

全球榜单炸场!MiniMax M2.5连夺五周冠军,中国AI调用量碾压美国,到底凭什么?

近日,在全球最大的模型平台OpenRouter上,国产大模型MiniMax M2.5连续五周霸榜全球调用量冠军。
不仅如此,中国AI的整体周调用量,已经连续两周超越美国,中国模型彻底终结了美系长达一年的主导地位。
这不仅是一次榜单更迭,更是一场产业大洗牌。
面对全球AI行业的激烈厮杀,中国大模型是如何在短短几个月内实现反超的?在这场看不见硝烟的战争中,中国AI企业究竟掌握了怎样的武器?
塔猴经过深度复盘与数据拆解,为你揭开这场屠榜背后的底层逻辑。

连续两周碾压美国
这并不是中国大模型第一次冲上高位,熟悉榜单的人可能知道,这场逆袭早就悄然开始。
为了看懂这份成绩单的含金量,我们需要先了解一下OpenRouter。简单来说,OpenRouter就像是大模型界的Steam游戏平台,它为全球开发者提供统一的API接口,无论是美国的GPT-4、Claude,还是中国的MiniMax、DeepSeek,都在这个货架上同台竞技。在这里,没有任何品牌滤镜,只排Token调用量。Token是AI处理数据的基本单位(可以理解为一个字、一个词根或一个符号)。几万亿的Token,意味着全球无数个程序、网页、APP每天都在疯狂向中国服务器发送请求。
根据OpenRouter最新披露的周榜数据,中国大模型正在形成对美系AI的碾压。
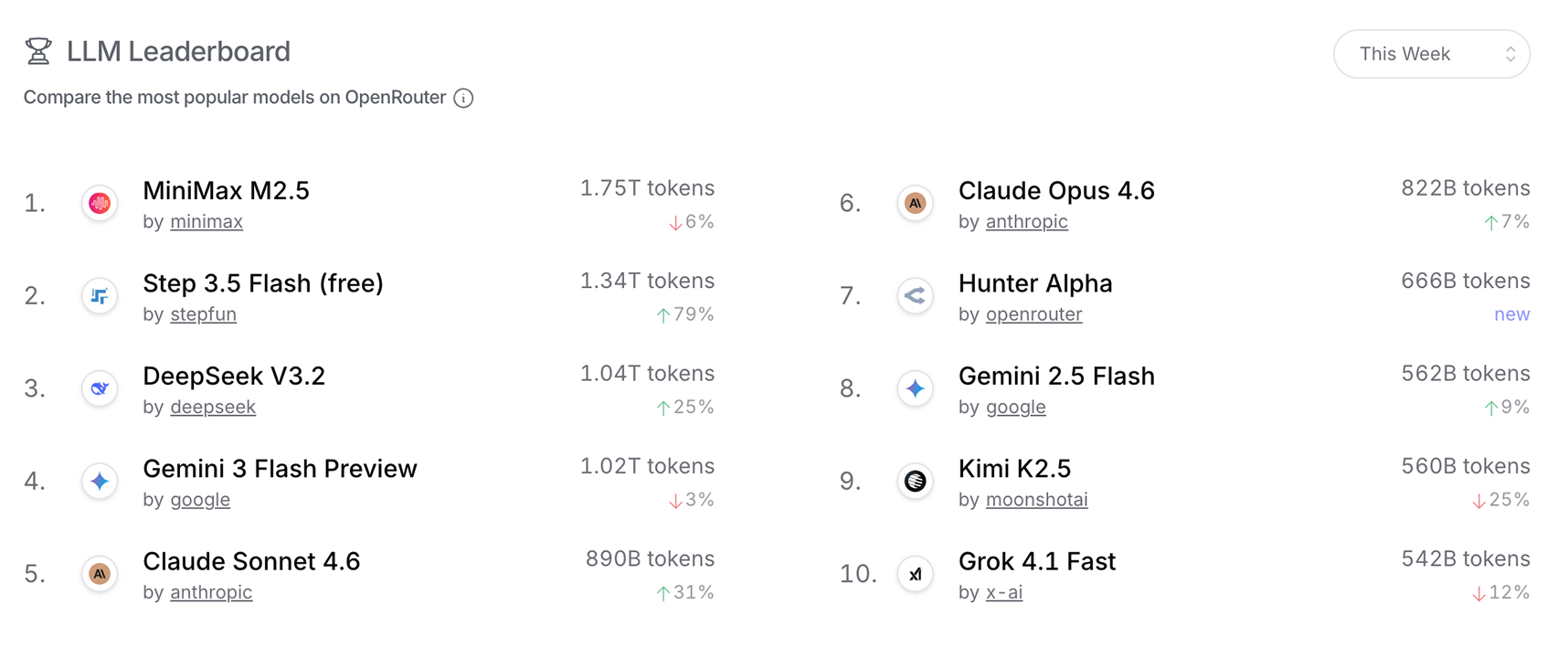
3月9日至15日,中国大模型的周调用量上升至4.69万亿Token,而美国大模型则下滑至3.294万亿Token。这并非偶然,早在2月9日至15日,中国AI模型就以4.12万亿Token的成绩,历史首次超越了美国模型的2.94万亿Token。到了2月16日至22日,中国更是升至5.16万亿,将美国的2.7万亿远远甩在身后。
更恐怖的是头部榜单,在上周的Token调用量前三名中,中国大模型完成了包揽。
- MiniMax M2.5:周调用量达1.75万亿Token,连续五周蝉联全球榜首。
- 阶跃星辰Step 3.5 Flash:周调用量1.34万亿Token,环比暴涨79%。
- DeepSeek V3.2:周调用量1.04万亿Token,环比增长25%。
在最高峰时期,中国模型一度占据了OpenRouter前五总量的85.7%。这不仅震撼了国内,也引发了海外媒体的密集关注,《南华早报》在近期的报道中直言:“中国模型终结了美系开发者长达一年的市场主导地位。”
这已经是国际市场达成的普遍共识,中国大模型,已经真正意义上走进了世界舞台中央。

海外被卷到怀疑人生
为什么全球开发者都选择国产模型?是我们的技术甩开美国几条街了吗?
其实原因很简单,又强又便宜,开发者好用。
性价比,是中国大模型现阶段打开全球市场最强武器。MiniMax研发团队在受访时毫不避讳地指出,目前产品最核心的竞争力在于价格:“达到同样能力水平的海外模型跟我们相比,价格可能有十几倍的差距。”
让我们直接拿OpenRouter上的公开定价来算一笔明账。目前,MiniMax M2.5的输入定价约为0.20美元/百万Token,输出定价为1.17美元/百万Token。作为对比,Anthropic的Claude Opus等美系头部模型,定价在5美元到25美元/百万Token之间。
这是整整20倍以上的价差!更别提阶跃星辰等国内厂商还推出了免费的Flash版本。
为了让大家有更直观的体感,我们代入一个场景:假设美国有一个初创的网文搬运团队,每天需要调用API来翻译和校验约1000万字的网文小说。如果他们接入美国头部的闭源模型,一天光调用费就需要几百上千美金,一个月下来光调用费就能拖垮公司的现金流。
但如果他们一键切换到MiniMax M2.5呢?一杯星巴克咖啡的钱,就能搞定全天的运算量。这种账,是个人也算得明明白白。在商业化变现的巨大压力下,好用又便宜才是硬道理。
这套商业中国人太熟悉了。回顾过去二十年的出海史,从“小米模式”横扫东南亚与欧洲,到如今“比亚迪们”在海外大杀四方,不是海外产品用不起,而是中国制造更有性价比。
如今,这套战术被完美复制到了大模型赛道。中国AI企业不执着于参数,而是卷价格,把海外大厂卷到飞起。

基建红利
这种价格优势,难道是中国企业靠“赔本赚吆喝”砸出来的吗?
当然不是。大模型的竞争,本质上是算力与能源的消耗战。低价的背后,隐藏着中国企业科学的成本控制能力。
首先是底层架构的创新,在技术端降本。低价绝不是简单的商业让利,MiniMax等国产团队通过优化底层架构(如MoE的深度调优),实现了模型效率的质变。过去模型办一件事、回答一个复杂问题,需要全脑启动,消耗10个Token;现在通过创新的架构,模型只需要激活部分大脑,5个Token就行,让每一个Token都变得更值钱了。
其次,是能源与基建优势,在物理端降本。AI的尽头是电力,在智算中心里的成本里,电费的占比高达70%到80%。美国虽然在高端AI芯片设计上握有霸权,但其老化的电网系统、昂贵且不稳定的商业电价,正制约者AI大规模落地。反观中国,拥有全球最庞大、最稳定、调度能力最强的国家电网基建,以及相对低廉且充足的工业电价。

中国电网庞大、低成本的基建网络,为中国AI企业筑起了一道海外竞品难以逾越的防火墙。这种国家级基建带来的红利,任何海外企业都无法靠自身力量抹平。

性能对标
当然,如果只有便宜,绝对留不住人。大模型赛道不相信眼泪,只相信跑分和实效。
中国大模型之所以能实现调用量的持续霸榜,根本原因在于我们已经撕掉了“廉价平替”的标签,全面接管了生产力场景。
在性能上,国产模型已经稳稳站上SOTA(当前最佳水平)的第一梯队。据MiniMax官方及多方开发者实测反馈,M2.5在极其考验逻辑的编码、复杂信息检索以及高阶生产力任务上,已经完全可以媲美Anthropic和OpenAI的顶级模型。更值得一提的是,M2.5提供了高达196K的超长上下文窗口。这种能力,足以支撑目前最复杂的智能体开发,满足企业级用户的需求。
性能的跃升,让国产AI全面爆发。在国内市场,企业级AI需求正在指数级狂飙。数据显示,国内企业日均Token使用量,从2025上半年的10.2万亿,直接飙升至下半年的37万亿,暴涨了263%!在国际市场,开源、低价且迭代极快的中国模型,正渗透进全球数以百万计的AI应用中。OpenRouter全球开发者大量采用中国模型,中国模型一度占据该平台61%的惊人份额。
更令人振奋的是国产AI的阵容深度。
在上周排名前十的榜单中,除了我们熟知的MiniMax、阶跃星辰、DeepSeek和月之暗面外,一款名为“Hunter Alpha”的神秘模型新晋入榜,单周狂揽0.666万亿Token,杀入第七。据披露,这是一个拥有1万亿个参数、100万个Token上下文的前沿智能模型,专为智能体应用而构建,擅长长期规划和多步任务执行。
这种百花齐放的态势说明,中国大模型不仅头部能打,腰部和新兴力量同样在持续输出。这不再是几家大厂的单打独斗,而是整个中国AI生态体系的全面崛起。
关注塔猴公众号,回复“1”加入专属社群
扫码下载塔猴APP,查看更多干货

