
Nano Banana 2来了:AI生图终于从"好看"变成了"好用"

你上一次遇到AI生图"写字像鬼画符"的问题,是什么时候?
如果你曾经花三十分钟反复调整提示词,只是为了让海报上的产品名称不要拼错;如果你见过AI努力生成一张多人物场景、最终把角色们的脸全串成一张;如果你盯着一张AI生成的信息图,发现数据标注东倒西歪、图表逻辑混乱:那你就亲身经历了AI生图领域一个绵延多年的系统性缺陷:模型能生成漂亮的像素,却不真正"理解"它在画什么。
谷歌这次发布的Gemini Flash图像模型(外界也称Nano Banana 2,基于全新的Gemini 3.1 Flash Image)想解决的,正是这个更根本的问题。

大家一直在打错仗
生图模型的军备竞赛,主战场一直是"视觉质量":谁的光影更真实,谁的纹理更细腻,谁的构图更有美感。评测机构用Elo分数排名,用户截图对比,媒体争相发布"哪款AI画风最惊艳"的横评文章。
这个逻辑没有错,但它忽略了一件事:绝大多数真实的生图需求,不是为了生成一幅挂在展览馆的艺术作品。
设计师要出营销海报,需要文字准确可读。教育创作者要做科普信息图,需要数据标注清晰。游戏公司要做连续叙事的概念图,需要主角不能每张都换一张脸。内容团队要做全球本地化素材,需要一键把英语广告的文字和场景同步替换成印地语版本。
这些需求,"更漂亮的像素"解决不了。
这才是Gemini Flash图像模型这次真正在动的东西。
联网这件事,被严重低估了
Gemini Flash图像模型最核心的技术底座,是它深度整合了Gemini的知识库和实时网络搜索能力。这听起来像一个工程细节,但它带来的实际影响,比"提升视觉质量"大得多。
想象一个场景:你让一个传统生图模型画"克洛·吕斯城堡",那座达·芬奇晚年居住的法国城堡。模型会给你生成一座城堡,可能好看,但它在凭空想象。如果你要求某种特定风格,它生成的是一个"城堡的概念",而不是那座真实建筑的还原。
而当模型能先联网搜索这座城堡的真实照片,理解它的建筑结构和历史特征,再按照你指定的风格来渲染。这中间的差距,不是质量的差距,是真实性的差距。

克洛·吕斯博物馆的综合立体主义风格
这个能力的商业价值在信息图表领域最为直接。让模型生成一张"水循环的科普信息图",它能从知识库里调取完整的地球水循环知识,自主决定视角、布局、引导线和文字说明,直接输出一张可以拿到课堂用的成品。这件事,不懂水循环的模型做不到,哪怕它能生成很漂亮的蓝色水滴。
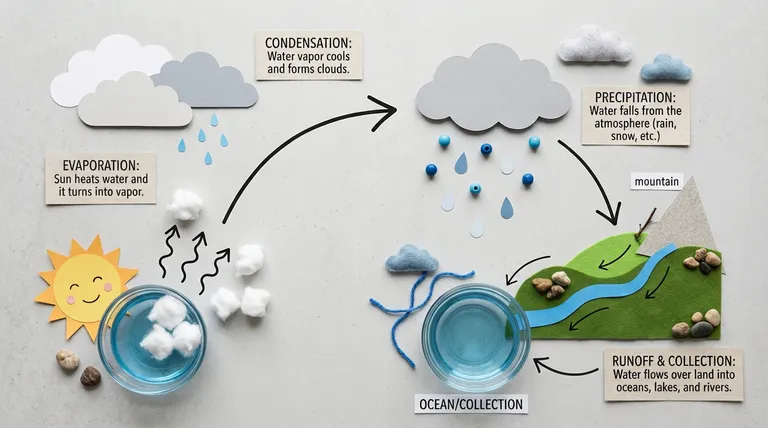
文字渲染:终于从"凑合能用"变成了"真的能用"
AI生图的文字问题,是这个行业最长寿的笑话之一。各家模型都在进步,但从"大部分字母认识"到"可以直接拿去做商业物料",中间一直有一道看不见的坎。
这道坎对很多使用场景来说,是决定性的。
一张营销海报,品牌名拼错了,不能用。一张活动邀请函,日期写错了,不能用。一张产品包装的概念图,成分表乱码了,不能用。这些场景里,模型的"整体视觉质量"是多少分,不重要,只要文字错误,就等于零分。
Gemini Flash图像模型在文字渲染上的提升,不只是减少了错误,而是覆盖了多语言场景。中文汉字的渲染问题,在这一代模型里已经基本解决;阿拉伯语、印地语等右向书写或字母连写语言,也能稳定生成。
更重要的是,它把文字渲染和本地化能力打通了。同一张广告,你可以告诉模型"把所有文字翻译成印地语,同时把场景换成印度风格",模型能在一次生成里同时完成语言翻译、文字渲染和视觉风格的本地化调整。对于需要在多个市场同步投放素材的团队而言,这不是效率提升,而是工作流的重新设计。
主体一致性:连续叙事第一次变得可行
另一个被长期忽视的生产痛点,是多主体、跨图的一致性问题。
做连环画的创作者最熟悉这种痛苦:第一张图里主角穿蓝衣服,第二张变成了红色;左手的道具消失了;侧脸和正脸看起来完全不像同一个人。每生成一张新图,就要重新祈祷"这次主角别换脸"。
这个问题的根源在于,传统生图模型每次生成都是独立的,它"不记得"上一张图里主角长什么样。
Gemini Flash图像模型在这次更新里,把单次工作流里的主体一致性提升到了支持最多5个角色、14个对象的水平,并且能做到6张连续图里服装外貌保持一致、但表情视角各不相同。
这对游戏概念设计、儿童绘本、品牌吉祥物的多场景延伸,是实质性的能力突破。一个角色,终于可以真正地"活在"一系列图片里,而不是在每张图里重新投胎。
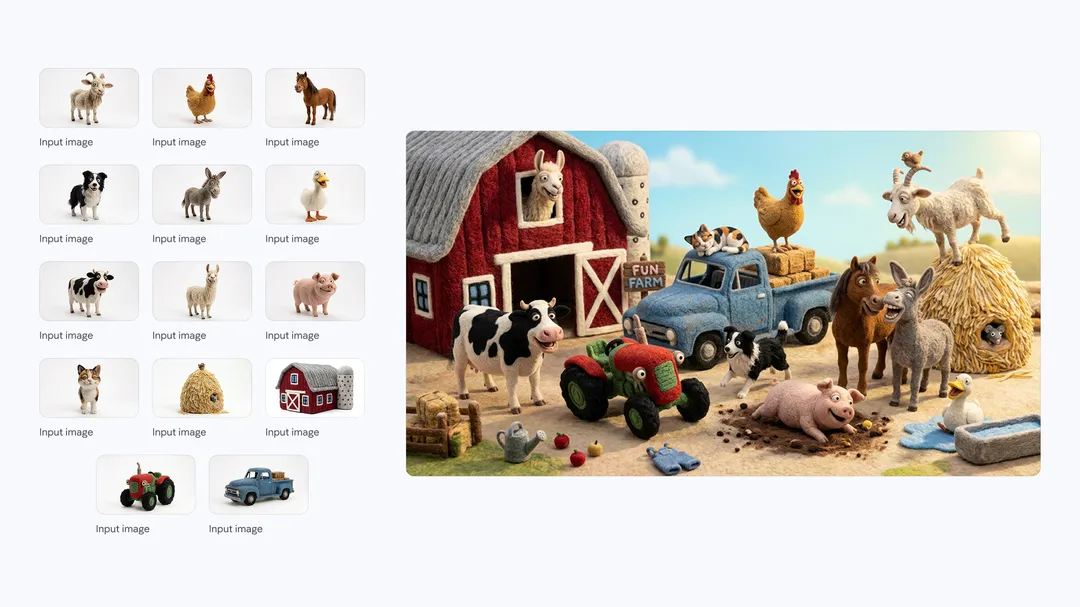
农场里欢乐的人物和物品

毛茸茸的小伙伴们正在建造树屋
定价策略:这是一次精心设计的市场布局
技术能力之外,谷歌这次的定价策略同样值得细看。
在当前的谷歌图像生成产品矩阵里,Gemini Flash图像模型的API定价约为0.0672美元每张,是Pro版本的一半。结合它能够处理的任务类型——文本渲染、信息图、本地化广告、连续叙事——这个价格指向的是一个非常具体的用户:有大量批量生产需求、对成本敏感、不需要极端高精度输出的商业用户。
从定价角度看,谷歌的Imagen 4 Ultra为每张0.06美元,而OpenAI的GPT Image高质量版本为0.167美元,差距将近3倍.这个价差在大规模商业使用场景里会被急剧放大——批量生产一万张营销素材,两家平台的成本差距可以超过一千美元。
与此同时,Pro版本依然保留,留给那些对文字准确性、4K分辨率或复杂指令遵循有极高要求的专业场景。两个版本不构成竞争关系,而是覆盖了同一用户在不同任务类型下的不同需求。
这种产品矩阵的设计逻辑很清晰:用Flash版本覆盖日常大量生产需求,用Pro版本锚定高端专业场景,同时把两者都压在OpenAI的同类定价之下。
这件事对整个行业意味着什么
如果把这次发布放到更大的背景下来看,谷歌在做的事情有一个更深的含义。
过去两年,AI生图的竞争逻辑是"谁的图更好看"。这个维度上,Midjourney、Stability AI、OpenAI和谷歌之间的差距在快速收窄,用户体验也越来越趋同。在一个纯粹比视觉质量的市场里,领先优势很难维持。
但谷歌这次在做的事情,是把生图能力和更大的产品生态绑定起来。联网搜索、多语言处理、与Gemini知识库的集成、在Google Workspace和Google Ads里的原生嵌入,这些不是生图模型本身的能力,而是谷歌作为一个拥有全球最大搜索引擎和生产力工具矩阵的公司,才能真正兑现的护城河。
换句话说:当生图能力本身趋于同质化,竞争的下一个维度会是"谁能更好地把生图能力嵌入用户的实际工作流"。谷歌在这个维度上的起点,是其他生图公司无法复制的。
据统计,仅Nano Banana Pro就在上线53天内被谷歌用户生成了超过10亿张图像——这个数字背后,是谷歌庞大的消费者基础和产品入口在起作用,而不只是模型本身的能力。
那些还没有解决的问题
这篇文章不想止步于产品宣传。
Gemini Flash图像模型有它真实的局限性。谷歌自己也承认,模型在处理小尺寸人脸、细线条结构和复杂构图时仍会出现瑕疵,而且在生成中心对称构图(比如一个完美居中的圆形)时仍有困难。对于给出无意义提示词的用户,输出依然不可预测。
更深的问题在于,联网搜索能力虽然强大,但它也意味着生成内容和真实世界信息之间的边界变得更模糊。当模型声称自己是"基于真实地理和气象数据"来生成飞机窗外的景色时,如何验证这个说法?如何确保它不在某些场景里生成"看起来很真实但实际上错误"的信息图?这些问题,随着模型能力的增强,会变得更重要而不是更不重要。
谷歌使用SynthID对所有Imagen生成的图片进行不可见的数字水印标注,这是一个负责任的方向,但在假信息生产成本不断下降的环境里,技术手段和内容审核机制之间的张力,不会因为一个水印就消解。
AI生图走到今天,已经不再是一个"能不能生成好看图片"的问题。那个问题,多家公司都已经给出了合格的答案。
真正的竞争,正在转移到一个更务实的地方:这个生图能力,能不能真正解决用户在实际工作里遇到的具体问题?能不能准确写出文字?能不能理解真实世界的知识?能不能记住主角的脸?能不能一键完成本地化?
Gemini Flash图像模型这次的答案,是一次值得认真对待的回应。
你现在使用AI生图工具时,卡住你们的核心瓶颈是什么?是视觉质量不够好,还是那些老生常谈的问题:文字、一致性、真实性?这个答案,可能比你想象的更能预测下一个产品周期里谁会真正赢。
