位精度逼近90分,内置知识库准确性和丰富度远超Qwen3-Omini;
- 语音能力:作为业界首个“三合一”统一生成模型,语音识别错误率(WER)降至行业最低梯队,零样本音色克隆支持100+精品音色库即时调用-1;
- 图像编辑:在DPGBench、Geneval等专业测评中匹敌专用模型,场景替换、物体移除的细节还原度达到商用级-7。
该模型开源24小时内,Hugging Face下载量即冲上当日热门榜;而在蚂蚁自研的AI助手“灵光”一侧,普通人已借助其底层能力创造了超过1200万个小应用,“灵光”上线第4天下载量破百万,6天破200万,成为现象级AI产品。另一款健康类AI产品“蚂蚁阿福”2025年12月月活已突破3000万,跻身国内AI应用前四。
为什么偏偏是蚂蚁跑通了“统一架构”?
放眼全球,谷歌Gemini、OpenAI GPT-4o都在押注全模态,但开源阵营长期落后。Ming-flash-omni 2.0的突围,靠的是三个“反常识”的工程选择:
低帧率反而成就高效率
该模型在推理阶段仅需3.1Hz的极低帧率,就能生成高保真长音频。传统TTS模型需要逐帧预测,而蚂蚁自研的12.5Hz超低帧率连续语音Tokenizer,将音频特征高度压缩,既降低算力消耗,又避免长序列生成中的“幻觉累积”。
用“难例”喂出“专家”
针对易混淆的动植物、文物,蚂蚁团队专门构建相似样本拼接图,强迫模型在对比中学会区分“秋田犬和柴犬”“元青花和永宣青花”。
不回避“脏活累活”
许多全模态模型为了追求架构优美,会放弃对底层视觉任务的深度优化。但Ming-flash-omni 2.0硬是把分割、生成、编辑塞进同一套单流模型,通过“编辑式分割”冷启动,让模型先学会定位像素,再理解语义。
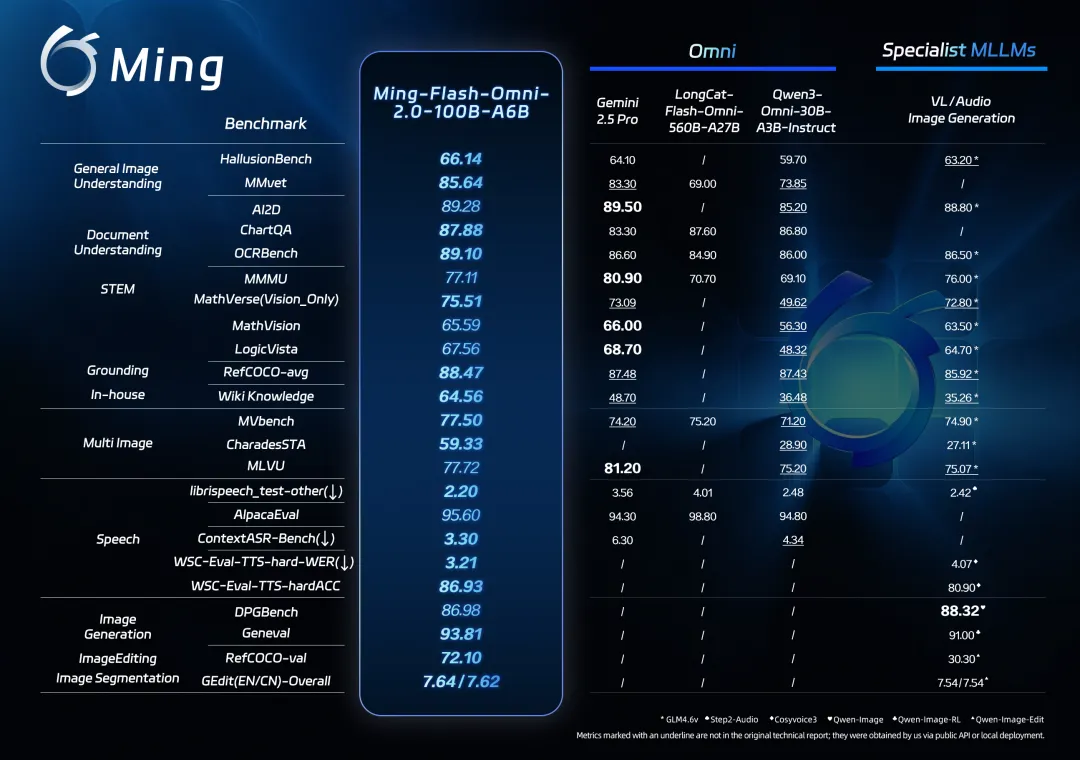
Ming-flash-omni 2.0的实测表现
从“通用底座”到“智能文明”的惊险一跃
Ming-flash-omni 2.0的开源,不是终点,而是全模态技术 “规模商用”的发令枪。未来12个月,有三个窗口期值得紧盯:
视频时序理解的攻坚战
当前版本对静态图像、短语音已臻化境,但对长视频的事件推理仍有优化空间。蚂蚁团队已明确将Time-Interleaved VideoRoPE机制列为迭代重点,目标是让AI像人类一样,在连续画面中理解“前因后果”。
“音画一体”的内容革命
可以预见,2026年下半年起,UGC平台将涌现大量“一人成军”的创作者——一个人,一个模型,就是一支好莱坞团队。
端侧部署的生死时速
目前模型虽已极致压缩推理成本,但要跑在手机、眼镜、耳机等终端上,仍需进一步瘦身。若能将6B激活参数压缩至2B以内且保持精度,全模态AI助手的入口将从App转移至操作系统底层。
回到开头的那个魔咒
我们曾以为,AI的终极形态是无数个“单项冠军”的排列组合。但Ming-flash-omni 2.0证明了另一条路:一个真正智能的系统,不该靠缝合感知世界。它用同一套神经网络看懂文物、念出诗、画出雪。
这不仅是技术的代际跃迁,更是一种技术哲学的宣告:全模态不是多选题,而是必答题。而蚂蚁,刚刚把标准答案开源了。
