

配音圈集体向AI宣战:拆解AI配音灰产链,大模型如何重塑声音的商业版图
国内配音圈的头部力量,在今年3月罕见地集结在了一起。
边江工作室、729声工场、音熊联萌等国内顶尖的配音机构,以及季冠霖(《甄嬛传》配音)、吕艳婷(《哪吒》配音)、史泽鲲等知名配音演员,密集发布维权声明。他们控诉的矛头指向了一个明确的群体:那些未经授权,擅自在各类短视频、AI漫剧和有声书中“克隆”并滥用他们声音的AI工具及个人账号。史泽鲲更是直接委托律师提起诉讼,并公开征集侵权线索。
配音演员对AI工具的抵制由来已久。早在2024年,全国首例“AI声音侵权案”中,原告配音师殷某某因声音被擅自放在某App上售卖,最终获赔25万元。音熊联萌也曾耗时整整半年,才迫使一款名为“芊芊妙音”的AI配音App下架旗下夏磊、谢添天等人的侵权语音并公开道歉。

但在这些零星的胜诉案例背后,侵权类AI语音产品依然在各大应用商店和网页端野蛮生长。
当我们将视线从配音演员的维权声明,转移到支撑这些现象的技术底座和商业链路时,我们会发现,这场围绕“声音”的防守反击,折射出的是整个AI语音技术演进与产品合规之间的激烈碰撞。

一秒克隆与“洗声”伪装:AI配音的底层技术演进
配音圈苦AI久矣,根本原因在于AI语音合成(TTS,Text-to-Speech)和声音克隆(Voice Cloning)技术的门槛,在过去两年里经历了断崖式的下降。
传统的配音是一项高度依赖“肉身出场”的重度脑力与体力劳动。配音演员需要在录音棚里待上几天甚至几个月,凭借对剧本的理解,精细调整呼吸、共鸣和情绪,成本高昂且周期漫长。
但在目前的AI语音模型(如开源的VITS、Sovits架构,或闭源的商用大模型)面前,这种不可复制的劳务属性被彻底瓦解。
技术的发展让“提取声音特征”变得异常简单。现在的深度合成技术,不再需要一个人在录音棚里字正腔圆地录制几万个标准汉字来建立音色库。只需要提取某位知名配音演员在影视剧里几十秒到几分钟的“干声(去除背景音的纯人声)”素材,AI就能极其精准地捕捉到其声线的频率、颗粒感和音色特征。
随后,只要用户输入任意一段文本,模型就能用这个克隆出来的音色,毫无疲倦、字正腔圆地朗读出来。这种极低成本的“声音复制”,成为了大量营销号、短视频搬运工和劣质AI漫剧的标配。
更让维权者感到棘手的,是灰产圈已经进化出了一套隐秘的“融音”技术(即多音色融合)。
为了规避被原声主人认出的法律风险,一些侵权App或个人创作者不再进行1:1的粗暴克隆。他们通过算法调参,把季冠霖(《甄嬛传》甄嬛配音)声线中那种特有的清冷感,融合20%李立宏(《舌尖上的中国》旁白)的醇厚共鸣,再混入一些其他人的特征,调配出一个“似曾相识但又无从指认”的全新混合音色。

这种被业内称为“洗声”的算法伪装,直接击中了法律维权中必须具备的“可识别性”要件。当声音被拆解成一个个参数并在潜空间里重新混合后,证明这个新声音里“有我的合法权益”,变成了一项举证成本极其高昂的任务。

从草台班子到大厂收编:合规声音库的商业化暗战
在那些用爬虫抓取盗版音频来训练模型的草台App之外,国内的头部科技巨头(如火山引擎、腾讯云、网易伏羲、科大讯飞)在推进商用TTS时,走向了另一条极其严苛的合规路线。
对于大厂而言,声音不仅是技术展示,更是必须能够安全售卖给B端企业客户的商业资产。因此,他们在构建官方音色库时,建立了一套严格的授权壁垒。
以字节跳动旗下的火山引擎为例,其提供的火山语音服务,在招募发音人时,会签订极其详尽的买断或分成协议。大厂通常会花重金邀请专业的播音员、配音演员甚至明星,进入专门的录音棚进行合法的数据采集。这些采集来的数据被用于训练专属的AI音色,并明确标注了授权的使用范围(如仅限于短视频配音、新闻播报或车载导航)。
腾讯云的AI语音合成服务同样强调版权的清晰链路。在游戏、有声书等高价值场景中,腾讯会利用自有的IP资源,通过合规途径获取知名角色的声优授权,进而开发出能够自动生成带有角色性格特征的AI语音包,供内部工作室或外部客户调用。
对于这些正规军来说,“单独书面授权”和“防范概括性授权陷阱”是基操。他们清楚,任何版权上的瑕疵,都会成为日后向企业大客户(如金融机构、大型游戏公司)交付产品时的致命地雷。
这种“花钱买合法声音”的模式,实际上是巨头利用资金和技术优势,对优质声音资产进行的一次合规收编。它在客观上为部分愿意拥抱AI的配音演员,提供了一条将声音变现的正规渠道。

ElevenLabs与YouTube:海外“声音分成”的生态实验
如果我们把视线投向海外,会发现关于AI声音版权的商业化探索,已经走得更加超前和激进。
目前全球估值最高的AI语音独角兽ElevenLabs,在解决“声音克隆与版权保护”的矛盾时,交出了一份堪称行业标杆的答卷——“Voice Payouts(声音分成)”计划。
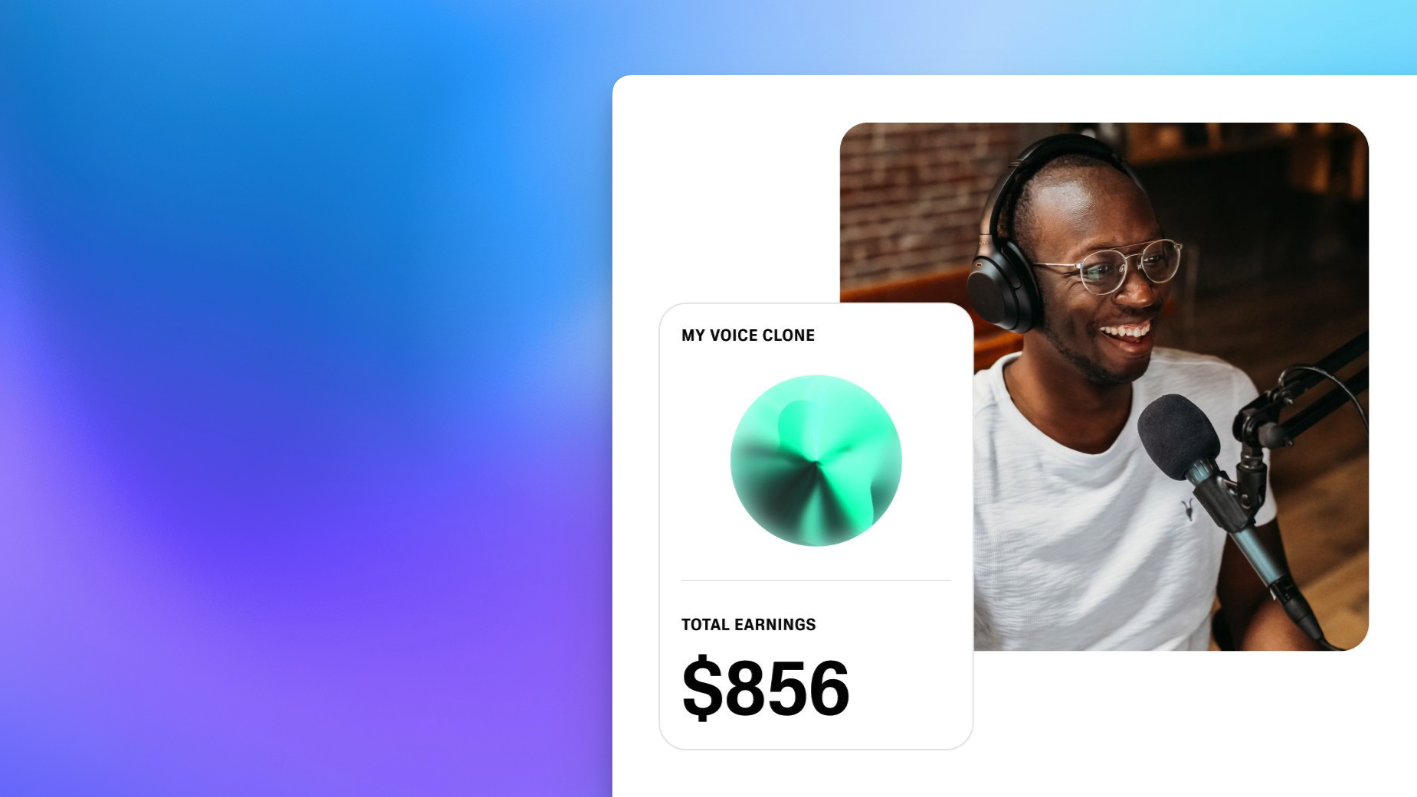
ElevenLabs允许普通用户、专业配音演员甚至明星,将自己的声音上传到平台,生成一个专属的AI音色模型,并将其放入官方的“Voice Library(声音模型库)”中。在这个库里,每个声音都被标记了明确的归属权。
最核心的商业闭环在于:一旦平台上的其他创作者(比如做播客的、做YouTube视频的)使用了你的这个AI音色来生成音频,作为声音的主人,你就能根据生成的字符数或时长,获得实打实的现金分成。
这种模式极其精妙地化解了对抗。它把原本零和博弈的“侵权盗用”,转化为了一种双赢的“API调用收租”。ElevenLabs不仅通过这种分账机制吸引了大量优质的独家声音资产,还从根本上扼杀了用户去其他平台盗用声音的动机——既然能在官方库里合法且低成本地使用顶级音色,何必冒着吃官司的风险去搞盗版?
同样在探索“声音合法二创”的,还有视频巨头YouTube。
YouTube联合环球音乐集团(UMG)以及约翰·传奇(John Legend)、Sia等顶流歌手,推出了一项名为“Dream Track”的AI音乐实验。该功能允许平台上的短视频创作者,合法地使用这些合作歌手的AI克隆声音,生成不超过30秒的背景音乐配乐。

探索 YouTube 梦想曲目实验,其中收录了 Alec Benjamin、Charlie Puth、Charli XCX、Demi Lovato、John Legend、Papoose、Sia、T-Pain 和 Troye Sivan 等艺术家的作品。
YouTube在后台建立了一套极其复杂的Content ID(内容识别)系统。这套系统能够自动追踪哪些视频使用了这些AI生成的合法授权声音,并确保版权方(唱片公司和歌手)能够从这些视频的广告收益中获得相应的分账。

声纹确权:技术反制的下一步
回到国内配音圈的集体维权事件,配音演员们面临的困境,本质上是旧有的法律与商业框架,暂时无法追平AI模型抓取数据的速度。
面对隐蔽且低成本的侵权产业链,单纯依赖事后发律师函和漫长的诉讼,效率极低。在行业目前的探讨中,技术反制正在成为合规化进程中不可或缺的一环。
部分头部配音工作室和技术公司,已经开始探索对旗下配音演员的标志性音色进行数字化的确权存证。更前沿的做法,是在授权的原始录音或官方AI生成的音频中,嵌入人耳无法察觉的“数字水印”。
这种音频隐写技术,能够在声音的频率中持久保留版权所有者的身份信息。即便音频经历了剪辑、压缩,甚至是被灰产拿去作为“融音”的训练素材,只要通过特定的检测算法,依然能够提取出底层的水印证据。这为日后主张“可识别性”、锁定侵权源头提供了坚实的技术底座。
从“防备AI”到“给声音打上不可篡改的标签”,再到探索类似ElevenLabs的“按次调用分账”模式,整个AI语音行业正在经历一场痛苦但必然的秩序重构。
在这个进程中,声音正在不可逆转地从一种必须肉身到场的“劳务技能”,演变为可以被数字化、被授权、被高频调用的“资产”。对于手握顶级音色与演绎能力的配音演员而言,最大的挑战或许不仅仅是打赢眼下的几场侵权官司,更是如何在这场重塑声音商业版图的技术浪潮中,找到安全、合规且能持续获益的长期位置。
