
我用Nano Banana 2测了一天,发现它把AI生图最难啃的骨头全啃了

你上一次为了一张AI生成的图返工,花了多长时间?
不是那种"觉得不好看、再试一次"的返工,而是那种你明明把需求写得清清楚楚,但是你依然不得不花四十分钟重新调整提示词,最终得到一张"勉强能用"的结果。
这种体验,做过内容的人都不陌生。
行业里有一个惯性思维已经固化很久了:想要更好的生图质量,就用旗舰级Pro模型;想要速度,就接受质量的妥协。这个"鱼和熊掌"的逻辑,被当作理所当然的行业常识,深入到了每一个团队的工具选型决策里。
直到谷歌发布了Nano Banana 2。

AI生图有一个从未被正视的系统性缺陷
在讨论Nano Banana 2之前,必须先说清楚一件事:过去两年,AI生图的军备竞赛打的是什么?
答案是视觉质量。谁的光影更真实,谁的纹理更细腻,谁的构图更有美感。各家公司的发布会上,比的是最漂亮的那张图。
但这场竞赛有一个没人大声说破的漏洞:绝大多数真实的生图需求,压根不是为了生成一幅挂在展览馆的艺术作品。
设计师要出营销海报,需要文字准确可读。教育创作者做科普信息图,需要数据标注清晰。游戏公司做连续叙事概念图,需要主角不能每张都换一张脸。内容团队做全球化素材,需要一键把英语广告同步换成印地语版本。
这些需求里,"视觉质量多少分"不重要,只要文字错误,就等于零分。只要主角换脸,这批图就全部作废。
这是AI生图领域一个绵延多年、却从未被正视的系统性缺陷:模型能生成漂亮的像素,却不真正"理解"它在画什么。
Nano Banana 2瞄准的,正是这个更根本的问题。
它到底做对了什么?从实测结果反推底层逻辑
第一件事:它终于真正"读懂"了指令
传统生图模型最令人抓狂的问题之一,是处理复杂空间关系时的"选择性失忆"。你说"桌子左侧是透明玻璃杯,右侧是一本封面写着'2026 FUTURE'的黑皮书",模型生成的结果里,要么左右互换,要么书名拼错,要么玻璃杯的折射效果完全不对。
实测中,同样这个指令,Nano Banana 2给出的结果是:玻璃杯中的蓝色液体产生了真实的折射效果,书封上的文字清晰可辨,背景雨夜窗户的微光细腻地透射在水面上。每一个指定的细节,都出现在了它该出现的位置。

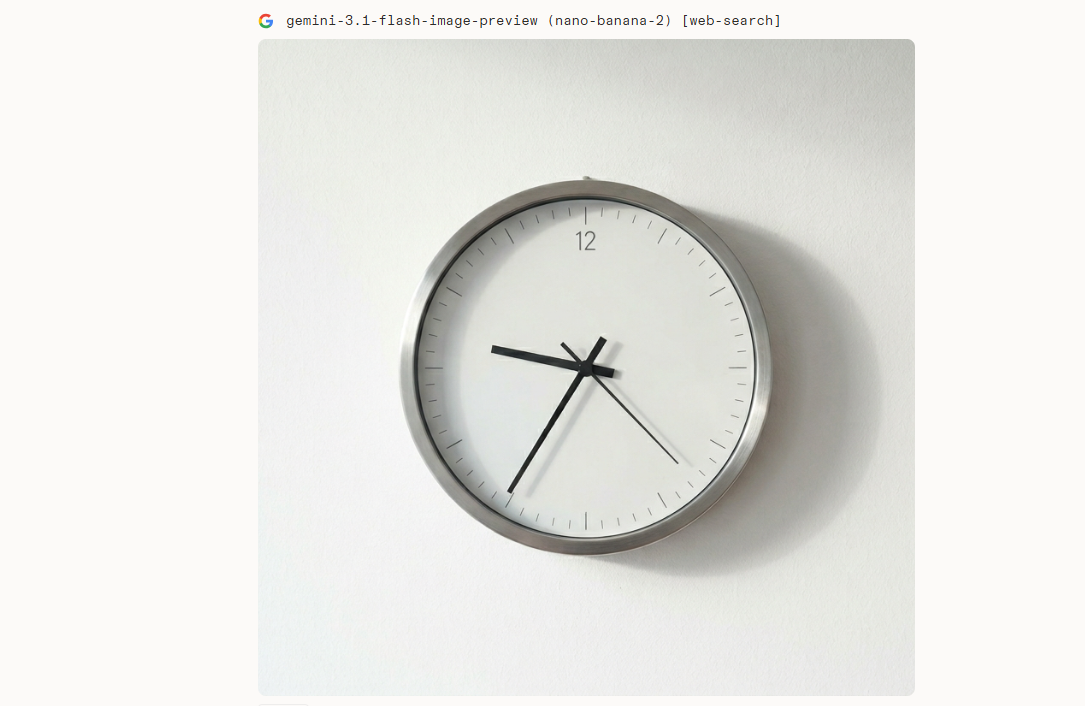
更能说明问题的是时钟测试。让AI画出"指针指向21:35的时钟",这是历代生图模型的经典死亡关卡,因为它需要模型理解抽象数字和具象物理指针位置之间的映射关系。
提示词 (Prompt):
一个极简风格的现代墙钟,挂在纯白色的墙上。时钟清晰显示时间为 21:35。光线从侧面打入,在墙上留下淡淡的阴影。4K分辨率,超写实主义,金属质感,指针线条干净锐利。
Nano Banana 2在这项测试里直接给出了准确结果,指针位置精确无误。
这背后的底层逻辑是什么?
Nano Banana 2基于Gemini 3.1 Flash架构,深度整合了谷歌的知识库和实时网络搜索能力。它在生成图像之前,会先对复杂提示词进行推理,这个被称为"思考模式"(Thinking Mode)的机制,让模型在动笔之前先想清楚逻辑,而不是凭感觉生成像素。
打个比方:旧的模型像一个没看清题目就开始答题的学生,靠直觉猜;新的模型像一个先把题目读三遍、理清关系再下笔的学生。输出质量的差距,从这里就开始了。
第二件事:文字渲染从"凑合能用"变成了"真的能用"
AI生图的文字问题,是这个行业最长寿的笑话。各家模型都在进步,但从"大部分字母认识"到"可以直接拿去做商业物料",中间一直有一道坎。
实测中,将一篇耳机评测文章的产品优点、名称和售价输入给它,要求生成一张排版完整的信息图。

结果与人手在InDesign等专业排版软件上制作的成品质量极为相近。模型甚至主动在图片中为文字内容"腾出了空间",而不是把文字硬塞进已有的画面里。

更重要的是多语言覆盖能力。同一张完成的广告图,要求翻译成其他语言版本,模型不只是换了文字,而是保持了原图的整体排版风格和视觉结构。

对于需要在多个市场同步投放素材的团队,这不是效率提升,而是工作流的重新设计。
第三件事:主体一致性让连续叙事第一次变得可行
做连环画或连续叙事内容的创作者最熟悉这种痛:第一张图里主角穿蓝衣服,第二张变成了红色;侧脸和正脸看起来完全不像同一个人。每生成一张新图,就要重新祈祷"这次主角别换脸"。
Nano Banana 2在这次更新里,把单次工作流里的主体一致性提升到了支持最多5个角色、14个对象的水平。实测中,用一个穿着蓝色连帽衫的男孩作为测试主体,要求生成他在两个完全不同场景里的连续画面,实验室发现魔方,以及森林里举起魔方。两张图里,蓝色连帽衫的细节、男孩的面部特征,保持了高度的一致性。
prompt:
一张分屏式的电影分镜图(Storyboard)。左图:一个穿着蓝色连帽衫的10岁男孩在实验室里发现了一个发光的魔方。右图:同一个男孩(蓝色连帽衫,特征一致)在森林里举起魔方,魔方发出的光照亮了他的脸。画质要求:电影质感,冷暖对比色。

对游戏概念设计、儿童绘本创作、品牌吉祥物的多场景延伸,这是一个实质性的能力突破。
第四件事:图像编辑从"大概能改"变成了"精准手术"
传统的AI图像编辑,用"大概能改"来形容一点不夸张。你说"把西装换成皮夹克",模型可能连背景一起改了,或者把你的脸也顺便动了。
实测中,上传一张穿正式西装的照片,要求将西装换成皮质夹克、不戴领带、衬衫变白色、但西裤保持不变。
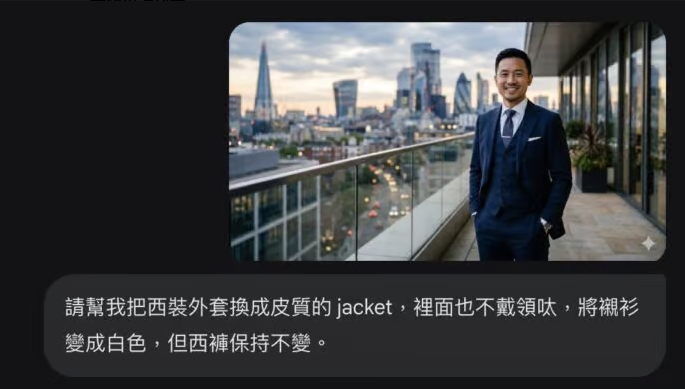
模型精准识别了肩膀与躯干的边界,新生成的夹克布料细节完全适应了原本的身体姿势,西裤和背景图案都没有被触碰。

更能体现"全局理解"能力的是场景扩展测试:上传一张近景咖啡杯特写,要求扩展画面展示巴黎塞纳河畔的露天咖啡座。Nano Banana 2不只是在旁边加了个背景,而是根据原图咖啡杯右上角打进来的阳光角度,推算出了整个新场景的环境光源方向,让扩展后的画面在光影上保持物理一致性。

那个"鱼和熊掌"的逻辑,为什么在这里失效了
Nano Banana 2的官方学名是Gemini 3.1 Flash Image,它的"升代"(从Gemini 3到Gemini 3.1)带来的架构改进,在某些维度上已经超越了上一代的旗舰Pro(Gemini 3 Pro)。就像手机芯片的迭代,新一代的中端芯片,在特定性能指标上超越上一代旗舰,是完全正常的结果。
与此同时,Pro版本的优势领域依然存在:在需要极致事实准确性和极端复杂光影处理的专业商业大片场景,Pro版仍然是首选。两者不构成竞争关系,而是覆盖了同一用户在不同任务类型下的需求。
定价的对比能更直观地说明这个分层逻辑:API端,Nano Banana 2的价格约为Pro版的二分之一,而在谷歌官方测评中,开启思考模式和搜索功能后,Nano Banana 2在整体偏好、视觉质量和信息图表准确性三个维度上,已经全面超越了Pro版。
用Pro版的成本,做Pro版的事。这个逻辑没有问题。但用一半的成本,做九成以上的事,这个逻辑才是Nano Banana 2真正改变的东西。
这件事对整个创作行业意味着什么
把这次发布放到更大的视野下来看,它动摇的是一个比"哪款模型更好"更根本的假设。
过去,AI生图的竞争逻辑是"谁的图更好看"。这个维度上,各家差距在快速收窄,用户体验也越来越趋同。在一个纯比视觉质量的市场里,领先优势很难维持。
但谷歌这次在做的事情,是把生图能力和更大的产品生态绑定起来——联网搜索、多语言处理、与Gemini知识库的整合、在Google Workspace和Google Ads里的原生嵌入。这些不是生图模型本身的能力,而是谷歌作为一个拥有全球最大搜索引擎和生产力工具矩阵的公司,才能真正兑现的护城河。
这意味着,当生图能力本身趋于同质化,竞争的下一个维度会是:谁能把生图能力更好地嵌入用户的实际工作流。
对于设计师来说,这个变化的含义很具体:你花在"调整提示词、处理错误文字、修复换脸问题、手动本地化素材"上的时间,正在被压缩。这些时间原本是你工作流里最枯燥、最低价值的部分。
结语
如果Nano Banana 2代表的方向成立,那么AI生图这件事的竞争维度,正在从"谁画得更漂亮"转向"谁更能听懂你在说什么、更能帮你解决真实问题"。
一个能准确画出21:35时钟指针的模型,一个能记住主角蓝色连帽衫细节的模型,一个能根据咖啡杯的光源方向推算整个新场景光影的模型,它解决的不是美学问题,而是可靠性问题。
对创作者而言,可靠性比美感更重要。一张漂亮但文字出错的海报,价值是零。一张稍微普通但所有细节都精确的海报,才能真正用起来。
