
Anthropic指控中国三家AI公司"蒸馏攻击":一场技术争议还是地缘政治角力?

一、2026年2月24日,一场指控引发的舆论风暴
2026年2月23日,Anthropic在X平台发文指控:DeepSeek、MiniMax和月之暗面(Moonshot)三家中国AI实验室,通过约24000个虚假账户与Claude进行了超过1600万次交互,系统性提取其在推理、工具调用与编程等方面的核心能力。
Anthropic将这种行为称为"工业级规模的蒸馏攻击"(industrial-scale distillation attacks),并警告这可能带来国家安全风险。
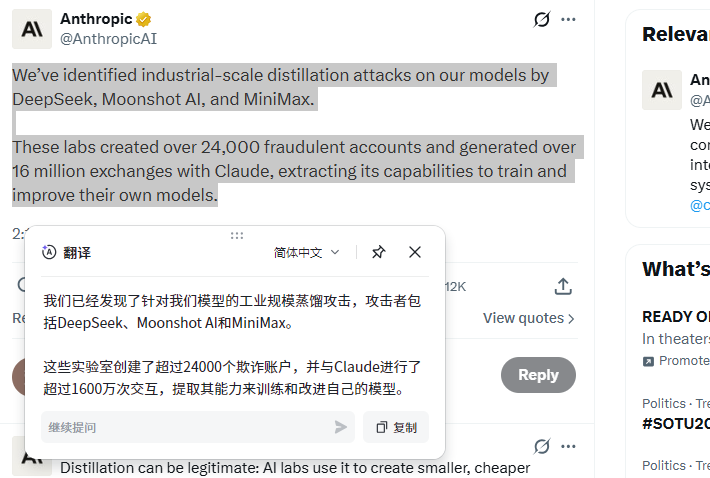
Anthropic的推文
但这个指控一经发布,就遭到了一边倒的质疑。
新加坡南洋理工大学AI教授Erik Cambria告诉CNBC:"合法蒸馏使用的存在,让监管工作变得更难,因为证明企业使用模型的意图和规模,要比传统的版权索赔复杂得多。合法使用和对抗性利用之间的界限往往是模糊的。"
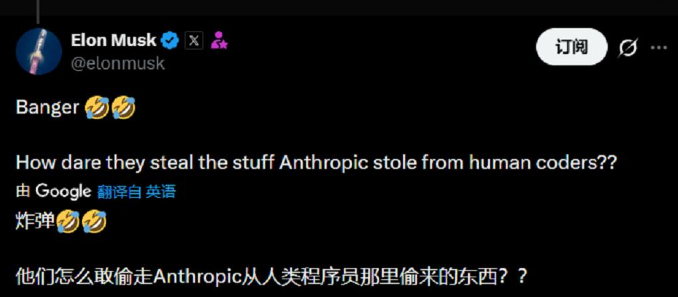
马斯克第一时间反讽:"绝了,他们(DeepSeek们)怎么敢偷Anthropic从人类程序员那里'偷'来的东西?"
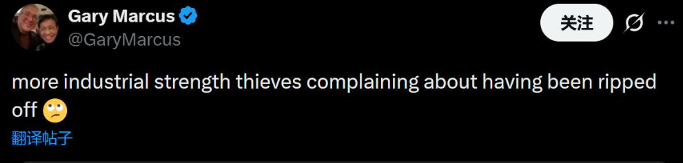
AI评论家Gary Marcus认为,Anthropic的行为是"肆无忌惮的盗贼抱怨自己被抢劫了"。
这场争议的核心问题是:Anthropic的指控,到底是基于技术事实,还是地缘政治考量?
二、事实核查:Anthropic说了什么,哪些是确凿的,哪些存疑
确凿的事实
事实1:蒸馏是AI行业的常见技术
蒸馏是AI实验室用于自己模型的常见训练方法,用于创建更小、更便宜的版本。
Anthropic自己也承认:"蒸馏本身是一种广泛应用且合法的技术,许多前沿实验室都会用更强大的模型训练体量更小、成本更低的模型版本。"
事实2:三家中国公司的模型确实在快速进步
DeepSeek、MiniMax和月之暗面的Kimi目前在知名AI排行榜Artificial Analysis上位列前15名。
MiniMax M2.5和Kimi K2.5近期一度成为大模型调用平台OpenRouter上使用量最大的模型。
事实3:OpenAI之前也提出过类似指控
2026年2月初,OpenAI向美国立法者提交了一封公开信,声称观察到"DeepSeek正在尝试蒸馏OpenAI和其他美国前沿实验室的前沿模型,包括通过新的、混淆的方法"。
存疑的部分
存疑1:Anthropic的证据充分吗?
Anthropic声称通过IP地址关联、元数据请求和基础设施指标作为主要技术证据,并与AI行业其他实体观察到的类似行为进行了佐证。
但目前Anthropic并未公开具体的技术证据或原始数据。
存疑2:"虚假账户"的定义是什么?
Anthropic称三家公司使用了"约24000个虚假账户"。
但什么是"虚假账户"?
- 如果是用假身份注册的个人账户,这确实违反服务条款
- 如果是企业为研发目的批量注册的测试账户,法律性质可能不同
目前Anthropic并未详细说明"虚假账户"的定义标准。
存疑3:"1600万次交互"到底意味着什么?
三家公司的操作规模差异很大:DeepSeek约15万次交互,月之暗面超过340万次,MiniMax超过1300万次。
但问题是:
- 这些交互是否都付费了?(如果付费,是否算"合理使用产品"?)
- 正常企业级用户的交互量是多少?(没有对比基准,很难判断"异常")
三、争议的核心:技术问题还是政治问题?
争议点1:训练数据的"原罪"
马斯克的核心批评是:Anthropic自己的训练数据来源就有问题。
Anthropic目前是音乐出版商诉讼的对象,这些出版商指控Anthropic使用非法复制的歌曲来训练Claude聊天机器人。
有网友锐评:"Anthropic不也是爬取了整个互联网的数据,并打破了无数的服务条款吗?"
争议点2:"蒸馏"的法律边界在哪里?
目前AI行业对"蒸馏"的法律边界并无清晰界定。
- 如果我付费使用Claude API,用它生成的数据训练我的模型,这违法吗?
- 如果我把Claude生成的代码发布到GitHub,别人的模型训练时抓取了这些代码,这算蒸馏吗?
CNN报道称,大多数领先的专有AI模型提供商(包括Anthropic)都明确禁止此类做法。但蒸馏是AI行业中一种常见的训练方法,前沿实验室经常蒸馏自己的模型,为客户制作更便宜的版本。
争议点3:时机的"巧合"
这些指控正值美国就如何严格执行先进AI芯片出口管制展开辩论之际,该政策旨在遏制中国的AI发展。
就在Anthropic发表声明的当天,路透社报道称,据匿名高级官员称,美国发现证据表明DeepSeek在Nvidia旗舰Blackwell芯片上训练其AI模型,显然违反了出口管制。
这种"巧合"让很多人怀疑:Anthropic的指控,是否有政治动机?
四、理性辩证:双方都有问题
Anthropic的问题
问题1:双重标准
Anthropic指责别人"蒸馏",但自己的训练数据来源同样存疑。
问题2:缺乏透明度
Anthropic选择在X平台发文而非诉诸法律,并且未公开具体证据。
问题3:国家安全的"过度解读"
Anthropic警告:"通过非法蒸馏构建的模型不太可能保留这些安全防护措施,这意味着危险能力可以在大部分保护措施被完全剥离的情况下扩散。"并指出威权政府可能将前沿AI用于"进攻性网络行动、虚假信息运动和大规模监控"。
但这种"安全风险"的论述,很容易被用作贸易保护主义的工具。
中国AI公司的问题
问题1:如果确实使用了虚假账户,这违反服务条款
无论蒸馏本身是否合法,使用虚假账户规避区域限制,在商业伦理上是有问题的。
问题2:透明度不足
目前三家中国公司均未对指控做出公开回应,这在PR层面是被动的。
问题3:需要建立行业自律标准
中国AI公司在海外市场快速扩张,但在合规性、透明度方面仍有提升空间。
五、更深层的问题:AI时代的知识产权如何界定?
这场争议的本质,是AI时代知识产权边界的模糊性。
传统知识产权体系面临挑战:
- 训练数据的版权归属不清AI公司爬取互联网数据训练模型,是否需要获得每个内容创作者的授权?
- 如果不需要,为什么蒸馏就需要?
- API输出的所有权不明我付费调用API得到的输出,我是否拥有这些数据的使用权?
- 如果我拥有,用来训练模型算不算侵权?
- "模仿"和"盗窃"的界限模糊学习别人的模型架构算不算侵权?
- 用别人的输出训练自己的模型算不算侵权?
这些问题,目前全球都没有清晰答案。
六、结语:技术争议的背后,是地缘政治的暗流
在Anthropic和OpenAI各自的声明中,它们都将这些中国公司的蒸馏行为定义为国家安全威胁。然而专家表示,目前尚不清楚这些声明在多大程度上反映了对安全的真正担忧,还是对保持美国AI公司竞争优势的渴望。
这场争议揭示了三个层面的冲突:
- 商业层面:Anthropic和OpenAI面临中国模型的竞争压力
- 技术层面:AI时代的知识产权边界亟待明确
- 政治层面:中美AI竞争正在从技术竞争转向规则制定权的争夺
对中国AI公司而言,需要:
提高合规意识,避免使用虚假账户等灰色手段
增强透明度,主动回应质疑
建立行业自律标准
对Anthropic等美国公司而言,需要:
避免双重标准,自己的训练数据来源也应接受审查
以法律而非舆论作为解决争议的主要手段
区分商业竞争和国家安全,避免过度政治化
对全球AI治理而言,需要:
建立清晰的蒸馏行为法律边界
制定AI时代的知识产权保护新规则
通过多边机制而非单边制裁解决争议
技术无国界,但竞争有立场。
在这场关于"蒸馏"的争议中,真正需要蒸馏的,或许是混杂在其中的政治杂质。
