
腾讯纯文本LLM训视觉encoder,拿捏图表长视频,达到开源小模型SOTA!


打破多模态视觉+语言拼接套路!
腾讯开源Penguin-VL,直接用纯文本LLM训视觉编码器。

这项研究跳出了先有传统视觉 backbone,再接语言模型的常规路径,直接从text-only LLM初始化vision encoder。
并在2B/8B紧凑参数规模下的文档理解、长视频时序定位等复杂任务中表现出极强竞争力。
从LLM出发的视觉编码器重构
如果把这两年的多模态模型拆开看,一个很有意思的现象是:
大家在语言模型上卷得很凶,但到了vision encoder这一层,路线却出奇一致。
很多VLM最后都会回到那套熟悉配方,先拿CLIP、SigLIP这类通过对比学习训出来的视觉模型做encoder,再接上LLM往下训。
这条路线当然强,也足够成熟。
但Penguin-VL团队想问的,不是“这条路能不能走”,而是“它是不是复杂视觉理解最合适的起点”。
因为对比学习最擅长的,本来就是判别、检索和图文匹配。
它会主动把图像压进一个更适合分类和对齐的语义空间里。
可一旦任务变成文档阅读、图表理解、细粒度描述、多图关系判断,甚至长视频里的时间定位,模型真正需要保住的,恰恰是那些不该太早被抹平的局部结构、空间关系和时序细节。
换句话说,Penguin-VL重新盯上的,不是VLM里最显眼的LLM,而是那个最容易被默认的vision encoder。
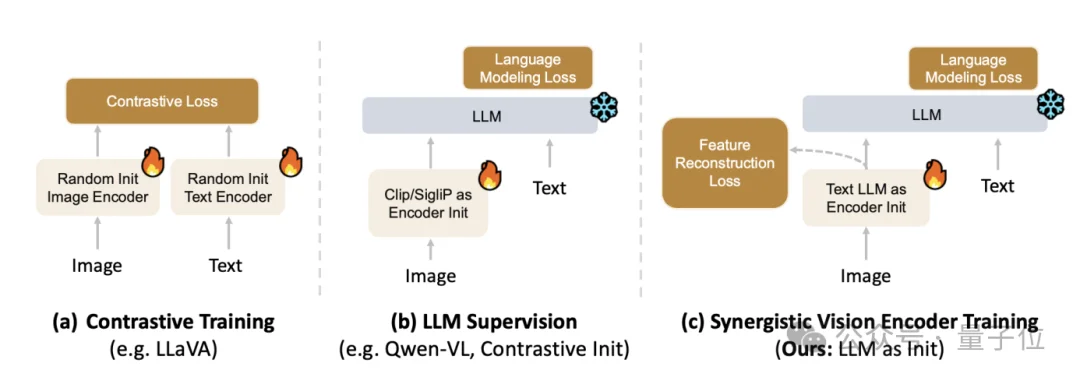
上图中对比了三种vision encoder训练范式。
主流contrastive路线先把视觉模型和文本模型分别训好,再在VLM中使用;
直接LLM supervision会把视觉特征硬对齐到冻结的LLM;
Penguin-Encoder则直接从text-only LLM初始化,再通过视觉训练把它真正变成视觉编码器。
Penguin-VL给出的答案有点反常识,既然最终要和语言模型协同推理,那vision encoder为什么不能直接从LLM出发?
于是,论文里提出了Penguin-Encoder。
它不再默认从传统视觉backbone初始化,而是直接从text-only LLM起步。
这里的关键不只是“借一套参数”。
Penguin-Encoder继承的是一整套更适合序列建模的能力和架构基础。
它和下游LLM的表示空间更近,视觉和语言之间不必再跨一道特别大的鸿沟;
还复用了attention、FFN、GQA、RMSNorm等已经训练成熟的模块,不需要从零再学一遍“上下文怎么组织、顺序怎么建模”;
更重要的是,语言模型已经学会的顺序建模和因果逻辑能力,也给视觉理解提供了一个更强的起点。
对Penguin-VL来说,这意味着vision encoder学的,不再只是“把图像压缩成向量”,而是“怎么把视觉概念接到一条已经成熟的语言推理链路上”。
当然,LLM不能直接原封不动拿来当vision encoder。
Penguin-VL做了两处关键改造。
一是把原本服务文本生成的causal attention改成更适合视觉建模的bidirectional attention;
二是引入2D-RoPE,让模型能更自然地处理图像和视频里的二维位置信息。
也因此,Penguin-Encoder不是简单把LLM“拼”进视觉模块,而是以LLM为初始化起点,再通过面向视觉的训练,把它真正训成一个vision encoder。
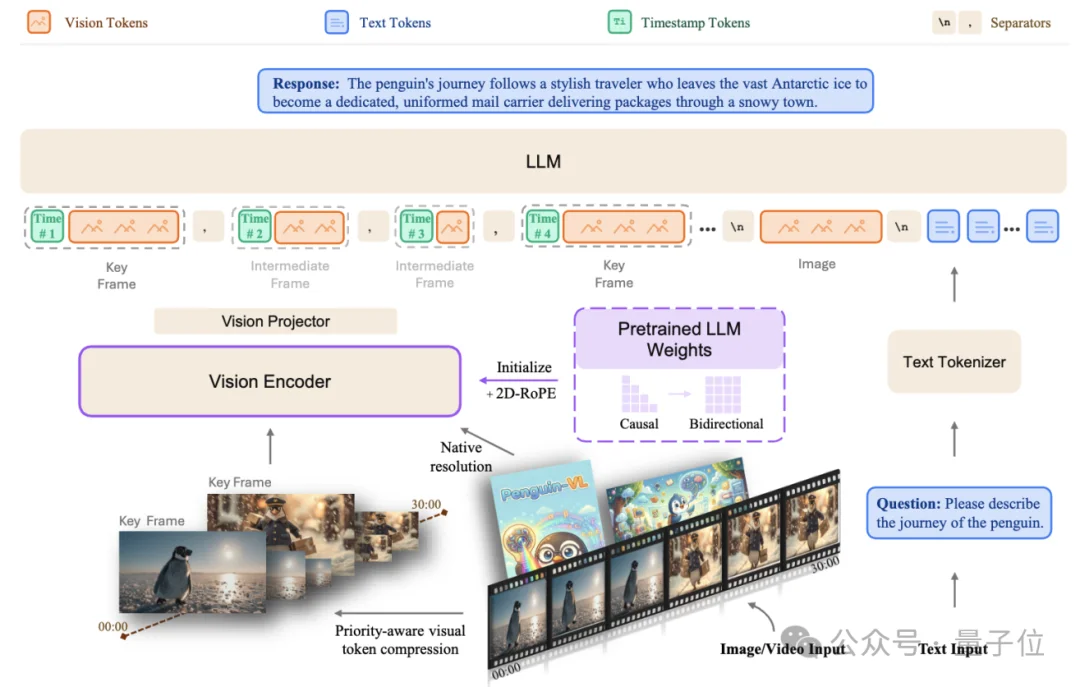
上图展示了Penguin-VL的整体架构。
由LLM初始化的Penguin-Encoder、MLP projector与语言模型组成。
视觉侧引入2D-RoPE和bidirectional attention,并通过统一token流处理图像与视频;
在长视频场景中,再配合TRA策略优先保留关键帧信息。
三阶训练与性能验证
训练部分也不是一步到位硬推,而是拆成了三阶段。
Stage 1先训练Penguin-Encoder本身,走一条低分辨率预训练到高分辨率fine-tuning的路线,让模型先稳住视觉表征,再逐步把细节拉起来。
论文里专门引入reconstruction和relation loss,核心目的很明确——
别让图表、文档这类结构化视觉信息太早丢掉。
Stage 2是VLM pre-training,让encoder、projector和LLM 一起进入完整的多模态知识学习。
Stage 3则是supervised fine-tuning,把能力真正对齐到用户任务。
视频部分还有一个很实用的设计TRA,也就是Temporal Redundancy-Aware token compression。
它不是把所有视频帧一股脑塞进同样的token预算里,而是优先把预算留给关键帧,尽量少在冗余中间帧上浪费上下文。
说白了,Penguin-VL想做的不是“看更多”,而是“把真正重要的时序信息尽量留下来”。
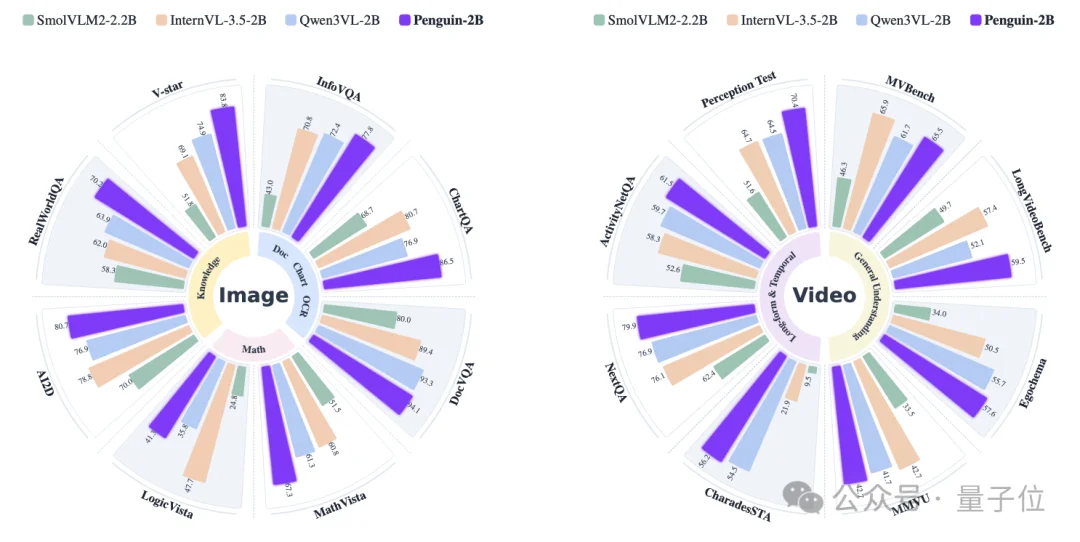
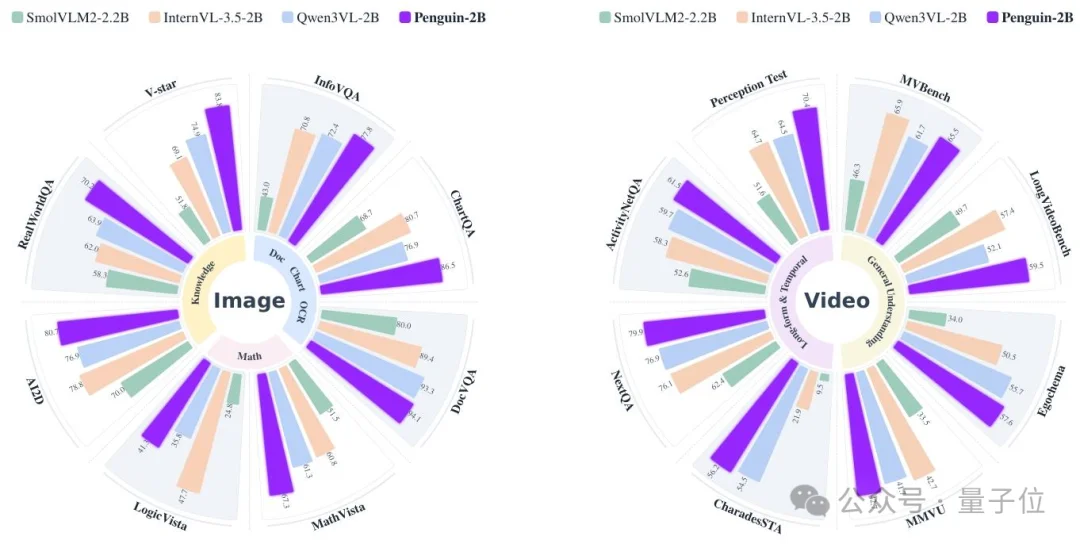
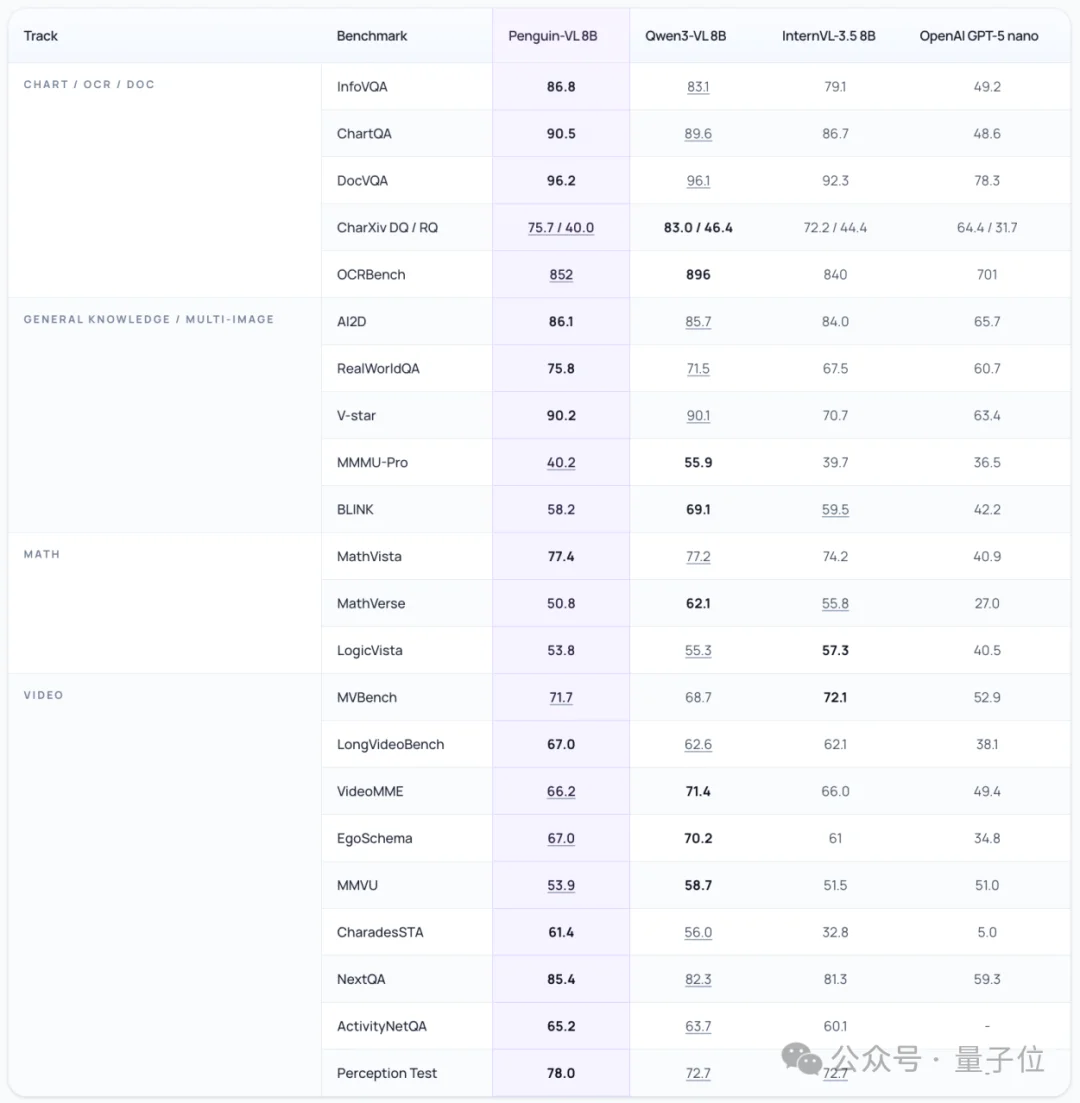
从上图可以看出,在2B/8B这样相对紧凑的参数规模下,Penguin-VL在文档理解、图表理解、视觉知识和长视频理解上都拿出了很有竞争力的表现。
比如2B模型在 InfoVQA、ChartQA、DocVQA、V-star、LongVideoBench、NextQA、Perception Test等任务上都很亮眼。
它想传达的信息不是“模型再做大一点就行”,而是vision encoder的起点如果选对了,小得多的模型也能把关键视觉信息保下来。
如果说2B更像是在有限参数规模下证明这条路线可行,那么8B就是在更完整的模型配置下,把同样的趋势继续拉清楚。
8B版本在InfoVQA、ChartQA、DocVQA、AI2D、RealWorldQA、V-star、LongVideoBench、NextQA、CharadesSTA、Perception Test等任务上继续保持很强的表现。
尤其在文档理解、视觉知识和长视频理解上,优势模式更加稳定。
8B版本延续了Penguin-VL在文档理解、视觉知识和长视频理解上的整体优势。
这说明围绕vision encoder重设计的路线,并不是只在小模型上偶然奏效。
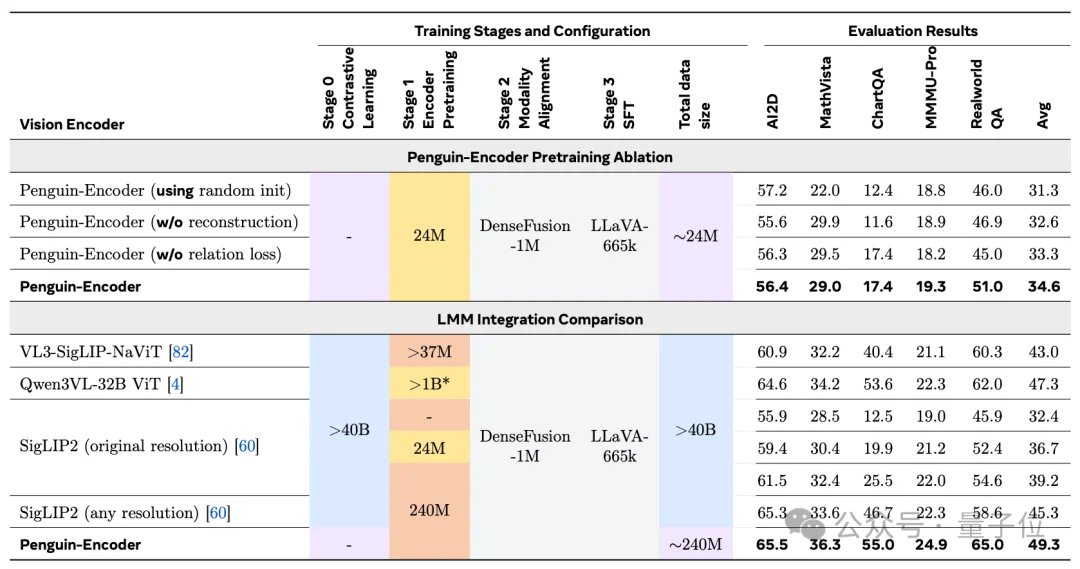
不过,真正把这篇工作钉住的,还是encoder实验。
论文里的ablation很直接:在同样的轻量流程下,随机初始化的Penguin-Encoder平均分是31.3;
换成LLM初始化并加入完整训练配方后,平均分提升到34.6。
进一步在encoder integration comparison中,Penguin-Encoder做到49.3平均分,而且只用了约2.4亿Stage 1样本,就超过了多种依赖更大规模对比学习预训练的视觉编码方案。
换句话说,这篇工作真正想证明的,不只是Penguin-VL这个模型“做出来了”,而是LLM-init vision encoder这条路,本身就是成立的。
从这个角度看,Penguin-VL 的意义,其实不只是一组benchmark分数。它更像是在提醒大家:
过去那条“先有传统视觉backbone,再去接语言模型”的路径当然依然有效,但它未必是唯一答案。
未来的 vision encoder,也许不一定非得来自传统视觉模型,也可以从更通用的语言模型出发。
某种程度上,这也与近期DeepSeek-OCR2等工作呈现出的趋势有些相通。
大家似乎都在慢慢跳出那条已经非常熟悉的多模态拼接路线,开始探索一种更原生、更统一的建模方式。
项目相关代码、模型和交互式体验现已开放。
感兴趣的朋友可戳链接了解更多内容~
GitHub地址:https://github.com/tencent-ailab/Penguin-VL
论文地址:https://arxiv.org/abs/2603.06569
2B模型:https://huggingface.co/tencent/Penguin-VL-2B
8B 模型:https://huggingface.co/tencent/Penguin-VL-8B
Penguin-Encoder:https://huggingface.co/tencent/Penguin-Encoder
Hugging Face Space试玩:https://huggingface.co/spaces/tencent/Penguin-VL
文章来自于“量子位”,作者 “Penguin-VL团队”。
