
DeepSeek V4细节曝光,原生多模态+100万长文本,万亿参数“海狮”浮出水面



不仅是模型迭代,而是国产 AI 与国产算力的双向奔赴。
春节刚过,AI 圈呈现出一种暴风雨前的宁静。
虽然万众期待的 DeepSeek V4 并未如期在除夕夜发布,但其体量依然能从 GitHub 的提交记录窥见一二,在 Reddit 和 X(前推特)的开发者社区中,关于它的传说已经传疯了。
就在刚刚,塔猴总结多方信息后得出结论:V4 打破行业惯例,拒绝向英伟达开放预览,死磕国产算力适配,代码能力更是直接飙到了 HumanEval 90%。
据泄露信息显示,代号为海狮轻量版的 V4 预览版正在 NDA(保密协议)下进行高强度的灰度测试。
这一次,DeepSeek 似乎不想再做跟随者。100 万 Token 的超长上下文窗口、原生多模态能力,以及针对国产硬件的极致优化,都在释放一个强烈的信号。
这是一场国产 AI 软件与国产算力硬件的双向奔赴。
塔猴第一时间梳理了关于 DeepSeek V4 的所有爆料,带你提前看清这只刚刚露出水面的深海巨兽。

一、断供美国芯片商,优先适配国产算力
在 AI 大模型圈,一直有个潜规则:任何顶级模型发布前,开发者通常会优先向英伟达或 AMD 等美国芯片巨头提供预览版,以确保模型在 CUDA 生态下的性能表现。这是技术验证,也是带有江湖气息的拜码头。
但这一次,DeepSeek 选择了反其道而行。
据路透社的最新爆料,DeepSeek V4 在闭门测试阶段,并未向美国芯片制造商提供预发布版本,而是优先给予了华为等中国本土供应商几周的早期访问权。
这一反常操作的逻辑,并非狂妄,而是极致的务实。
知情人士透露,DeepSeek 此举旨在利用发布前的最后窗口期,与国产算力平台(如昇腾系列)进行深度联调。目标非常明确:要证明 DeepSeek 的高效率架构,即使不依赖 H100 集群,在国产硬件上也能跑出极致的推理性能。

华为昇腾系列发布会
时间线也印证了这一点。据悉,早在农历新年前后,DeepSeek 内部就已经开始了与国产硬件厂商的联合调试,确保 V4 正式发布时,国内开发者能做到开箱即用,不再受制于人。
二、解密海狮:原生多模态 + 百万长文本
除了战略上的转向,DeepSeek V4 在产品力上的升级更是可以用"炸裂"来形容。
据多位参与内测的开发者泄露,V4 确认为万亿参数级别的巨型基础模型。而且得益于 DeepSeek 一贯擅长的 MoE(混合专家)架构,其推理成本依然被控制在极低水平。

相比于 V3,V4 带来了三大跨越式升级:
1. Context 暴涨:百万长文
V4 的上下文窗口从 V3 的 128K 直接拉升至 100 万 Token。
这意味着它不再只是读代码,而是能一次性吃下整个中型项目的代码库,并在此基础上进行全局重构,且不丢失逻辑智商。
2. 原生多模态:SVG 生成能力惊艳
不同于市面上许多拼凑型多模态模型,V4 被曝具备 Native Multimodal 能力。
最直观的反馈来自内测用户对 SVG 矢量图生成的评价。一位代号为 @marmaduke091 的测试者在社交媒体上表示,V4 在生成复杂逻辑的矢量图形时,“设计逻辑吊打当前 Web 版模型”,展现出了极强的视觉理解力。
3. 代码之王:数据碾压 GPT-5.2
V4 被明确定位为代码核心模型。
内部泄露的基准测试数据显示,V4 在代码生成领域的权威榜单 HumanEval 上,跑分惊人地飙升到了 90% 以上;在更复杂的 SWE-bench Verified 测试中,得分也超过了 80%。
如果数据属实,意味着 DeepSeek V4 在编程能力上已经实质性超越了 GPT-5.2。
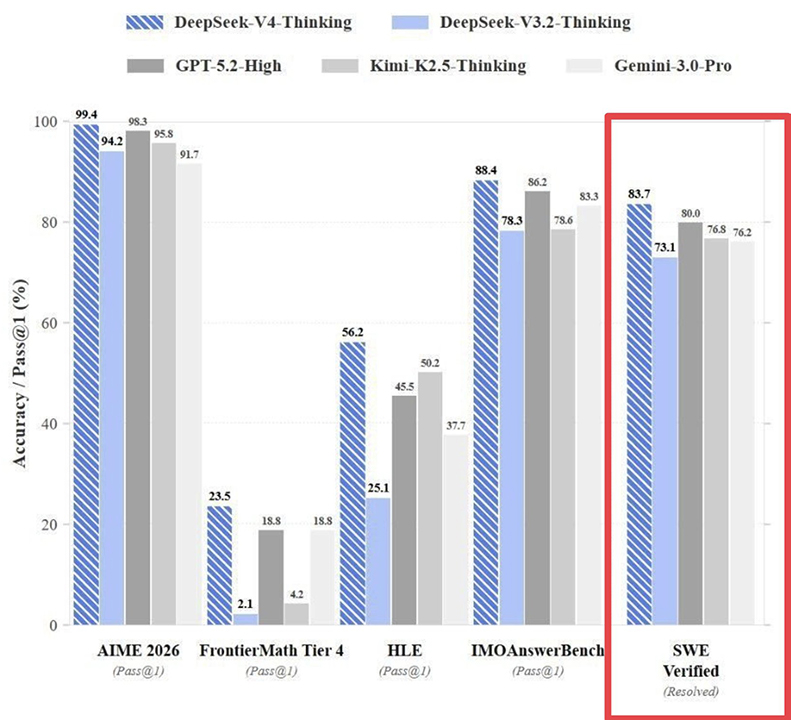
内部泄露的 SWE-bench Verified 测试数据
更有内测用户形容,V4 Lite 版本在执行代理任务时比 V3 敏捷得多,响应风格非常类似 GPT-4,但速度更快,仿佛随时准备接管你的 IDE。
三、GitHub 的疯狂更新
虽然模型还没发,但代码不会骗人。
塔猴化身侦探,深扒了 DeepSeek 官方 GitHub 仓库在 2026 年 1 月至 2 月期间的提交记录。虽然没有直接发布 V4 的代码,但周边的密集更新已经泄露了天机,一切都在为 V4 的超大规模推理铺路。
核心线索一:Engram 架构
1 月中旬,DeepSeek 悄然更新了与 Engram 相关的代码。相关论文显示,这是一种条件内存扩展技术。
它极有可能是 V4 实现 100 万长文本且不掉速的关键。Engram 架构就像是给大模型装上了一个高效的海马体,解决了长文本任务中记不住和算得慢的永恒矛盾。
核心线索二:FlashMLA
2 月 6 日,FlashMLA(高效多头潜在注意力内核)仓库更新。这套内核专为 H800 及同类国产算力架构优化,目的只有一个:在硬件受限的情况下,通过极致的软件优化,榨干每一滴显存和算力。
核心线索三:3FS 与 DeepGEMM
就在昨天(2 月 25 日),高性能分布式文件系统 3FS 和矩阵乘法内核 DeepGEMM 再次迎来更新。这暗示了 V4 对超大规模分布式训练和推理的极度渴求,DeepSeek 正在构建一套从底层文件系统到上层算力调度的完整护城河。
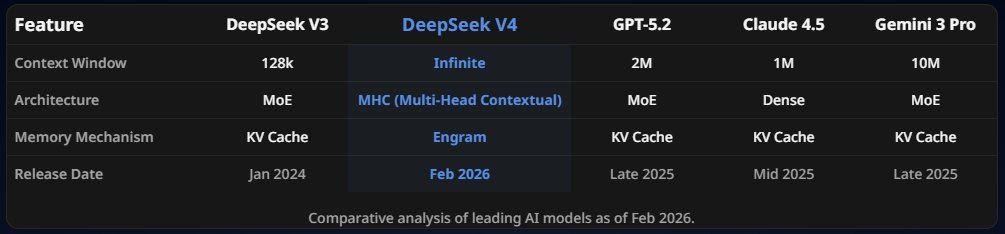
DeepSeek V4 架构对比图
四、商业冲击:成本仅 GPT-5 零头
DeepSeek 最可怕的地方,从来不是它有多强,而是它有多便宜。
在此次泄露的信息中,V4 再次扮演了价格屠夫的角色。
在训练端,业内预估 DeepSeek V4 的训练成本仅为 1000 万美元左右。相比之下,传闻中 GPT-5.3 的训练费用高达数亿美元。DeepSeek 再次用实战证明了算法效率 > 堆算力的中国智慧。
在推理端,V4 的推理成本预计比西方主流模型低 10-40 倍。
但最大的惊喜在于硬件门槛的降低。泄露信息显示,经过量化后的 V4(或其蒸馏版),有望在双路 RTX 4090 甚至高端国产消费级显卡上流畅运行。
这意味着,中小企业、科研机构甚至个人开发者,不再需要依赖昂贵的云端 API,也不必担心数据隐私泄露。只要在本地搭几张显卡,就能拥有一个媲美甚至超越 GPT-5.2 的私有化编程助手。

五、结语
回看 DeepSeek V3,它让我们看到了国产大模型平替世界顶流的希望。
而即将到来的 DeepSeek V4,则显露出了更大的野心,它试图证明超越的可能。
V4 的延迟发布,从除夕推到现在,或许正是为了憋这一口"国产算力完美适配"的大招,实现国产生态的突围。
GitHub 上那些密密麻麻的代码提交记录,实则是 V4 半夜的磨刀声。当 AI 不再完全依赖昂贵的英伟达集群,当万亿参数的模型能跑进千家万户的机箱,真正的 AI 商业化元年才算正式到来。
下周,让我们拭目以待,看看这只海狮能否掀翻硅谷的巨轮。
