

不卷Agent,死磕上下文:美团Tabbit为何逆势重做AI浏览器?
整个3月,硅谷和国内的科技圈几乎被一款名叫OpenClaw的开源产品彻底淹没了。“你用龙虾(OpenClaw)了吗?”成了许多开发者和产品经理见面时的常用开场白。
伴随着这款Agent(智能体)产品的爆火,一种强烈的技术错失恐惧感在社交网络上迅速蔓延。人们看着演示视频里那个能够自动接管电脑、回邮件、写代码的赛博助手,一边惊叹,一边感到焦虑。
但在热闹的热搜和技术群之外,普通用户的真实体验却呈现出极端的两极分化。大量跟风去折腾OpenClaw的职场人很快发现,这东西根本不是给大众准备的。面对黑底白字的终端命令行、复杂的环境配置、时不时崩溃的报错,以及高昂的Token订阅费,绝大多数非技术人员被死死挡在了门槛之外。
当极客们在为全自动Agent狂欢时,普通人猛然发现,自己手里连一个趁手、简单、能切切实实帮自己干点活的AI工具都极其稀缺。
就在这个大厂纷纷扎堆研发底层大模型、极客们沉迷于硬核Agent的时间节点,光年之外团队低调地交出了一份看起来有些“传统”的答卷:一款名为Tabbit的PC端AI原生浏览器。

在众多明星创业公司甚至开始反思“浏览器这种产品形态是否已经过时”的今天,光年之外选择逆势扎进这个古老的赛道,背后藏着一套极其务实的产品账本。

拒绝“改造用户”:一款长得像Chrome的新浏览器
打开Tabbit,你可能会有一瞬间的恍惚。它没有像市面上许多打着“下一代AI入口”旗号的产品那样,搞出极其炫酷、充满科幻感的暗黑操作台。
它长得非常像你最熟悉的Chrome。
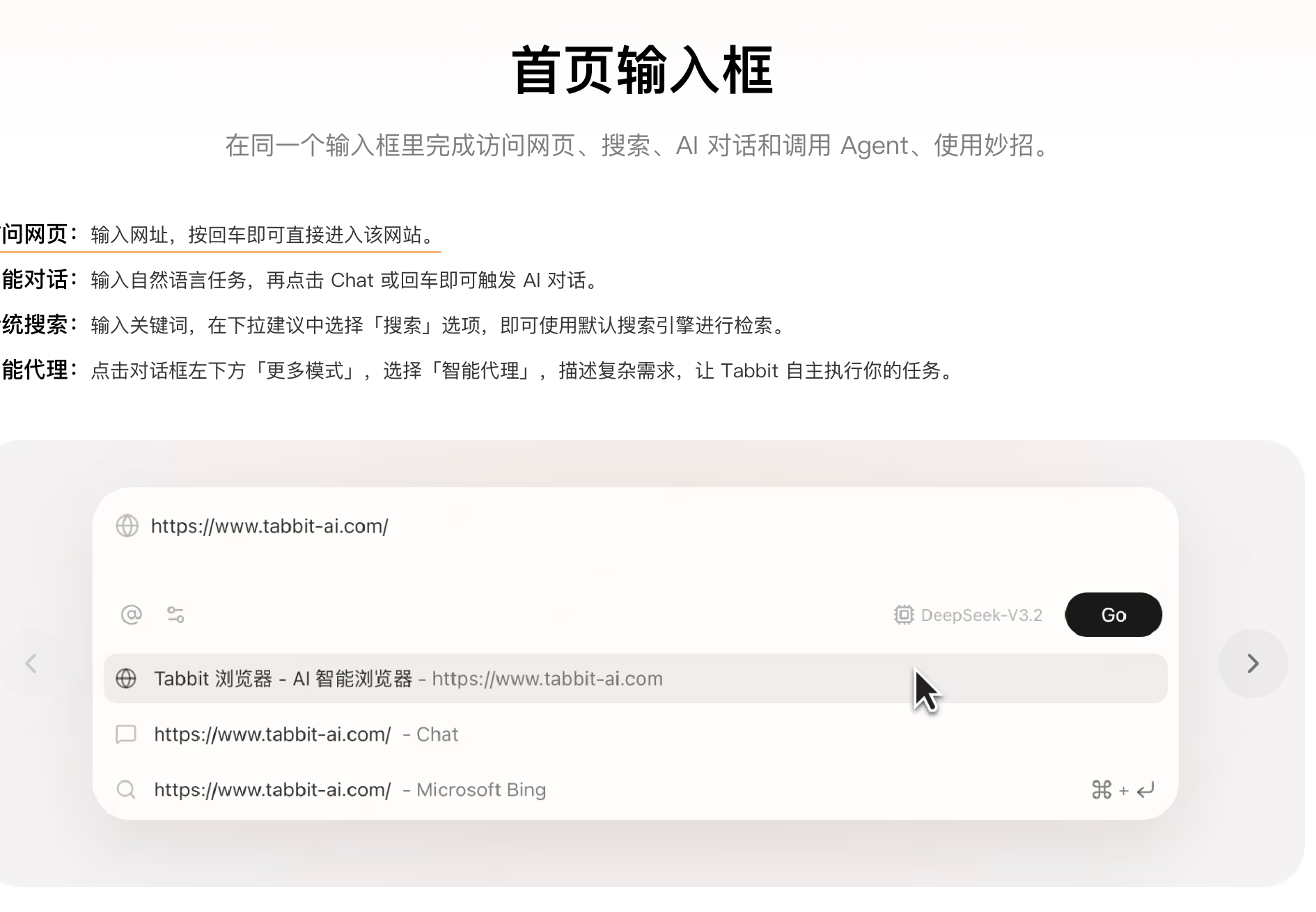
顶部依然是常规的标签页,书签栏还在熟悉的位置,甚至连用户最习惯的自定义首页都被完整保留了下来。Tabbit团队在产品设计上做出了一个极其克制的决定:兼容主流生态习惯,把用户的迁移成本降到最低。
这其实切中了当前AI应用落地的一个隐秘痛点。很多科技公司在推行AI产品时,总带有某种“教育用户”的傲慢,要求用户抛弃旧习惯,去适应一套全新的对话式UI(用户界面)。但对于每天需要在电脑前处理繁杂文档、处理OA流程的上班族来说,重新学习一套工具的摩擦力极大。
Tabbit将所有的AI能力,极其克制地收拢在了侧边栏和右键菜单里。它聚合了目前市面上最顶尖的几款大模型,包括DeepSeek、Kimi以及通义千问等。用户不需要在不同的网页和账号之间来回登录,可以根据不同的任务需求,在侧边栏随时一键切换最合适的模型大脑。
不试图去颠覆用户的基础上网姿势,而是把最先进的AI能力像无缝镶嵌的齿轮一样,悄悄滑入原有的工作流。这是Tabbit试图在激烈的入口争夺战中留住普通人的第一张底牌。

把Agent封装成“按钮”, 降维成普通人的工具
普通人到底需要什么样的AI辅助?我们不妨拆解一个最日常的工作场景。
假设你正在网页上看一篇长篇行业报告,突然需要针对其中的某段数据写一份分析。在过去的传统流程里,你需要经历极其繁琐的五个步骤:选中数据复制,新建一个标签页打开DeepSeek的官网,把数据粘贴进对话框并输入你的要求,等待AI生成结果,最后把答案复制回你原本的工作文档中进行修改。
Tabbit通过底层重构,直接把这个流程压缩成了一步。
你在网页上一划,选中的信息就会自动呈现在右侧的AI对话引用栏中。你直接向侧边栏里的Kimi或DeepSeek提问,AI给出的优化建议或分析结果就展示在当前页面的旁边。你可以对照着原网页,直接在左侧修改你的报告。
这种“边看边问、边查边改”的体验,正是AI原生浏览器相较于普通网页版Chatbot的代差优势。它消除了在不同标签页之间频繁切换的注意力损耗。
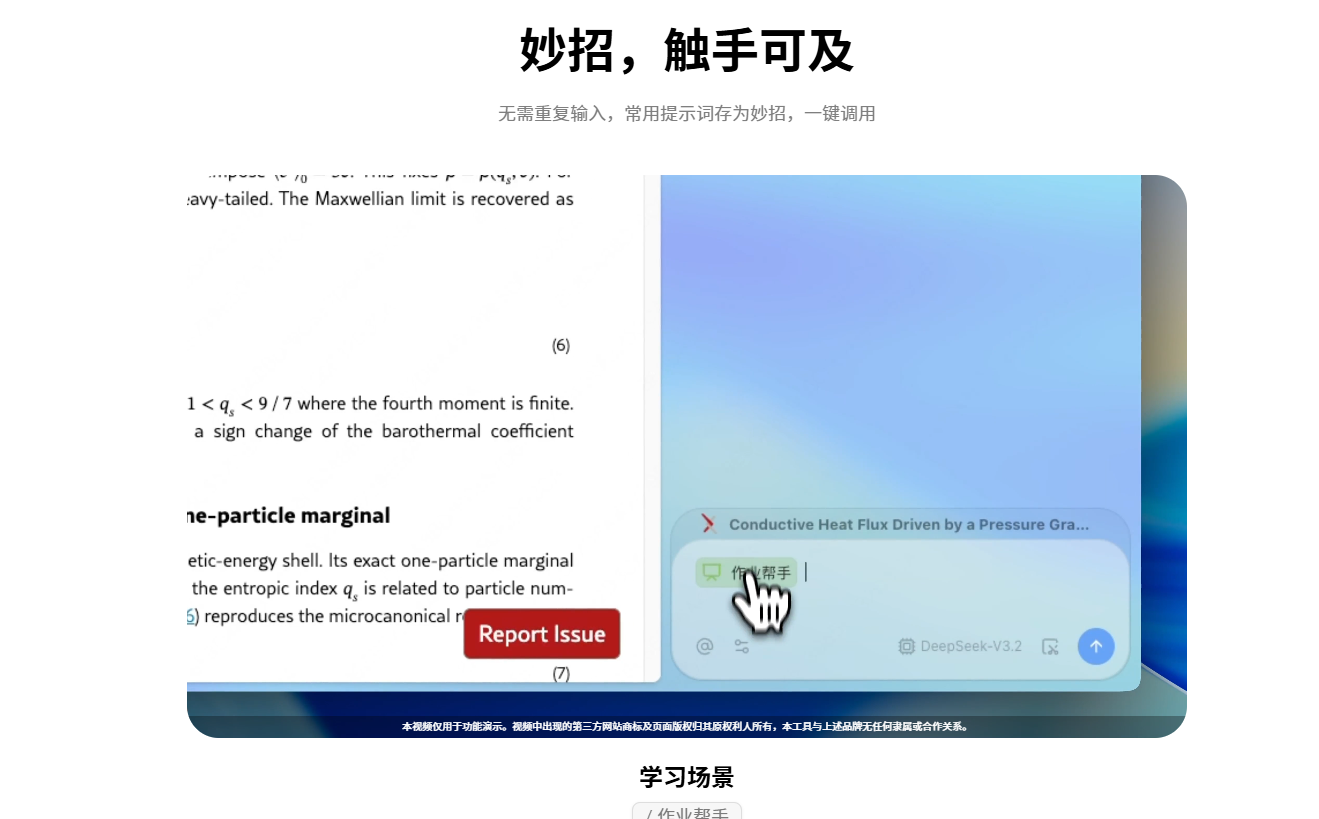
更值得关注的是Tabbit推出的“妙招”功能。
刚才我们提到,OpenClaw这类全自动Agent非常强大,但普通人不会用。Tabbit的“妙招”实际上提供了一个平民版的解法。它把一些复杂的AI执行逻辑,提前封装成了直观的功能按钮。
比如,你想要收集某个全网爆款产品的几百条用户反馈。在极客的做法里,可能需要写一段Python爬虫脚本或者配置一个复杂的Agent工作流。而在Tabbit的“妙招”广场里,你只需要找到对应的预设功能,点一下按钮,浏览器就会自动识别当前网页的结构,帮你把需要的数据整理好。

这就像是专业单反相机和智能手机摄像头的关系。OpenClaw是那台需要手动调节光圈、快门、ISO的专业单反,上限极高;而Tabbit的“妙招”就是手机上那个一键开启的“人像模式”。普通用户未必愿意为了拍一张日常照片去学习单反参数,他们只需要在想拍照的时候,手边恰好有一个按下去就能出好片的快门。

浏览器赛道的三岔路口:颠覆、收编与改良
如果我们把视线从Tabbit单一产品拉宽,环顾当前的全球PC端入口之争,会发现各路玩家在对待“浏览器+AI”这个命题上,走向了三条完全不同的演进路线。
路线一:企图彻底杀死网页的“颠覆派” 明星创业公司The Browser Company推出的Arc浏览器,曾是这条路线的激进代表。Arc试图彻底抛弃传统的标签页和收藏夹,用极其前卫的UI重塑信息浏览的体验,甚至提出未来用户不需要看网页,AI会直接把答案喂到你嘴边。
但现实的商业反馈异常冰冷。颠覆C端用户习惯的成本高得离谱,且难以形成健康的盈利闭环。近期,Arc背后的团队已经在探索向企业级市场(B端)转型,试图打造名为Dia的纯企业级工作流入口。Arc在C端市场的受挫,给所有试图“重新发明浏览器”的团队敲响了警钟。
路线二:利用系统霸权强行绑定的“收编派” 微软的Edge浏览器是这一流派的绝对霸主。微软借助Windows操作系统的底层垄断优势,将Copilot极其强势地塞进了Edge的每一个角落。微软的逻辑非常清晰:利用系统级入口截胡Google的搜索流量,把浏览器变成自家大模型矩阵的前沿阵地。对于普通用户而言,这种结合往往带有强烈的压迫感和不可卸载的臃肿感。
路线三:深耕具体场景的“温和改良派” 在这场诸神之战中,光年之外的Tabbit选择了最平缓的第三条路。作为独立创业团队,它没有操作系统的护城河,也没有必须强推自家单一模型的包袱。它把自己定位为一个开放的“超级聚合器”,把选择权交还给用户。你可以用Chrome的习惯继续上网,只是在需要处理复杂标签分组、需要提取长文摘要时,侧边栏那个集成了全球最聪明大脑的助手,随时听候调遣。

退守上下文:光年之外的算盘
在大模型百模大战的格局已经基本落定的2026年,光年之外为什么还要投入重兵去做一个看起来有些古典的浏览器产品?
答案藏在数据链路的最深处。
目前所有的云端大语言模型都面临着同一个极其致命的瓶颈:缺乏“上下文(Context)”。无论DeepSeek或Kimi有多么强大的推理能力,如果它不知道你此刻正在看哪份财报、在浏览哪个的网页,它给出的回答就只能是泛泛而谈的废话。

对于绝大多数职场人来说,PC浏览器就是他们一天中停留时间最长、工作轨迹最密集的数字容器。OA系统、飞书文档、行业研报、竞品网站,全都在这一个个标签页里。
这正是Tabbit立项的核心逻辑。做浏览器,本质上是在抢夺用户最核心的“数字上下文”。
既然大模型的算力成本和研发门槛已经高不可攀,光年之外选择退而求其次,在应用层做起了“模型的集成商”和“数据的拦截网”。只要用户在Tabbit里查资料、做笔记,Tabbit就能顺理成章地获取这些最贴近真实工作场景的数据流。在这个基础上,再调用各家的大模型来提供精准服务。
这是一种极其聪明的商业降维。它避开了底层算力的无底洞烧钱战,把重心放在了用户体验的打磨上。
当然,前方的道路绝非坦途。当微软、苹果等操作系统巨头开始在系统底层全局集成AI,甚至未来可能直接在系统级接管用户的屏幕上下文时,一个停留在应用层的浏览器还能维持多久的不可替代性,是一个严峻的考验。
但就眼下而言,在宏大叙事满天飞、概念炒作此起彼伏的AI赛道里,普通人可能并不急需一个立刻接管自己所有工作的赛博神明。他们当下的真实痛点,也许只是一款能顺手帮忙把几十个杂乱网页分好类、把冗长枯燥的公文提炼出重点的靠谱工具。找准了这个朴素的生态位,Tabbit就已经拿到了留在牌桌上的第一张入场券。
