

DeepSeek深夜宕机,新模型要来了?

四月吃瓜月,单依纯李白的瓜刚走,DeepSeek的瓜又来了?
昨晚间到今日早晨,DeepSeek遭遇了长达数小时的大面积宕机,网页端和App频繁提示“服务器繁忙”或无法响应,#DeepSeek 崩了# 冲上微博热搜。
“早就不用了,一直用豆包🤞”。
“原来是崩了,我还以为是我网络不好呢”。
不少网友认为DeepSeek的服务器有待升级,这已经不是第一次出现大面积宕机;也有网友认为是被攻击了,导致服务器过载。
其实一天前DeepSeek刚刚迎来了一次升级,服务器异常或许与这次更新有关,难道DeepSeek在后台悄悄上线了V4?
塔猴梳理了昨晚事故与DeepSeek V4的所有蛛丝马迹,看这一篇文章就够了。

为什么DeepSeek就发大招
昨晚的一切发生得太突然。
根据DeepSeek官方状态页(status.deepseek.com)的时间线,官方团队在昨晚21点35分左右启动故障调查,随后在凌晨0点20分左右进行了紧急修复,部分对话服务直到深夜23点23分才开始逐步恢复。但即便如此,直到3月30日早上,依然有大量用户反馈服务DeepSeek未完全恢复正常,不少人表示:“DeepSeek网页版已经宕机超过6个小时”。
就在DeepSeek被修复的间隙,部分登录成功的用户发现,DeepSeek的输出风格和代码编写结果发生了明显变化。在编程测试中,模型给出的代码逻辑更为直接,错误率也有所下降。这种体验上的微妙差异,是“新模型正在灰度测试”的有力佐证,“DeepSeek当前宕机,后台肯定有动作,V4马上要揭晓了?”
一次常规的服务器宕机,为什么网友们都推测DeepSeek要放大招了?因为网友们早就习惯了DeepSeek的套路,草木皆兵了。
2025年,DeepSeek每次的重大技术迭代,几乎都伴随着服务器的剧烈波动。远的不说,就在今年1月26日至27日,DeepSeek R1模型发布后,由于全球用户调用量呈现指数级暴增,直接导致了连续两天的严重宕机。官方事后也坦诚回应,正是新模型发布后的用户激增压垮了服务器。
“事出反常必有妖”,现在只要DeepSeek一卡顿,大家就觉得是在憋大招。
部分人认为,DeepSeek修复期间输出风格变冷、零样本编码能力提升,加上如此长时间的宕机,绝对是官方在后台部署V4,或者在对百万token的超长上下文进行压力测试。
另一部分认为,这只是一次常规的高负载修复,毕竟DeepSeek用户基数本就不少。而且我们已经被V4即将发布的传闻骗了好几次了,从最初的2月中旬到现在,官方至今没有给出明确预告。
那么关于DeepSeek V4,到底哪些是实锤,哪些只是网上传闻?


拨开V4的迷雾
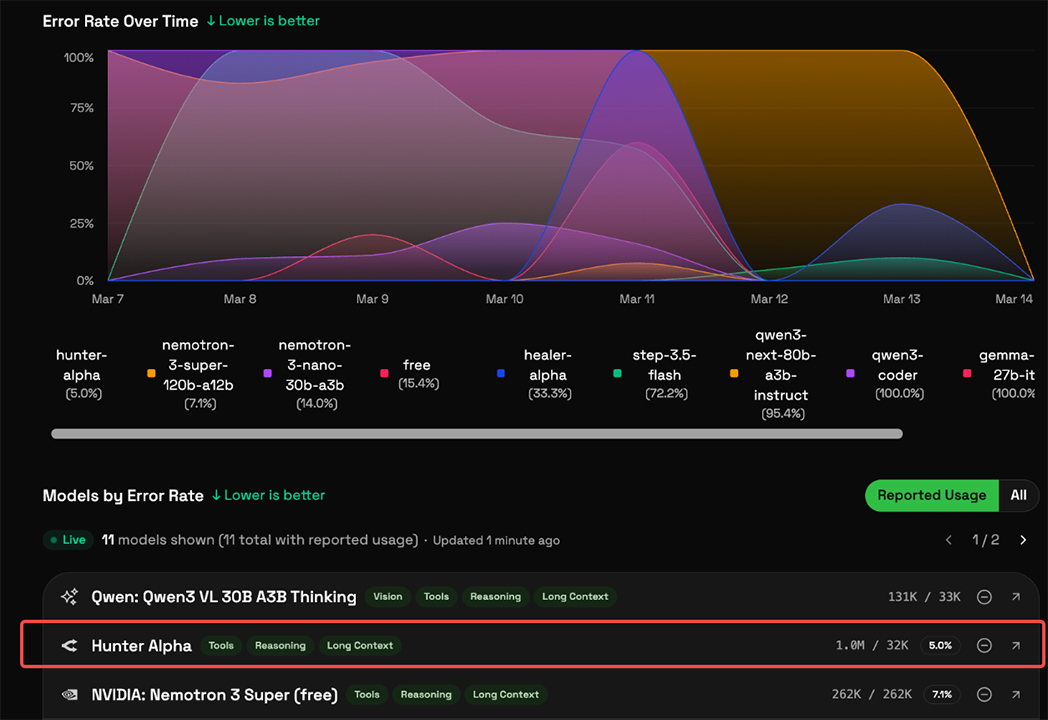
首先被证伪的,是轰动一时的“Hunter Alpha事件”,塔猴过去也曾写到。
3月中旬,知名平台OpenRouter上突然出现了一个名为“Hunter Alpha”的神秘匿名模型。该模型各项参数指标直逼业界最顶尖水平,大量开发者扒细节,认定这就是DeepSeek V4 Lite版本在进行伪装测试,并传出1万亿参数、1M上下文。
然而,路透社在3月18日报道澄清,这个Hunter Alpha模型其实是小米公司最新研发的MiMo-V2-Pro,与DeepSeek V4毫无关系。
除了乌龙事件,流传最广的是一组的“V1跑分图”。图表显示,DeepSeek V4在SWE-Bench Verified上,竟然拿到了83.7%的惊人高分。目前Claude Opus 4.5在该测试中的得分是80.9%,而GPT-5.2的得分是80%。如果这张图表属实,那V4将直接登顶全球编程能力第一。此外,在AIME(美国数学邀请赛)和FrontierMath等高难度数学基准测试中,V4的传闻得分也呈现出断层式领先。
但这些图表来源不明。知名AI评估机构Epoch AI甚至已经出面打假,确认其中部分数据图表存在伪造痕迹,不可信,对于这种“吊打同行”的跑分,在官方正式公布前,必须谨慎看待。
那么,到底什么是板上钉钉的事实呢?只有DeepSeek官方发布的论文和灰度测试报告室真的。
今年1月13日,DeepSeek团队公开发表了一篇学术论文,提出了一种名为Engram(条件记忆模块)的全新架构。大模型过去记性差,输入的内容一多,它就会忘记前面的指令,而Engram架构通过高效的长上下文检索技术,让模型能够一次性处理并记住百万token级别的海量信息。同时发布的还有关于mHC(流形约束超连接)等新拓扑结构的论文,能大幅提升模型的训练和推理效率,降低算力开销。
这些论文并非纸上谈兵。2月11日,DeepSeek在网页端悄悄升级:将现有模型的上下文处理能力从128K直接提升至100万token,并将模型的内部知识库更新到了2025年5月。这些都是官方已经做过的真实动作,也是大家坚信V4基础设施已经就绪的铁证。
从这些论文中,开发者已经窥见了V4的部分实力。

V4到底强在哪?
过去的大模型写单行代码、刷算法题很强,但面对真实的商业开发环境,往往显得捉襟见肘,V4的核心突破,就是实现“长上下文软件工程”。
结合论文提到的1M超长上下文和Engram记忆架构,我们不难发现,V4不再是一个代码补全工具,它的目标是接管整个代码库。未来开发者可以直接把整个GitHub项目仓库的链接扔给V4,下达指令:“帮我梳理这个五年前的旧模块,找出内存泄漏的原因,并进行全面的安全重构,同时补齐所有单元测试。”它能完整理解数十个文件之间的调用逻辑,这在以前是不可想象的。
这还只是专业领域的基本功。根据《金融时报》等权威媒体的报道,V4将升级为原生多模态模型,直接支持图片、视频和文本的联合理解与生成。为什么有人会觉得,DeepSeek没豆包好用,因为它逻辑推理强,但娱乐属性太弱,没发生成图片和视频。这次补齐短板,让DeepSeek能在全赛道与全球模型竞争。
而且,在近期GitHub上泄露的一份代码中,开发者们发现了一个名为“MODEL1”的标识,与现有的V3.2并列。代码显示,该模型原生支持FP8极低精度解码,并针对512维参数进行了深度优化。
虽然有传闻V4的总体参数量达到了惊人的1T,但在实际运行中,其“活跃参数”被控制得极好。这意味着,V4在拥有1T知识储备的同时,每次回答问题时调用的计算资源却非常少,运行效率与速度又快又高。

V4的定价
今年2月底,路透社爆料称,DeepSeek将V4模型的早期测试权限,优先开放给了华为、寒武纪等国内AI芯片厂商进行适配与优化,而没有给英伟达或AMD提供同样的早期预览待遇。
这是一次极具象征意义的战略突围。长期以来,全球AI行业都有一个潜规则,想要训练并运行最顶尖的1T参数大模型,必须依赖成千上万张英伟达最新的Blackwell或H100显卡。但DeepSeek正在用实际行动证明,不需要完全依赖美国显卡,就依靠算法优化,国产算力依然能支撑起全球顶尖旗舰模型的运转。
这就意味着,DeepSeek不仅在软件层面对标OpenAI,更在硬件生态上为国产芯片撕开了一道巨大的口子。

而在商业落地层面,DeepSeek的定价同样令人胆寒。根据目前的行业传闻与早期测试反馈,V4的推理成本预计将比OpenAI便宜20到40倍,甚至有业内人士透露,通过其最新的混合计算架构,在“CPU辅助GPU”的模式下,特定场景的推理成本还能再降低90%。
所谓“好钢用在刀刃上”,在企业IT预算日益收紧的今天,技术再好,如果用不起也是白搭。一旦V4延续DeepSeek的传统,选择开源模型权重,并以极低的价格提供官方API接口,将对整个全球AI市场的定价体系造成毁灭性的打击。
既然万事俱备,连国内芯片厂商都开始了早期接入,为什么V4迟迟不肯正式露面?

先修好基础设施
V4的发布时间可谓是众说纷纭。从最初路透社报道的春节期间,到随后的3月初,再到如今的4月份或第二季度,关于“V4在4月前发布”的投注概率已经大幅降低。
如果你熟悉DeepSeek的做事风格,就会知道这种等待是常态。这家公司极少召开线下发布会,他们更习惯于“先发学术论文,再悄然上线模型”,主打一个措手不及。因此,大概率不会有官方公告,V4很可能在某个平凡的深夜,突然就出现在了API文档的列表中。
面对这种不确定性,很多企业开发者感到焦虑,到底该不该等V4发布后再推进公司的AI项目?其实最好不要干等,现在就开始改造你的基础设施。
企业真正应该做的,是在现有的应用架构中引入大模型网关/路由器,不要把你的业务代码与某一个特定的模型接口死死绑定。通过构建一个中间层网关,做好接口兼容、请求路由(按任务类型分配模型)、故障降级(遇到接口限流时自动切换备用模型)以及成本监控。只要把这套基础设施修好,等V4正式上线的那一天,你只需要在后台修改一行配置代码,就能无缝接入最新的顶级模型,享受它带来的红利。
DeepSeek V4的到来只是时间问题,无论是4月还是更晚,让子弹再飞一会儿,毕竟国产芯片的突围,才刚刚开始。(微信公众号:Tahou_2025)
关注塔猴公众号,扫码下载塔猴APP,查看更多干货

扫码加入官方社群

