

当Agent可以代替大部分的人类,人类核心壁垒究竟还剩下什么?



过去的一两年里,AI生成视频的浪潮几乎席卷了每一个内容平台。
那些画面精美、转场华丽的AI短片和商业TVC,总会给人一种技术已经无所不能的错觉。
但只要你真正下场制作过一条哪怕只有几十秒的AI视频,就会体会到一种难以言喻的疲惫与割裂:
你需要在一堆网页间来回跳转,用语言大模型写脚本,去图像平台反复抽卡定角色,再把拆盲盒般得到的动态片段塞进剪辑软件里缝缝补补。
在这个看似前卫的创作流程中,人类创作者其实更像是穿梭在不同系统间搬运数据、修补BUG的流水线工人。
哪怕只是想把主角衣服的颜色换一下,整个流程可能都要全盘推翻重来。
创作的灵感和激情,往往就在这种漫长且无意义的跨平台消耗中消磨殆尽了。
我们习惯性地期盼着某个界面更简单的软件出现,好让人类点鼠标的时候能轻松一些。
直到前段时间,我受邀参与了LiblibAI筹备已久的神秘项目内测,我才意识到,过去行业的解题思路可能全错了——我们为什么非要纠结于让人类去适应软件?
既然AI已经进化出了理解与执行的能力,为什么不能给AI开一扇门,让Agent(智能体)自己去操控软件?
直到2026年3月18日,这款名为 LibTV 的产品正式发布。

在深度使用了几天之后,我可以给出一个相对客观的结论:
它是现阶段市面上最适合专业创作者的AI视频工具。
这不仅仅是因为它集成了当下最顶级的模型算力,更是因为它颠覆性地采用了双入口设计。
它不仅为人类提供了一个用来统筹全局的无限画布,更是世界上首个原生为Agent(比如小龙虾OpenClaw、Claude Code等)提供专属控制接口(Skill)的视频创作平台。
当我在内测中,看着我的Agent(龙虾)在微信里自动根据我给的脚本去生成一只完美的视频后,我感受到了一种复杂的平静。
这也是我写下这个标题的原因:
当一款为Agent设计的平台真正出现,当繁杂的执行工作被机器彻底接管,剥去所有技术壁垒的伪装后。
人类创作者最后能握在手里的底牌,大概真的只剩下审美了。
PART.01 人类在LibTV:无限画布
在讨论Agent之前,我们有必要先审视一下人类在LibTV里的操作界面。
长久以来,AI视频工具的界面大多是一条线性的时间轴,或者干脆就是一个简单的对话框。
创作者把提示词扔进去,剩下的全凭运气。
LibTV放弃了这种开盲盒式的交互,它给人类创作者提供的是一块无限延展的画布。
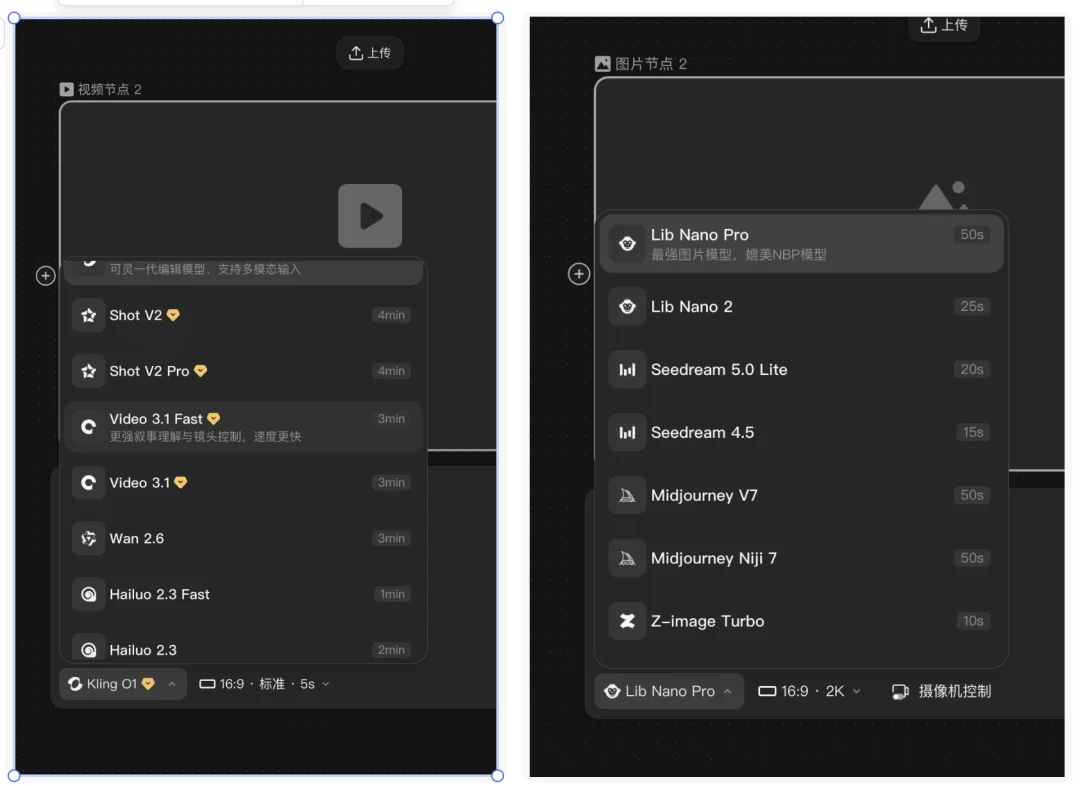
在这块画布上,文本、脚本、图片、视频、音频这五种基础节点被具象化了。
它们不再是散落在电脑各个文件夹里的孤立素材,而是可以通过连线相互咬合的齿轮。
你可以清晰地看到一条工作流是如何建立的:
左边的角色设定文本,连线生成了中间的角色三视图,再向下延展出多条不同机位的分镜视频,旁边还挂着全局的旁白与配乐。
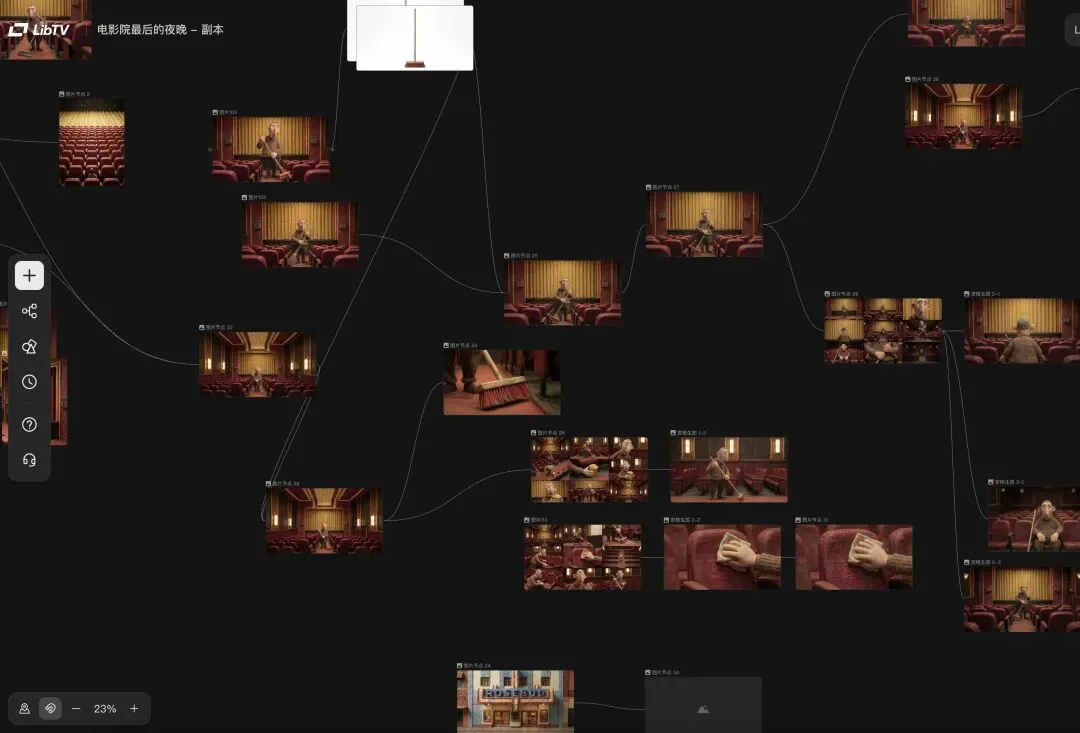
对于普通用户来说,复杂的节点连线或许会带来一定的认知门槛,但对于专业的影视从业者而言,这种系统级的复杂度恰恰是他们一直渴望的武器。
在内测中,LibTV展现出了一种对影视工业常识的尊重。
比如,过去我们控制画面,只能在提示词里堆砌电影感、侧光、85mm镜头这样含糊的词汇。
而LibTV直接在界面里映射了物理世界的摄像机与灯光系统。
你可以像操作真实的单反一样去调整焦距与光圈,或者拖动虚拟的光球,给画面加上一个右侧50%亮度的轮廓光。
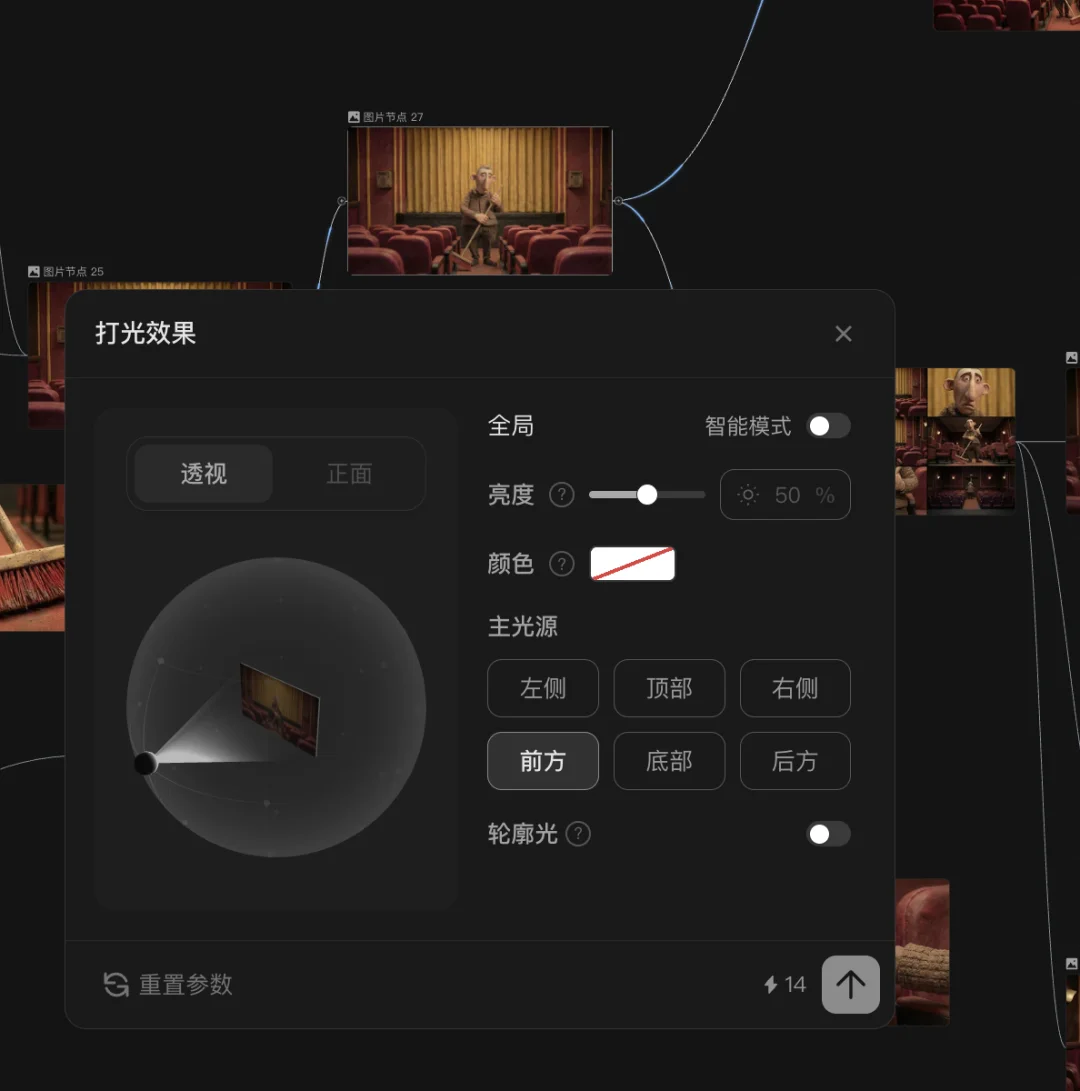
它甚至引入了传统剧组里的场面调度逻辑——你可以用一句话生成9宫格或25宫格的机位推演图。
当你发现某一个俯拍视角的构图恰到好处时,直接使用网格切分功能将那一格提取出来,作为下一个镜头的视觉锚点。
结合强制锁定人物特征的角色三视图功能,AI视频最让人头疼的连贯性问题,终于在工作流的源头得到了系统性的控制。
在内测期间,我看到一位名叫毕加索隆的创作者利用这套画布完成了短片《索拉里斯之船》。
在极其繁杂的节点网络中,他完成了对每一个素材的高清扩图、局部重绘、多角度反推和视频生成。
整张画布看起来像是一张精密的电路图,这才是专业制片该有的颗粒度。
PART.02 AI在LibTV:Agent
如果LibTV仅仅停留在上述的画布功能,它充其量只是一个更懂影视工业的AI创作软件。
但它最令我感到震撼,甚至有些后怕的设计,是它为软件开辟了真正的第二扇门。
过去二十年,所有软件的迭代都在研究一件事:
如何让人类点击鼠标更加顺畅。
但LibTV从产品构架的第一天起,就为互联网上游荡企且数量指数级增加的Agent保留了平等的访问权限。
就在昨天,微信官方开启了微信ClawBot插件的灰度测试,允许用户直接在微信里接入个人的OpenClaw(小龙虾)。
借着这个契机,我完成了一次极具赛博朋克感的创作体验:
在微信的聊天框里,指挥一座制片厂。
推开这扇门的钥匙获取异常简单。
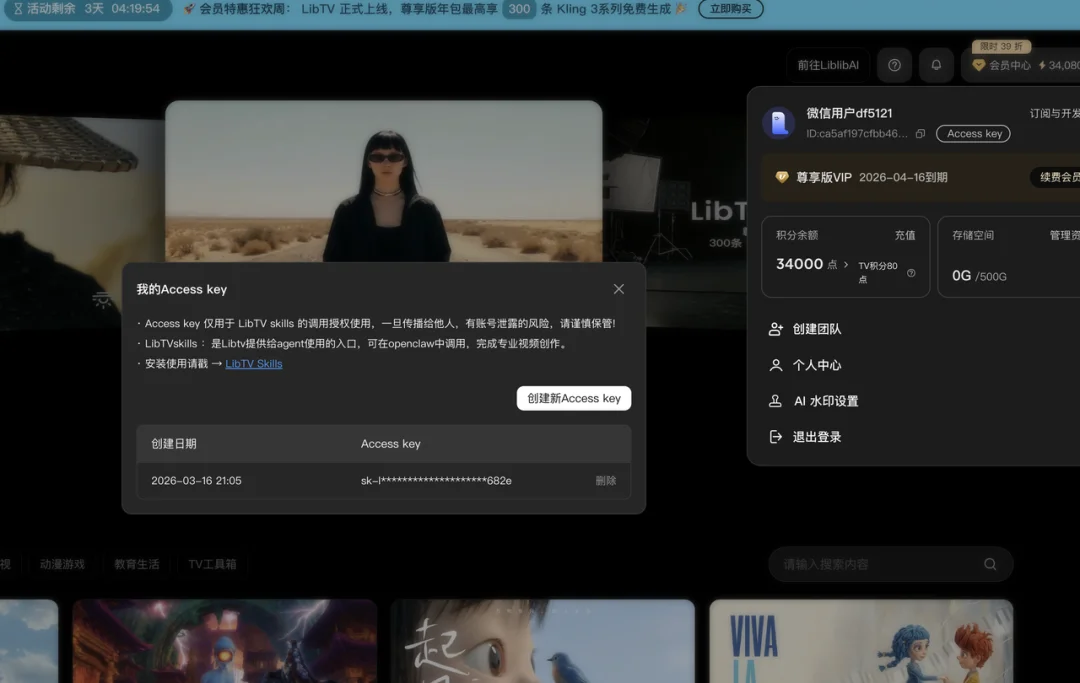
在LibTV的网页端设置中,我生成了一串专属的 Access key。
完成授权后,我打开了微信里与 ClawBot 的对话框,像给现实中的助理派活一样,扔进去了三张我自己随手拍的充电宝照片。
并附带了一句极其口语化、甚至有些抽象的要求:
帮我用这三张图里的充电宝做一个 Apple 风格的宣传片,要 30 秒哦。

随后发生的运转过程,彻底打破了我对使用软件的固有认知。
我没有打开LibTV的网页,没有建立任何节点,更没有去纠结什么是Apple 风格的参数。
跑在背后的小龙虾,通过安装好的 libtv-skills,不仅一口气吃下了这三张图,还极其专业地将我这句外行的话,拆解成了工业级的执行指令。
它在微信里冷静地回复我,它已经明确了重点:
白/浅灰纯净背景、产品悬浮感、缓慢推进与环绕运镜、避免廉价电商风……
它甚至从我那几张随手拍的照片里,精准提取出了黑色面板、金属边框、折叠结构、20W标识、背部磁吸圈等所有物理细节。
随后,它自己分配了生图和视频模型,开始了漫长的生成排队。
它甚至像一个成熟的制片助理一样贴心地嘱咐我:你过几分钟再问我一句‘现在怎么样了’,我继续帮你盯进度。
在当前的算力下,一条高质量的AI视频往往需要十几二十分钟的等待。
但在这个过程中,你不再需要像过去那样死盯着屏幕上焦虑的渲染进度条。
当一杯咖啡喝完,微信叮地响了一声,成片出炉了。

但这并不是终点,而是人机协作真正精妙的开始。
在微信对话框里,Agent不仅返还了一个可以直接播放的视频链接,还会附带一个极其重要的东西:
LibTV Project 链接。

这是一个极其关键的产品哲学。
如果你发现视频的某个画面不符合预期,或者发现 Agent 偷懒只给了成片却没有保留过程。
你不需要去修改代码,你只需在微信里用自然语言训斥它一句:你的节点是空的,重新创建工作流,要把结果也都放到节点里。
或者直接命令:重试创建整个工作流放在画布上。
Agent 会立刻乖乖地将后台的隐形逻辑具象化。
当你点击微信里的那个 Project 链接,跳转回 LibTV 的无限画布时,你会看到令人头皮发麻的一幕:
刚刚 Agent 在后台思考的全部痕迹。
它是怎么写分镜的,数百根逻辑线是怎么排布咬合的,那个20W标识的特写参数是如何设置的,全都历历在目。
这正是未来人机协作的默认形态:
Agent 负责在后台干所有的脏活累活,承担节点连线、模型调度与指令拆解,跑出一个 70 分的初稿;
而人类,则端坐在监视器(画布)前,接手剩下 30 分的精修。
机器负责苦力与规则,人类负责审美与微调。
在这个极其日常的微信对话场景里,你甚至会产生一种错觉:
你不再是一个软件的用户,而是一个只需发号施令、便拥有着不知疲倦的制片团队的赛博导演。
PART.03 给予创作试错权
我们常常说,AI时代的创作终局是审美。
但审美的残酷之处在于:
审美,是建立在有得选的基础之上的。
如果你只能拍一条素材,那叫记录;
如果你能在一百条不同的素材里,挑出光影最对、情绪最饱满的那一帧,那才叫导演的审美。
每一个AI视频从业者都心知肚明,当下的生成技术本质上依然是一个对抗概率的游戏。
即使参数调得再精准,模型依然可能生成出物理规律崩塌的废片。
一部真正的好作品,往往是由几十上百个被废弃的镜头喂出来的。
但在算力极其昂贵的今天,每一次生成都是真金白银的消耗。
很多时候,创作者并不是缺乏好品味,而是高昂的容错成本逼迫他们只能妥协。
当预算只够生成5次时,你只能在5个平庸的镜头里,挑一个相对不那么糟糕的。
高昂的算力成本,正在悄无声息地锁死人类的创作上限。
LibTV 显然看透了这个死结。
在它的无限画布背后,其实隐藏着一个庞大且极其暴力的模型 Hub:
可灵3.0/O3、Wan 2.6、Lib Nano Pro,以及官方承诺即将独家接入的顶级模型 Seedance 2.0,全都汇聚于此。
但它真正反常的地方,是对待算力定价的克制。
根据官方公布的数据,在叠加权益后,LibTV 的综合算力成本几乎被强行压到了市面同类产品的两到三成;
其模型积分的定价,甚至比某些竞品低了九成。
针对订阅用户,平台直接白送了包含 150 条可灵 O3 和 150 条可灵 3.0 在内的 300 条最高等级视频额度。
在一篇讨论产品逻辑的文章里,去罗列这些折扣数据似乎有些俗气。
但对于真正的创作者而言,低廉的算力成本,本身就是现阶段最核心的功能。
同样的预算,过去你只能试错 10 次,现在你可以试错 80 次。
这多出来的 70 次机会,就是人类探索视觉边界、捕捉偶然灵感、最终将极致审美落地的容错空间。
LibTV 实质上是在用近乎底价的算力补贴,替创作者垫付了那张前往未知领域的门票。
当试错不再让人肉疼,绝不凑合的创作才有了发生的可能。
PART.04 审美是不是最后一个壁垒?
在长达几周的内测体验中,我时常会思考一个问题:
当一个工具将繁琐的执行门槛降到如此之低,当Agent可以代劳大部分的流水线工作,人类创作者的核心壁垒究竟还剩下什么?
LibTV的出现,其实是在剥离附加在视频创作上的技术壁垒。
它明确地告诉我们,未来不再有人会因为熟练掌握某款软件的快捷键或是精通某种模型的参数调度而成为大师。
技术的平权正在以前所未有的速度发生。
但这并不意味着创作者的贬值。
相反,当工具足够强大,当Agent学会了听从差遣,决定一部作品高度的,将纯粹回归到人类的判断与审美。
画面应该传递怎样的情绪?
剧情应该在哪个节点反转?
那一束光打在角色脸上的角度,究竟是为了映照内心的挣扎,还是为了暗示命运的走向?
机器或许能算出最符合物理规律的光影,但只有人类,才能决定哪一种光影能触动人心。
LibTV不是一个教你如何审美的系统,它是一个让你的审美可以被无损放大、高效执行的基础设施。
第一扇门,它用无限画布接纳了人类的细腻与控制欲;
第二扇门,它用API接纳了Agent的效率与执行力。
现在,这座赛博时代的专业制片厂已经正式开门。
无论是亲自下场连线,还是唤醒你的个人Agent发号施令,工具已经准备就绪。
只是这一次,考验你的不再是技术,而是你究竟能讲出一个多好的故事。
PS:
如果你准备好验证自己的审美与创意,欢迎探索下一代视频创作系统。
人类GUI访问请前往 LibTV官网:https://www.liblib.tv/;
Agent Skill接入请访问 Github页面:https://github.com/libtv-labs/libtv-skills )
文章来自于“01Founder”,作者 “Max”。
