
全球第2!国产AI视频模型SkyReels-V4,今天让Sora知道了什么叫对手

你用AI工具做视频,有没有体验过那种具体的、反复出现的绝望:音频和画面对不上;想给主角换件衣服;文生视频、图生视频、视频编辑要用三个不同的工具,每切换一次创作思路就断一次;好不容易生成了,分辨率却拉垮,能看不能用。
这不是个别人的痛苦,而是整个AI视频行业绵延两年、从未被系统性解决的三道死穴:音画分离、工具割裂、质量与速度不可兼得。
行业的惯性认知早就固化了:AI视频嘛,能生成就不错了。创作者们普遍接受了这个现实,围绕着这三道死穴建立了自己的工作流:先生成视频,再手动配音,再用另一个工具修复,最后拼在一起。
但是SkyReels-V4来了,把这三道死穴同时凿穿了,顺带拿下了Artificial Analysis全球视频大模型现役榜第2名,把Veo 3.1、Sora 2全部甩在了身后。
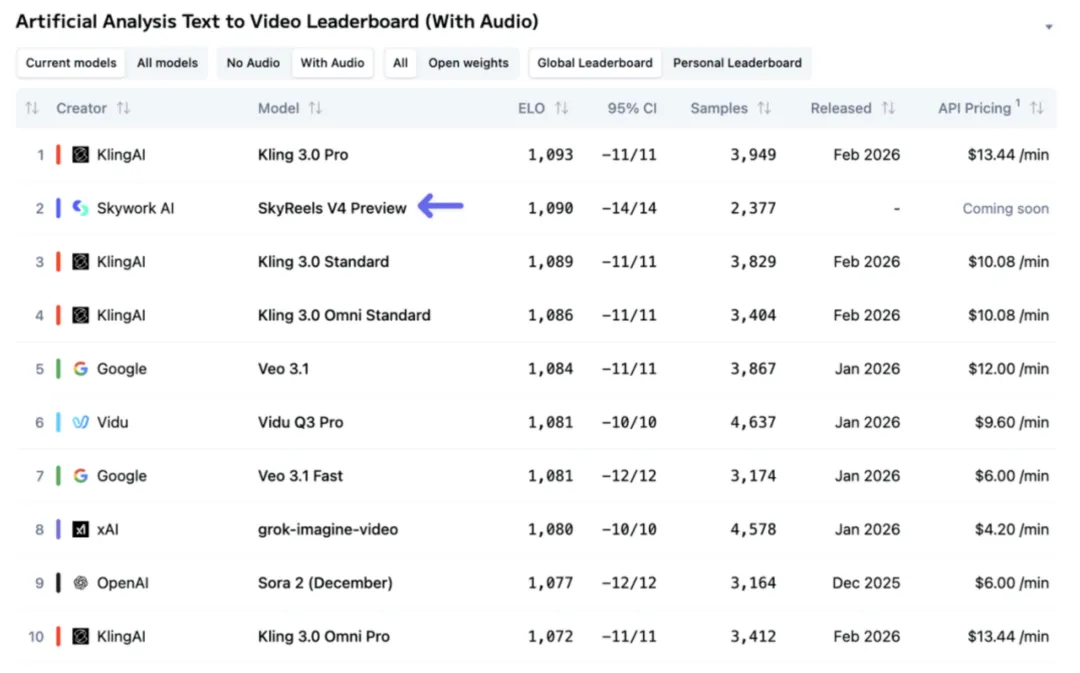
死穴一:音画分离,是整个行业的结构性bug
AI视频的音画问题,根源不在调参,在架构。
过去所有模型处理音频的方式,本质上都是"先拍电影、后期配乐"。视频生成完了,再把音频贴上去。两条流水线各跑各的,最后拼接。这就是为什么嘴型总对不上、音效总差半拍。不是模型不努力,是从一开始就走了两条不相干的路。
SkyReels-V4用双流MMDiT架构从底层改写了这个逻辑。
它给视频和音频各建了一条独立的处理通道,但这两条通道共用同一个多模态大语言模型编码器,并在每一个Transformer模块里都加入了双向交叉注意力机制。视频生成时参考音频节奏,音频生成时参考视频画面,两者从第一帧开始就互相引导、同步生长。
更精妙的是时间对齐的解法。视频是逐帧的,音频是连续波形,两者的时间尺度天然不一致。团队用RoPE频率缩放技术,把音频的时间编码精准调到与视频帧率匹配,实现了毫秒级同步。
实测中,一段包含台词、情绪、动作和木质桌面拍击声的短剧片段,嘴型与台词精准匹配,敲击桌子的声音真实到能听出材质,环境回音细节完整。这不是后期调出来的,是模型在生成时就原生输出的。
把音频从"外挂能力"变成"原生分支",这一步的意义,不亚于当年电影从无声片进入有声时代。
死穴二:工具割裂,是创作者效率最大的隐形杀手
一个典型的短剧创作团队的一天:文生视频用模型A,图生视频换模型B,去水印用工具C,风格迁移用工具D,最后剪辑拼在一起。每换一次工具,之前的创作信息清零,思路断一次,时间损耗一次。
不是单个工具不够好,而是流程本身在持续消耗创作者的精力。
SkyReels-V4的通道拼接+时序拼接双维统一框架,把这个问题从根上拆解了。
核心逻辑极其简洁:不管你想做什么:文生视频、图生视频、视频延长、局部编辑、去水印、删人物、风格迁移,本质上都是"给定已知内容,生成未知部分"。区别只在于掩码的配置方式。
文生视频,掩码全为零,从头生成;图生视频,首帧掩码锁定参考图,后续帧自由生成;局部编辑,要保留的区域掩码为1,要修改的区域掩码为0。模型只动你指定的部分,其余一切保持原样。
实测:给女团舞蹈视频的C位舞者戴上一顶指定款式的帽子,帽子颜色与logo与参考图完全一致,整段舞蹈重新跳了一遍,其他人物与背景未受影响。


更进一步:同时输入两张角色参考图、一段舞蹈参考视频、一段背景音频参考。模型听懂了所有输入,把角色的毛色体态、舞蹈动作节奏、音频卡点全部融合进同一段输出,一次生成,不需要任何后期拼接。


一个工具,全部搞定。这才是工作流层面的真正突破。
死穴三:质量与速度的不可能三角,被工程解法绕过去了
1080p、32帧、15秒的影院级视频。一年前,单是这个规格的计算量就能让大多数团队望而却步。高清要等,要流畅就得忍受马赛克,这个"不可能三角"被当作AI视频的物理限制接受了太久。
SkyReels-V4的工程解法不是硬堆算力,而是换了一套生成策略:先快速生成低分辨率完整序列,再单独生成高分辨率关键帧,最后用超分辨率和帧插值模块补细节、优化过渡。
与此同时,自研的视频稀疏注意力(VSA)机制把长序列注意力计算压缩到原来的约三分之一,计算量下来了,生成速度上去了,最终画质稳定在1080p影院级水准。
这不是参数游戏,是实实在在的工程权衡:在不降低最终画质的前提下,找到计算资源分配的最优路径。
为什么这次不一样:从"能生成"到"能用",是一道质变的门槛
把这三个技术突破放在一起看,会发现它们指向同一件事:AI视频正在越过一道门槛,从"能生成"迈向"能用"。
这两件事,差距比表面看起来大得多。
- "能生成"意味着模型在理想条件下能输出漂亮的结果,但创作者要围绕模型的限制设计工作流,接受音画错位、工具切换、质量妥协。
- "能用"意味着工具真正服务于创作者的需求,一次输入多种素材、一个工具完成全流程、输出质量达到可直接交付的水准。

SkyReels-V4越过这道门槛的方式,值得认真对待:不是靠堆参数,而是靠架构级的重新设计。音视频原生统一、任务框架底层统一、生成策略工程化优化。这三件事,昆仑天工从多模态底层能力积累阶段就开始布局,SkyReels V1到V4的每一代,都是在同一条技术路线上的持续收束,而不是追热点的方向漂移。
这种技术路径的连贯性,在国内AI视频赛道里相对稀有。
当然,它目前也有边界:更长序列、更高分辨率(4K乃至8K)、跨语言的复杂音视频协同,团队自己也承认还在路上。这不是缺陷,而是任何处于快速迭代阶段的模型都会面对的现实。

对创作者的实际影响:哪些工作流需要重新想一遍
基于上述分析,这里有几个可以立即检视的判断框架:
重新评估你的后期流程。 如果你目前的视频工作流包含"生成→手动配音→修复→拼接"这个链条,每一个环节的切换成本都值得重新计算。SkyReels-V4把这条链条压缩进了一个工具。
识别你真正的时间黑洞。 列出上个月因为音画不同步、工具切换、局部修改导致重来的具体次数。这些不是"AI的局限",是已经有了工程解法的具体问题。
多模态输入是新的提示词。 你现在拥有的素材:参考图、参考视频、音频片段都是可以输入的条件,而不只是参考。重新想一想你手边的创作素材库,能组合出什么。
把"去水印、删人物、风格迁移"纳入创作工具而非后期工具。 这些能力现在不需要专业软件,不需要换工具,一句自然语言指令就能调用。
结语
AI视频这件事,从来不缺漂亮的演示。缺的是真正能用的工具:能听懂复杂输入、能在同一个工作流里完成创作到交付的全链路、能输出直接用得上的质量。
SkyReels-V4用全球第2的成绩说明,这件事,有人做到了。
它解决的那三道死穴:音画分离、工具割裂、质量与速度的不可能三角。每一道都是创作者在真实工作里每天遇到的具体障碍,而不是测评机构才关心的参数指标。
