

击败Sora与Veo 3:字节Seedance 2.0登顶盲测榜,AI视频进入“工作流”对决
在全球大模型技术演进的时间表上,视频生成赛道一直保持着极高的进化烈度。各大科技巨头在攻克了单张图像生成的参数难题后,迅速将庞大的算力投入到对时间维度与物理世界规律的模拟之中。
2026年3月,一份极具含金量的成绩单刷新了行业的视野。字节跳动(ByteDance)旗下前沿AI视频生成模型Seedance 2.0在全球范围内正式上线。在业界公认的Artificial Analysis独立盲测排行榜中,Seedance 2.0在Text-to-Video(文本到视频)类别里以1269的Elo分数位居首位。同时,在Image-to-Video(图生视频)领域也录得了领先数据。
这份榜单的数据来源是大规模的用户盲投票。在去除了品牌滤镜和先入为主的偏见后,Seedance 2.0在实际生成质量和用户真实偏好上,正面击败了Google发布的Veo 3、OpenAI的Sora以及快手Kling等一众强劲对手。
惊艳的跑分数据只是浮出水面的冰山一角。把视角切入到具体的参数指标与产品落地形态中,Seedance 2.0的登顶预示着生成式视频技术正在跨越一个关键节点:从供人惊叹的技术演示,正式嵌入到专业创作者的日常生产管线中。


告别“盲盒式”生成:原生音视频同步与导演级控制
过去一年里,体验过早期文生视频工具的用户,通常会有一种强烈的“抽卡”感。输入一段提示词,点击生成,等待几分钟后,得到的往往是一段充满随机性的画面。
这种“盲盒式”的生成体验伴随着两个极难修复的痛点。首先是对物理世界规律的理解缺失。视频中的人物走动时经常发生肢体融化,杯子放在桌面上会出现穿模,镜头的推拉摇移伴随着极其不自然的果冻效应。其次是感官的割裂。模型只能输出静音的动态画面,创作者必须依靠其他音频软件重新为其配上音效,音画错位是常态。

Seedance 2.0在底层架构上对这些痛点进行了针对性的重构。
它采用了一种多模态统一架构,全面支持文本、图像、音频及视频的多输入方式,最高可输出1080p分辨率的高保真视频。技术层面最受瞩目的突破,是实现了“原生音视频同步生成”。
在以往的技术路径中,画面与声音分属两个不同的生成模型,它们在不同的潜在空间(Latent Space)里各自完成推演。Seedance 2.0打破了这层壁垒,让视觉像素的变化和音频波形的生成在同一个模型架构内完成联合计算。当视频画面中出现一滴水落入池塘的涟漪,或者一辆跑车轮胎摩擦地面的瞬间,清脆的滴水声和刺耳的胎噪会与画面帧实现毫秒级的精准咬合。这种一体化的生成方式,极大地减少了创作者在后期拟音环节的繁琐工作。
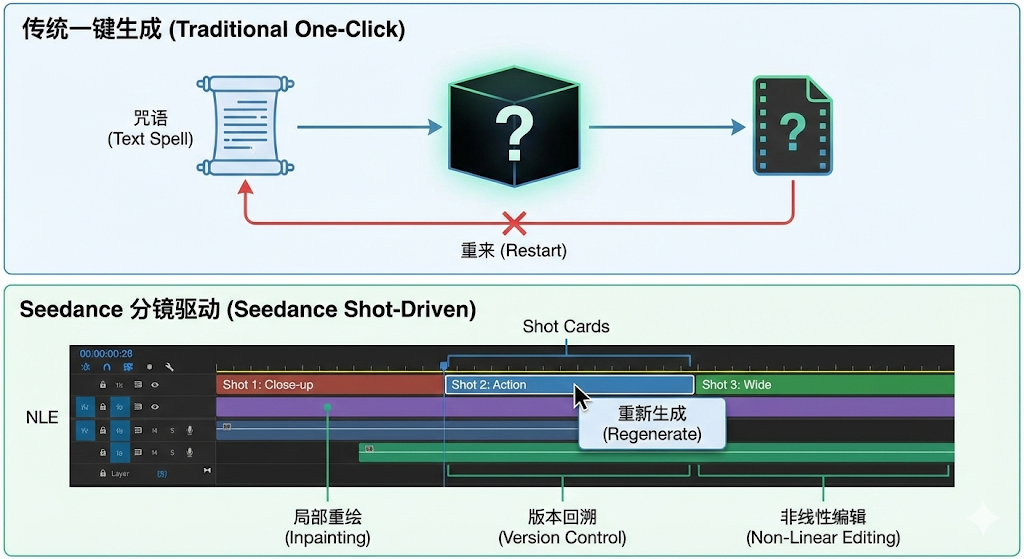
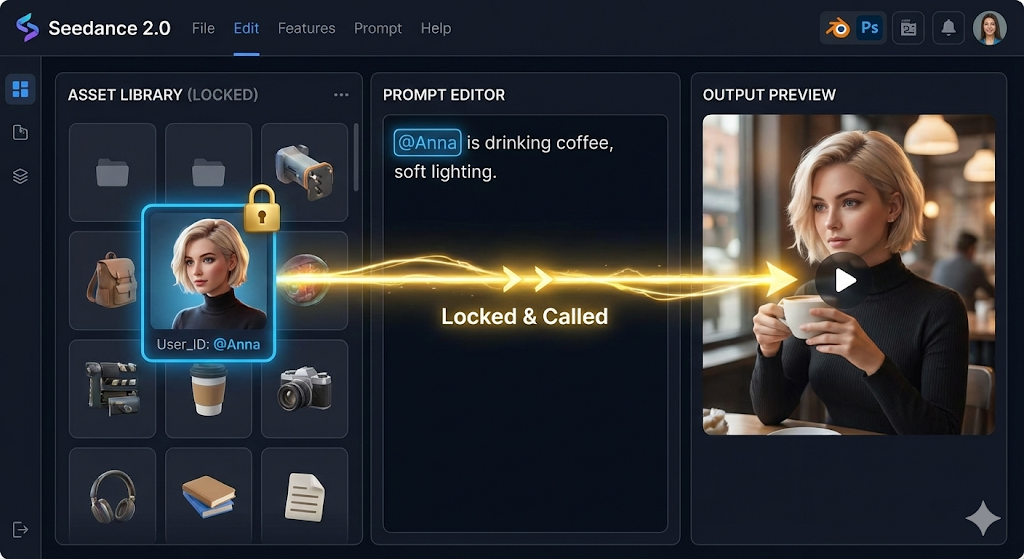
在画面控制力上,新版本对复杂交互场景的物理模拟以及人物一致性保持展现出了极高的精度。它允许用户对相机运动进行细颗粒度的规划。对于专业领域的广告营销和影视预览制作而言,能否精确控制全景、特写、平移或环绕镜头,决定了这段素材到底是一个昂贵的玩具,还是真正可用的商业级视觉资产。Seedance 2.0补齐了这块拼图,赋予了用户期待已久的“导演级控制权”。
 诸神混战:大厂围剿与工具赛道的横向博弈
诸神混战:大厂围剿与工具赛道的横向博弈
把Seedance 2.0放在当前的全球AI视频赛道中横向比对,能够更清晰地看懂各大巨头的战术差异与生态位争夺。
作为这条赛道的启蒙者,OpenAI的Sora曾凭借长达一分钟的连贯视频震惊世界。Sora采用的Diffusion Transformer架构为整个行业指明了技术方向,但在后续的商业化落地上,它显得极为迟缓。高昂的推理算力成本和极其漫长的渲染等待时间,让Sora难以迅速普及到普通消费者手中。在长视频连贯性和物理规律的稳定性上,起步最早的Sora正面临后来者密集的火力冲击。
Google的Veo 3则带有浓厚的实验室精英属性。依托于强大的TPU算力集群,Veo 3在画面质感、光影的电影感表现上尤为出众。Google试图将其与YouTube庞大的创作者生态深度绑定。一贯严格的安全审查机制和复杂的版权风控,导致Veo系列模型在开发者API的调用和公共测试权限上始终保持着谨慎的节奏。
在国内市场,快手的Kling是Seedance最直接且极具压迫感的竞争对手。Kling在过去大半年的时间里,保持着极其惊人的迭代速度。它在中文长难指令的精准理解、复杂人体运动的生成,以及表情控制上积累了大量的调优经验。Kling通过网页端和移动端的迅速铺开,已经聚拢了一批忠实的短视频创作者,双方在参数比拼和用户留存上正处于贴身肉搏的阶段。
在这样的多方博弈中,字节跳动为Seedance 2.0准备了一张其他所有纯模型厂商和初创公司(如Runway、Luma)都不具备的生态底牌。
Seedance 2.0在发布之初,就直接接入了国际版Dreamina的网页端,并全量集成到了CapCut(剪映海外版)的桌面及移动端中。
视频创作从来不是一个单一的生成动作,而是一个包含了剪辑、调色、配音、加字幕的非线性工作流。独立的视频生成网站要求用户先在云端生成素材,下载到本地,再导入剪辑软件。而Seedance 2.0与CapCut的无缝集成,意味着用户可以在剪辑的时间线上,随时召唤AI生成一段缺失的B-Roll(空镜头)或转场特效。
它把AI视频生成从一个需要单独访问的“目的地”,变成了一个嵌入在现有创作流程里的“基础功能”。这种工作流层面的闭环,极大降低了高质量内容的生产壁垒。

生产力重构与必须跨越的行业护栏
Seedance 2.0登顶盲测榜并开启全球化部署,标志着生成式视频技术已经走出了早期的概念验证期,稳步迈入主流商业与娱乐应用的深水区。
伴随这类高精度、低门槛工具的普及,内容创作产业的成本结构正在发生实质性的改变。
以往在进行广告概念短片制作或影视分镜预览时,剧组需要耗费大量资金搭建实景、雇佣演员并进行初步的特效渲染。如今,导演和策划团队完全可以利用多模态大模型,以极低的成本在短时间内生成高度逼真的视觉样片。创作者的核心竞争力,正在从传统的“素材搜集和基础拍摄技术”,整体向上平移至“剧本构思、美学品味与宏观叙事把控”。懂得如何用精确的语言去调度大模型,成为了视觉从业者的一项基本生存技能。
技术的狂飙突进也必然伴随着一系列亟待解决的产业挑战。
生成画面的逼真程度越高,原生音视频同步越自然,随之而来的深度伪造风险就越严峻。如何建立一套完善的防滥用机制,对AI生成的视频进行不可篡改的底层隐水印标记,是各大厂商在推进商业化时必须交出的安全答卷。
高质量模型的训练依赖于海量的影视、图像和音频数据。在全球范围内,关于生成式AI内容合规与版权保护的法律争议仍在持续发酵。任何试图将大模型作为基础设施向所有企业级场景开放的玩家,都必须在这场技术大迁徙中,小心翼翼地绕开隐匿的合规雷区。
在这个算力与算法狂欢的春天,从文本生图到原生多模态视频生成的跨越,不过是生成式AI长跑中的一段加速冲刺。技术的极限远未到来,当各种模型产品进入近身肉搏的工作流对决时,谁能让创作者更流畅、更安全、更低成本地实现创意的降维打击,谁就握住了通向下一个内容时代的入场券。
