

Karpathy刚开源的autoresearch,我拿来优化龙虾skill,成功率从56%飙到92%


养了这么久的虾,你应该能发现,skills有多重要了。
一个写得很差的skill,其实没那么可怕。
因为让龙虾跑2次,发现它完全不work,当场原地卸载就完了。
但是很多skill是特别折磨人的,它不是完全不能用。可能70%的概率还可以,但是30%的概率翻车。
这个太现实了。Karpathy大佬,最近发布了一个开源项目,叫autoresearch,让agent自主优化大模型训练,效果嘎嘎好。
但是,其实这套方法论,是可以推移到别的场景了。
今天分享一下,我用这套理论优化skill的最佳实践!
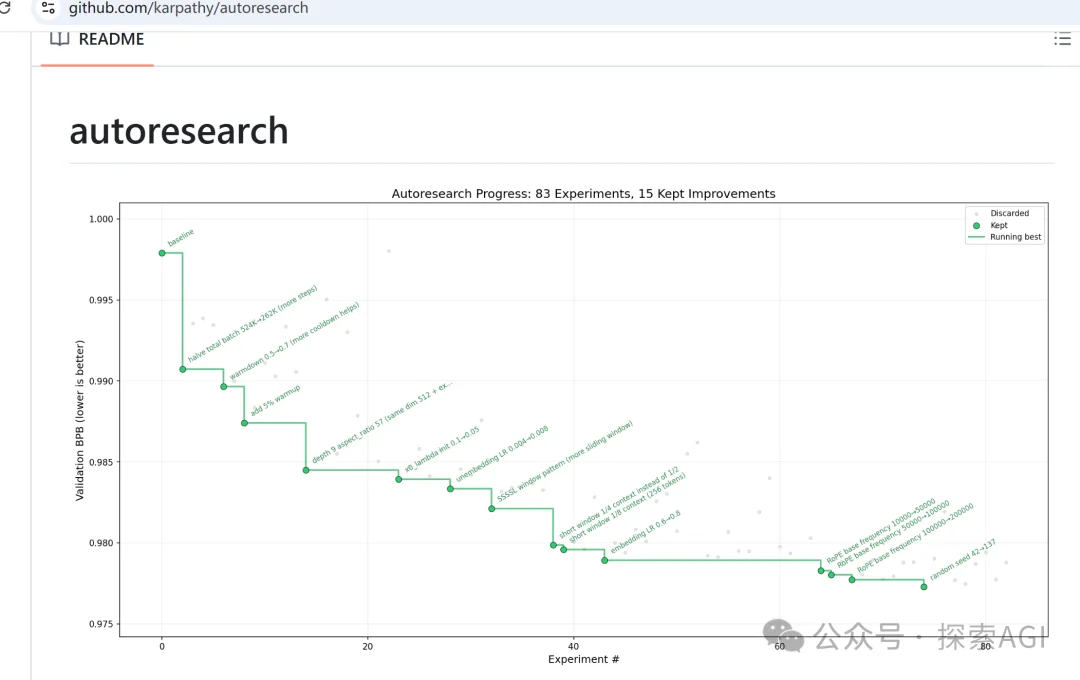
autoresearch的本质其实就是:让AI优化AI。
所以我们当然可以让AI自动迭代优化skill了。 我测试了一个网页复制相关的skill,可以从56%的通过率提升到92%。
skill最怕不稳定。
skill不稳定,一般就是按照这个skill的流程执行, 大模型有概率出现不符合预期的结果。
但是往往你还不知道,这些不好的结果到底怎么出现的。
这个时候怎么办呢?你可能会让AI复盘,凭着感觉,进行随意修改。
最后,可能skill变成了一个缝合怪了。
而autoresearch干的事,就是要把这个过程,变成一套可重复的实验。
其实核心特别朴素,它不需要让agent一次完成所有的skill重写。
一次改一个小地方,然后重跑打分,效果好了,保留修改,变差了撤回修改。
所以其实任何可以被衡量的东西,都可以被autoresearch。
包括各种 skills。
定义什么是好?
首先为什么skills不稳定?
因为里边可能会有一些比较模糊的表述。
比如,不要有AI味儿,要更自然一点。
这些话都没问题,但是执行起来会很玄学。autoresearch则会逼着你把这些玄学,拆成可以判断的是非题。
你对一个好结果的定义是?
比如一篇创作skills,一些定义可能是:
- 全文是不是控制在1500字以内?
- 开头3句有没有点清通电?
- 标题有没有xxx?
就是做出一些是否的定义,AI可以稳定进行打分。
这里提供一个确地评判的样例Prompt:

### Eval 指南
如何编写真正能提升你的 skill,而不是给你虚假信心的 eval 标准。
---
### 黄金法则
每一个 eval 都必须是一个 yes / no 问题。
不是量表。
不是感觉判断。
必须是二元的。
为什么:量表会叠加波动。如果你有 4 个 eval,每个都按 1-7 分评分,那么总分在不同运行之间会有很大的方差。二元 eval 才能给你稳定可靠的信号。
---
### 好 eval 和坏 eval
#### 文本 / 文案类 skill
比如 newsletter、推文、邮件、落地页
**坏 eval:**
- “这段文字写得好吗?”
(太模糊了,“好”到底是什么意思?)
- “给它的吸引力打 1-10 分”
(量表 = 不可靠)
- “它听起来像人写的吗?”
(主观,评分不一致)
**好 eval:**
- “输出中是否完全没有出现这份禁用词列表中的短语:[game-changer, here's the kicker, the best part, level up]?”
(二元、具体)
- “开头第一句是否提到了一个具体的时间、地点或感官细节?”
(二元、可检查)
- “输出是否在 150-400 字之间?”
(二元、可测量)
- “结尾是否用了一个具体的 CTA,明确告诉读者下一步该做什么?”
(二元、结构性)
#### 视觉 / 设计类 skill
比如图解、图片、幻灯片
**坏 eval:**
- “看起来专业吗?”
(主观)
- “给视觉质量打 1-5 分”
(量表)
- “布局好吗?”
(模糊)
**好 eval:**
- “图片中的所有文字是否都清晰可读,没有截断、重叠或互相覆盖?”
(二元、具体)
- “配色是否只使用柔和 / 粉彩色调,没有荧光色、亮红色或高饱和颜色?”
(二元、可检查)
- “布局是否是线性的,也就是从左到右或从上到下流动,没有零散分布的元素?”
(二元、结构性)
- “图片中是否完全没有数字步骤、序数词或顺序编号?”
(二元、具体)
#### 代码 / 技术类 skill
比如代码生成、配置、脚本
**坏 eval:**
- “代码干净吗?”
(主观)
- “它有遵循最佳实践吗?”
(模糊,到底是哪种最佳实践?)
**好 eval:**
- “代码是否能在不报错的情况下运行?”
(二元、可测试,真的去执行它)
- “输出中是否完全没有 TODO 或占位注释?”
(二元、可 grep)
- “所有函数名和变量名是否都具有描述性(除了循环计数器外,没有单字母命名)?”
(二元、可检查)
- “代码是否对所有外部调用都做了错误处理(API、文件 I/O、网络)?”
(二元、结构性)
#### 文档类 skill
比如提案、报告、deck
**坏 eval:**
- “内容够全面吗?”
(相对于什么才算全面?)
- “它有回应客户需求吗?”
(太开放了)
**好 eval:**
- “文档是否包含所有必需章节:[把章节列出来]?”
(二元、结构性)
- “每一个结论是否都有具体数字、日期或来源支撑?”
(二元、可检查)
- “文档是否控制在 [X] 页 / [X] 字以内?”
(二元、可测量)
- “执行摘要是否能压缩在 1 段、且不超过 3 句话?”
(二元、可计数)
---
### 常见错误
#### 1. Eval 太多
超过 6 个 eval 之后,skill 就会开始“钻 eval 的空子” 它优化的是怎么通过测试,而不是真的产出好结果。就像学生死记硬背答案,却没有真正理解内容。
**修正方法:** 选出最重要的 3-6 个检查项。如果这些都通过了,输出大概率就是好的。
#### 2. 过窄 / 过死
“必须正好包含 3 个 bullet point” 或 “必须至少使用 2 次 because” 这种规则,会让 skill 技术上通过测试,但产出会变得怪异、僵硬。
**修正方法:** Eval 应该检查你真正关心的质量特征,而不是随意的结构约束。
#### 3. Eval 重叠
如果 eval 1 是“文本语法正确吗?”,eval 4 是“有没有拼写错误?”,这两条其实重叠了。语法失败里往往已经包含拼写错误。你是在重复计数。
**修正方法:** 每一个 eval 都应该只测试一个独立维度。
#### 4. Agent 根本无法衡量
“人类会不会觉得这段很吸引人?” agent 没法稳定回答这个问题。它几乎每次都会说“会”。
**修正方法:** 把主观感受翻译成可观察信号。比如“有吸引力”可以改写成:“第一句里是否包含具体主张、故事或问题,而不是一句泛泛的陈述?”
---
### 写 eval 之前,先过这 3 个问题
在最终确定一条 eval 前,先问自己:
1. **两个不同的 agent,拿到同一个输出,能不能打出一样的分?**
如果不能,这条 eval 太主观了,重写。
2. **一个 skill 能不能在根本没变好的情况下,靠钻空子通过这条 eval?**
如果可以,这条 eval 太窄了,放宽。
3. **这条 eval 测的,是不是用户真的在乎的东西?**
如果不是,删掉。每一条不重要的 eval,都会稀释那些真正重要 eval 的信号。
所以完整的一个循环是:
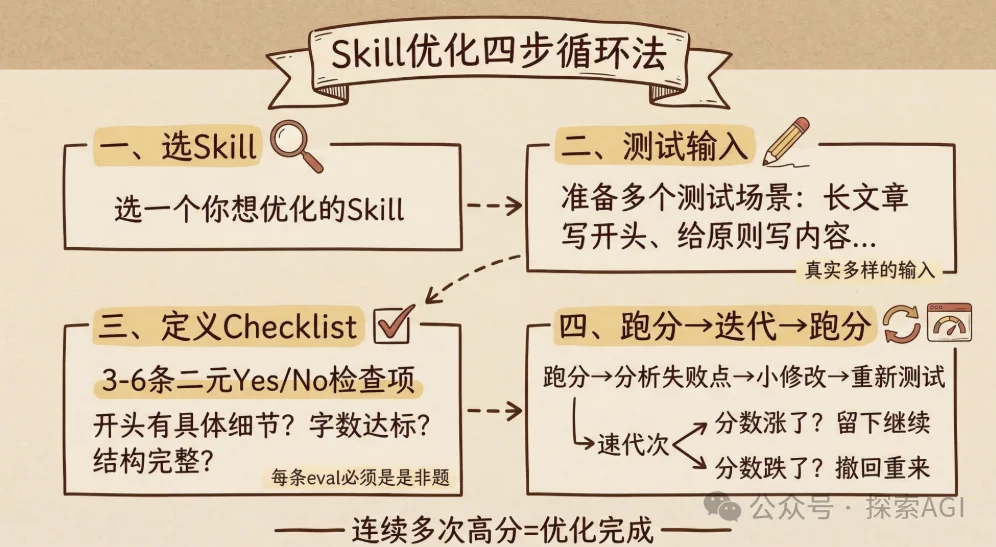
一、选一个你想优化的skill
二、给它一些测试输入。
比如给一篇长文章写个开头,给google的5条skills原则写一篇内容....
三、给他checklist
感觉3~6条比较好,太少了约束不够,太多了,agent又开始刷题迎合checklist了。
四、跑分 -> 循环 -> 跑分。
可能先跑分,发现很垃圾。agent可以分析失败点,做一个小修改,重新测试。分数涨了就留。分数跌了就撤。
然后继续下一轮。
一直跑到,连续多次达到高分。
那份changelog其实很有价值。
会包含完整的skill的进化历史。
会有改了什么?为什么改? 改了有没有提升?哪些是合理的改发,但是最后没用?
这个东西特别重要。
因为以后模型再升级,或者你想把 skill 迁移到别的平台。
你就不用从0开始了,手里有一份skill被验证过的进化路径。
这其实就是agent时代非常稀缺的东西。
写在最后
其实这些东西,不止能拿到优化skill。
我甚至,用来做代码性能优化。
一个页面加载,通过67轮, 从1100ms,跑到了67ms
所以,只要能定义评分规则,就可以让agent自主迭代优化。
其实这就是一种强化学习,评分规则就是reward score。
别再靠感觉去优化了,autoresearch已经摆明告诉所有人了:
如果一个东西会被反复调用,那它就值得被反复测试。
如果一个东西能被反复测试,那它就值得被交给 agent 自动优化。
#openclaw#autoresearch#karpathy
文章来自于“探索AGI”,作者 “猕猴桃”。
