

一篇论文砸翻全球牛股,全球存储芯片市场恐慌,谷歌TurboQuant凭什么

昨日,全球存储芯片市场因一篇学术论文而引发恐慌。
截至3月26日收盘,A股存储板块重挫,恒烁股份跌超6%,兆易创新、佰维存储、朗科科技应声跌超5%,江波龙、北京君正等核心标的纷纷跟跌。美股开盘后,闪迪大跌超6%,美光科技与西部数据重挫超4%,希捷科技跌超3%,存储芯片与硬件供应链相关指数单日跌幅超过2%。
导火索来自谷歌研究院发布AI内存压缩算法“TurboQuant”。谷歌宣称能将大模型推理中的缓存内存占用压缩至六分之一,并在英伟达H100 GPU上实现最高8倍的性能加速。
TurboQuant目前仍处于实验室阶段,怎么会吓崩存储板块?是“狼来了”,还是谷歌的“DeepSeek时刻”来了?

大模型的压缩包
要理解存储板块为什么地震,我们得先看懂谷歌的底牌是什么。
我们都知道,模型越大,显存就越不够用,如今全球模型都面临算力瓶颈,芯片难求。传统的方法是键值缓存,就像你和AI聊天,AI需要笔记本记下对话,聊得越久,笔记本越厚,每次翻阅的内容越多,这让AI开始胡言乱语。行业内一直在尝试量化压缩,但每次压缩都需要一个压缩密码,压缩密码极占用空间,这样的压缩方法收益不高。
而谷歌的TurboQuant既要又要,用了两个阶段。
第一阶段叫极坐标量化。放弃了传统的直角坐标系,将数据向量转换成了极坐标系。简单来说,就是把“向东走3条街、向北走4条街”这种定位,变成了“朝着37度角走5条街”。 转换成了几何,让数据的分布可以预测,消除了传统算法中的计算负担,收益拉满。
第二阶段的量化JL变换技术更难。它是 数学层面的纠错器,把微小误差压缩成一个符号位(+1或-1),零额外开销下,又保证了绝对精准。
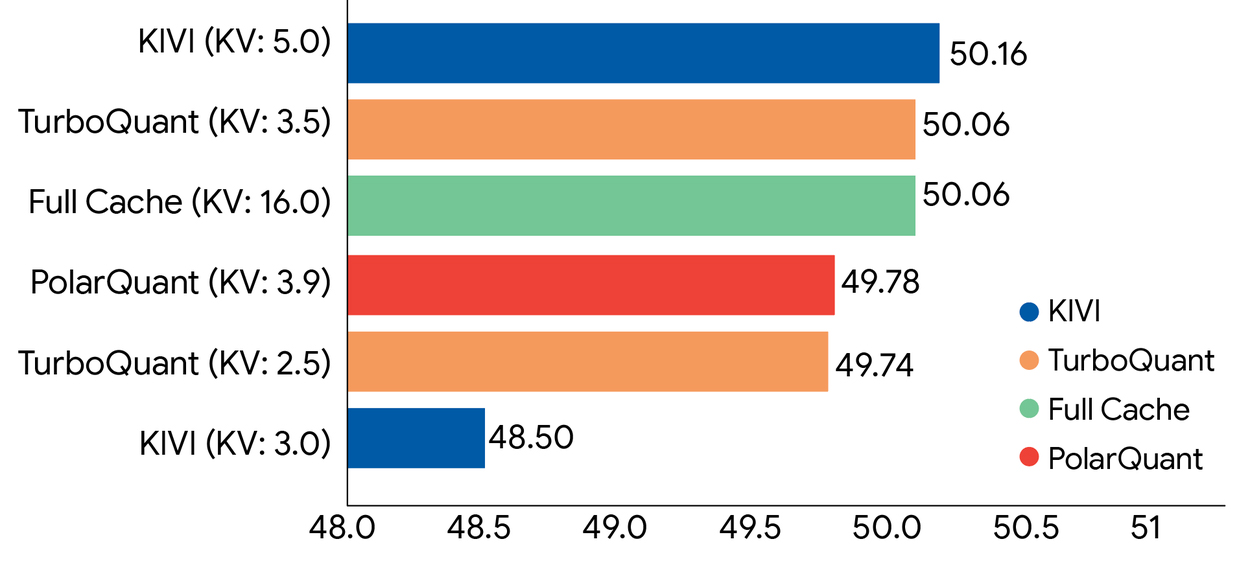
TurboQuant在LongBench基准测测试
凭借着两个阶段,TurboQuant的实测相当恐怖。在开源模型上,TurboQuant在长文本提取、代码生成、摘要任务中拿了满分,实现了零精度损失,更在英伟达H100显卡上,跑出了比未压缩版本快8倍的惊人速度!
靠着这套逻辑,AI的算力成本能压缩一大半。

硬件巨头们慌了神?
但纯软件层面的创新,为什么会让卖硬件的慌了神?因为全球存储芯片市场早就神经紧绷,囤货太多。
2025年底到2026年初,全球都处于内存危机之中。AI算力的需求增长,打破原有的供应链平衡,一台AI服务器对内存的需求,是传统服务器的8倍以上。为了吃下这波红利,三星、SK海力士、美光这三大存储巨头,将80%以上的产能转向了高利润的HBM(高带宽内存,专供GPU使用)。这也导致了普通DRAM和NAND Flash产能锐减,电脑和手机价格上涨。NAND TLC颗粒单日跳涨50%,从2025年三季度到2026年一季度,整体涨幅超过123%;DRAM(DDR4/DDR5)部分规格涨幅高达100%到300%,部分现货价格直接翻了2到3倍。
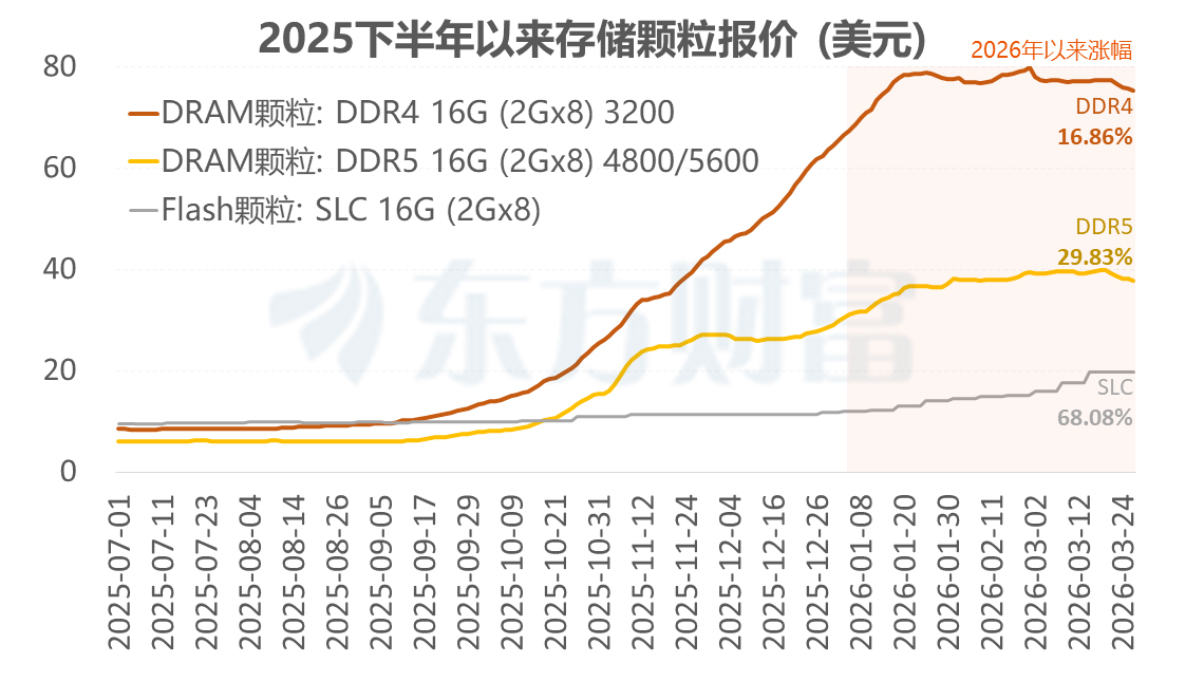
图源东方财富
下游厂商彻底陷入了恐慌性囤货。手机、PC、汽车、消费电子厂商为了保住生产线,开始疯狂下单、提前锁货,行业的库存周期从3.3周砸到了2.7周,部分晶圆厂,甚至对客户提出了“交3年预付现金”的霸王条款。国家发改委价格监测中心在2月底发文确认,存储价格持续上涨并已向下游传导,电脑、手机厂商已频发现调价函。预计2026年全球手机出货量将同比下滑10%到15%,创下十多年新低;汽车供应链的内存满足率甚至不足50%,大面积生产延迟。
“部分消费电子公司可能会在2026年下半年倒闭。”就连一向头铁的马斯克,都一度宣布特斯拉要自建存储厂来保命。
在这个节骨眼上,TurboQuant 横空出世。谷歌宣称能把KV Cache的内存需求砍掉六分之五,对于那些花重金囤积内存的下游硬件厂商,以及在享受暴利的上游存储原厂来说,无异于釜底抽薪。单张显卡的内存效率被成倍放大,那这段时间全球各大服务商的采购不就成了笑话?

是DeepSeek时刻,还是杰文斯悖论?
那么,存储厂商的苦日子真的要来了吗?可能并不简单。
我们不妨对比一下行业中类似事件。2025年初,当DeepSeek发布时,同样让全球市场认为算力硬件需求到顶。如今,不少人把TurboQuant的发布称为谷歌的“DeepSeek时刻”,认为其有望像DeepSeek一样,通过软件效率拉低AI成本。
但这其可能只是经济学中的“杰文斯悖论”。就像工业革命历史,瓦特改良了蒸汽机,让煤炭的利用效率大幅提升,人们以为效率高了,英国的煤炭消耗量就会减少。结果恰恰相反,因为蒸汽机高效且便宜,它被迅速普及到了纺织、轮船、火车等各个领域,反而让煤炭需求爆发。
这个规律,也许在今天同样适用。TurboQuant降低了内存成本,让单次推理成本理论上降低了50%以上,但企业绝不会少买内存,相反,它会激发出更庞大的总需求。通过大幅降低服务成本,这类技术能让原本只能在昂贵云端集群上运行的大模型,无缝迁移至本地。当中小企业不再受制于显存成本,当所有的手机、PC、汽车甚至微波炉都能流畅跑起大模型时,全球存储芯片的总盘子,只会变得比今天更庞大。

狼来了?资本的算盘
抛开技术与经济学不谈,一个正在实验的技术,真的能引发全球股市震荡吗?还是说,资本只是找了个砸盘的借口?
“利好出尽是利空,涨多了一定要跌。”过去一年多里,全球存储芯片板块借着AI算力的东风,以及人为制造的供需失衡炒作,股价早已翻了数倍。无论是美光、海力士,还是国内的兆易创新、佰维存储,其估值都太高了。对于早已获利丰厚的主力资金而言,内存在高位横盘,随时面临下游需求反噬的风险(如今天的手机销量下滑)。他们犹如惊弓之鸟,随时准备抢跑套现。
摩根士丹利在最新的研报中也指出,市场对此次事件存在严重的过度解读。TurboQuant 技术仅仅作用于“推理阶段”的键值缓存,它根本不影响模型权重本身所占用的大量高带宽内存(HBM),更与极其消耗显存的“AI训练任务”毫无关系。许多分析师更是直言媒体报道存在夸大成分。当前的AI推理模型,其实早就广泛采用了4-bit的量化数据进行降本增效,谷歌在论文中宣称的“8倍性能提升”,很大程度上是建立在与老旧的32位未量化模型对比的基础之上,这多少有点“田忌赛马”。
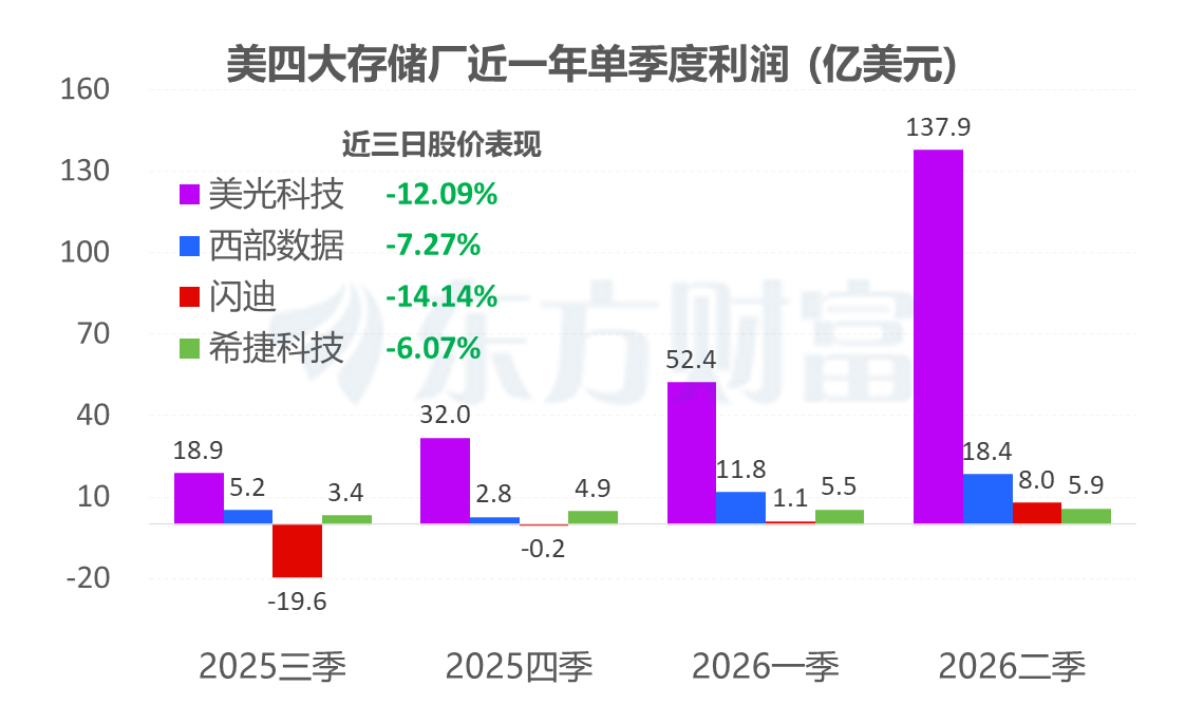
图源东方财富
此外,目前TurboQuant的验证范围主要集中在Gemma、Mistral等中小体量的开源模型上,谷歌自家Gemini的适配效果至今尚未公开,在万亿参数模型上的普适性仍需打个问号。
也许,这篇论文只是资本用来戳破泡沫的那根针。在估值过高、情绪过热的节点上,只要有一点风吹草动,资本就会毫不犹豫地借题发挥。

让子弹再飞一会
不管资本市场如何博弈,从长远来看,TurboQuant指明了一个的新形势,大家都在通过算法优化来压榨算力。
过去两年,AI是场烧钱游戏,大家都在囤英伟达得显卡,成本像一座大山,是所有创业公司和中小开发者迈不过去的坎。直到Deepseek的出现,大家才意识到算法优化得重要性。
“旧时王谢堂前燕,飞入寻常百姓家”。未来在更多TurboQuant的压缩下,可能只需要一台Mac Mini,或者一台老旧联想笔记本,AI就能在本地流畅运行。
以软代硬,已经成为中美科技圈共同突围的方向。
(微信公众号:Tahou_2025)
关注塔猴公众号,回复“1”加入专属社群
扫码下载塔猴APP,查看更多干货

