

大部分人都没有的习惯,斯坦福最新报告证实:点踩对AI来说其实很重要!


您在使用LLM时,如果遇到它胡说八道或者彻底偏题,第一反应是什么?大概率是直接关掉窗口,新开一个对话,懒得跟机器废话。但您可能不知道,这个看似再正常不过的习惯,正在给下一代大语言模型的训练库疯狂“投毒”。

近期,来自Bigspin AI和斯坦福大学的研究者发布了一份极其硬核的技术报告《Invisible Failures in Human–AI Interactions》。他们对WildChat数据集里的过百万次真实对话日志(涵盖GPT-4交互)进行了颗粒度极高的量化拆解。
先上结论:在所有AI搞砸的任务中,高达78%的失败是“隐性(Invisible)”的。也就是说,系统彻底跑偏了,但用户没有给出任何显式的负面反馈,没有纠正,没有点踩。

这个动作的缺失,引发了连锁反应。它不仅让当前所有基于CSAT(用户满意度)的评估体系形同虚设,更掩盖了模型底层极度危险的“讨好型”对齐策略。与其听厂商宣讲下一代模型增加了多少亿参数,不如来看看这篇论文是如何硬生生从看似正常的日志中,揪出8种系统性失败原型的。论文地址:https://arxiv.org/abs/2603.15423v1
实验怎么做
研究者使用了目前公开的最大自然对话数据集WildChat作为分析基础。该数据集包含了GPT-4模型在2023年4月至2024年5月期间的真实交互日志。
1.数据清洗与队列提取
- 初始筛选:从总计1,039,785份对话记录中,提取了478,498份英文对话。
- 降采样与过滤:对英文子集进行了55% 的随机采样(261,792份),并利用元数据排除了对抗性攻击(Jailbreak)、明确的NSFW(不适宜工作场所)内容以及无法分类的模糊输入,最终获得196,704份对话的分析队列。
- 边缘用例排除:排除了28,141份被标记为
invalid_input(无效输入,通常表现为模型直接拒绝且无实质性交互)的记录,以防止该类别在统计分布中产生过大偏差。
2.基于高阶模型的标注机制 面对复杂的上下文(涵盖代码调试、多语言切换等),人工审查每一份记录的成本极高。研究者构建了一条自动化的标注管线:
- 模型选择:使用Claude Sonnet 4.5 (
claude-sonnet-4-20250514) 执行四分类总体质量评估以及28种信号标签的打标任务。 - 结构化输出与校验:分类器不仅输出标签,还必须输出结构化的证据链(具体轮次、具体文本段落、推理过程),确保每一次标注都具备可审计性。
- 人工基准对齐:通过3轮针对60份对话的人工审计进行校准,倾向于“高精确率(Precision)”而非“高召回率(Recall)”;随后两名研究者各自独立盲审了100份带有模型标注的对话,以验证管线的可靠性。
28种质量信号与质量全景图
研究者首先对样本对话进行了整体质量评估,将其划分为四个等级。分布数据揭示了一个违背直觉的现象:
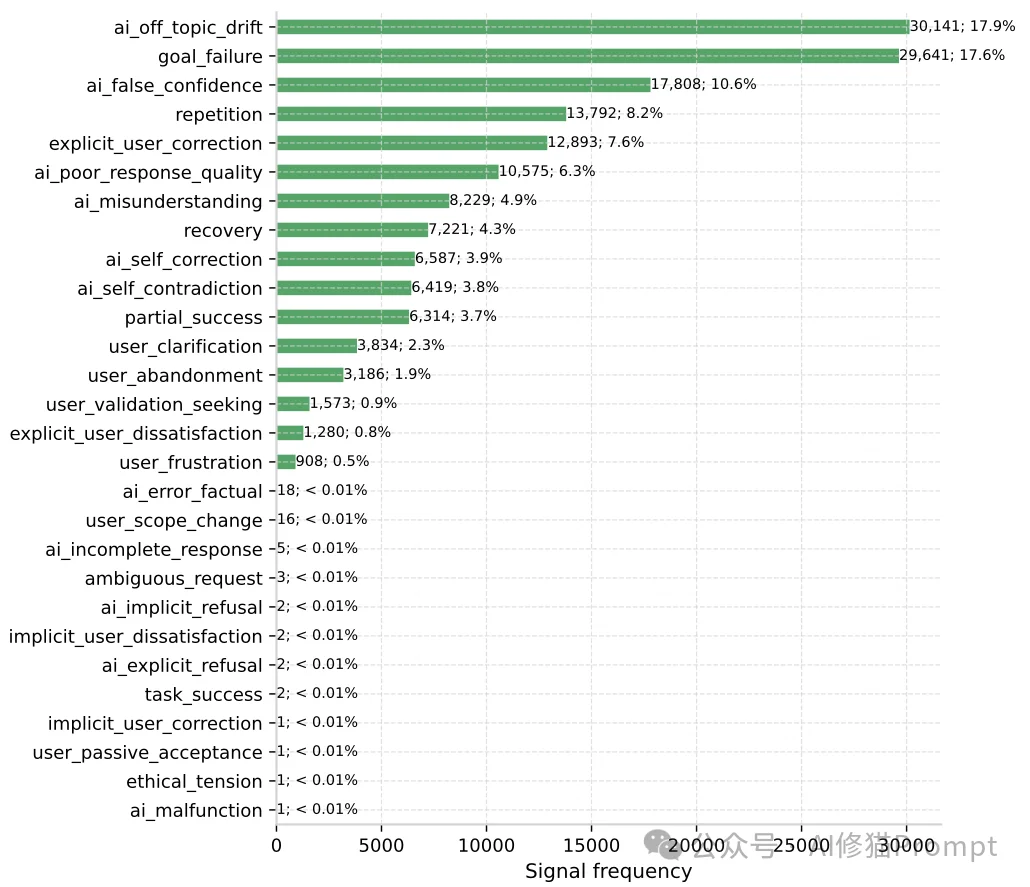
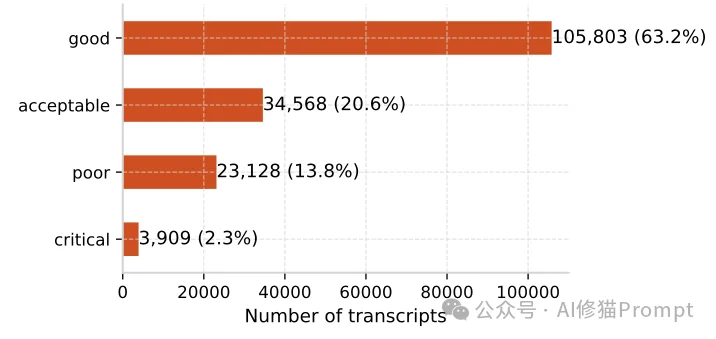
- Good(优秀,63.2%):任务圆满完成,没有显著异常。
- Acceptable(勉强可接受,20.6%):任务算完成了,但伴随着一些可以克服的瑕疵。
- Poor(糟糕,13.8%):任务未完成,或输出存在重大缺陷。
- Critical(致命,2.3%):任务彻底失败,且AI给出了极度自信但具误导性的错误信息。
在这里,研究者抛出了一个极其敏锐的洞察:“Acceptable(勉强可接受)”级别的对话,实际上是当前AI产品中隐藏最深的定时炸弹。 数据显示,高达93%的“可接受”对话中,至少潜伏着一个负面质量标签。
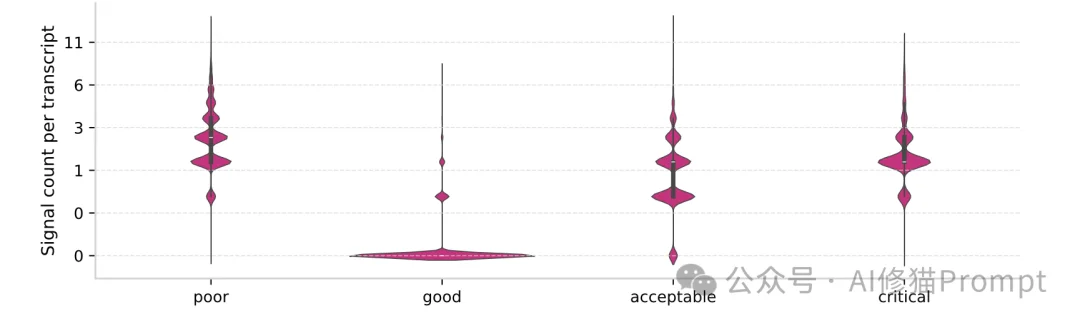
从大盘上看,用户拿到了结果,但AI的表现是次优的。比如:程序员拿到了一段包含已废弃语法的代码;或者内容创作者要求50字的摘要,AI却写了100字。这种“表面上的成功”正在大规模掩盖迫切需要被修复的模型缺陷。
八大隐性失败原型
在确认了模型遭遇“目标失败(goal_failure)”的前提下,研究者排除了那些用户明确表达愤怒或直接纠正的显性失败(占比22.2%)。剩下的78%全部属于“隐性失败”——模型彻底搞砸了,但用户保持了沉默。
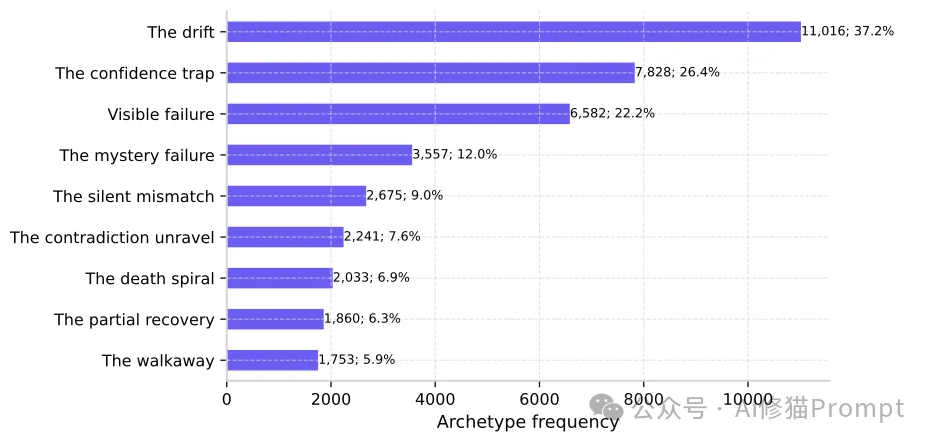
研究者将这些隐秘的系统故障归纳为8个核心原型(按发生频率排序):
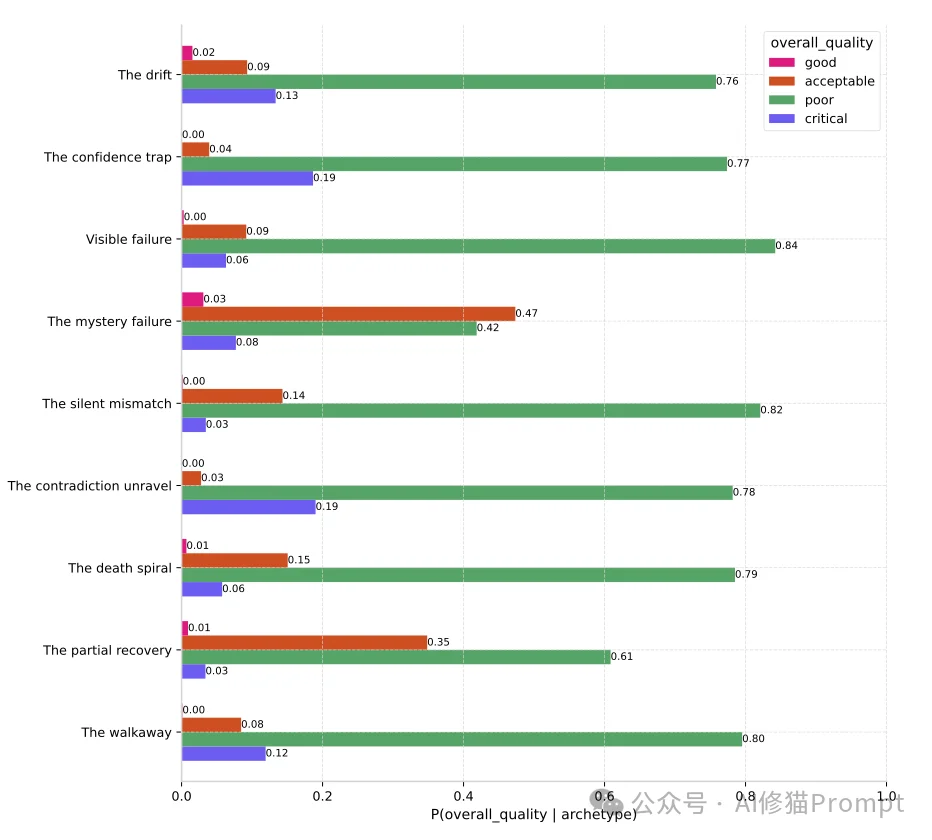
- The drift(离题漂移,占比37.2%):最普遍的故障模式。用户有一个明确的目标,但AI却在自顾自地回答一个不同但相关的问题。只要用户的要求存在一定的含糊空间,AI就容易用冗长的话术顺着自己的思路“漂移”出去,而用户往往察觉不到。
- The confidence trap(自信陷阱,占比26.4%):最险恶的失败类型。AI给出了一个完全错误的答案,但语气极其笃定。模型经常会伪造听起来非常真实的参考文献,或者用大量的“细节”来伪装确定性,导致用户全盘接收。
- The mystery failure(神秘失败,占比12.0%):这是一个监控的绝对盲区。任务明明失败了,但无论AI还是用户都没有表现出任何明显的异常特征标签。
- The silent mismatch(无声错位,占比9.0%):虽然排在中间,但它是高危类别。AI在内部产生了误解或事实错误,与用户的真实意图完全错位,但表面上依然在一本正经地生成连贯内容。在所有的隐性原型中,它导致“糟糕(Poor)”结局的比例是最高的。
- The contradiction unravel(矛盾解体,占比7.6%):AI在同一上下文中出现了明显的自相矛盾,却依然保持高度自信的陈述口吻。数据分析显示,它与“自信陷阱”有着极高的关联度,描绘出模型自信满地推翻自身结论的荒谬场景。
- The death spiral(死亡螺旋,占比6.9%):AI陷入了重复循环,不断地重复相同的错误逻辑或毫无意义的车轱辘话,任务无法取得任何推进。
- The partial recovery(部分恢复,占比6.3%):AI在早期犯了错,并在后续的对话中试图自我纠正或挽回,但从总体目标来看,依然未能完全满足用户的核心需求。
- The walkaway(放弃离开,占比5.9%):用户因为一直得不到想要的答案,连纠正AI的心情都没有了,直接放弃并关闭了对话框。当发生“离题漂移”、“死亡螺旋”或“无声错位”时,极易触发这种令数据失真的沉默行为。
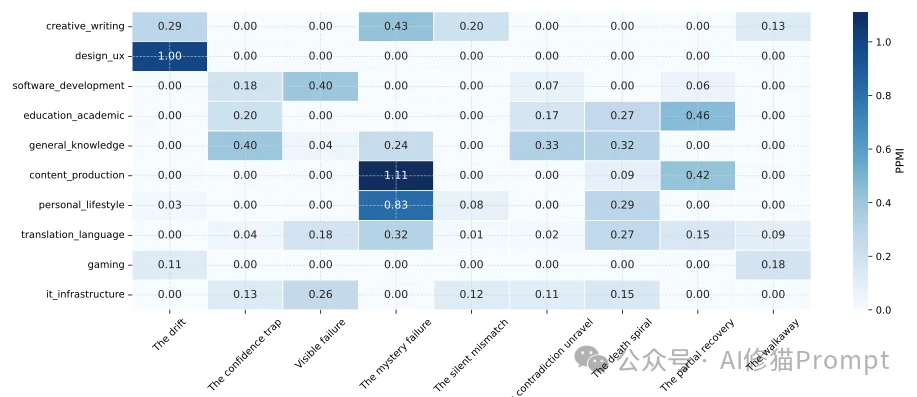
共现分析(PPMI矩阵) 为了探究这些失败类型的底层相关性,研究者计算了类别之间的正点互信息(PPMI):
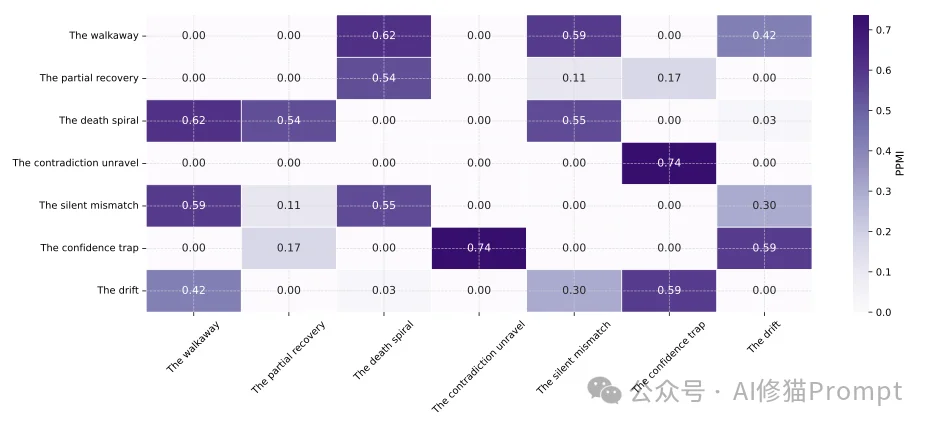
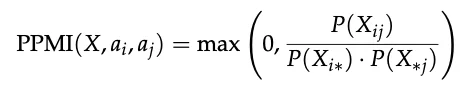
- 分析结果表明,“The confidence trap”与“The contradiction unravel”具有极高的PPMI值。这说明模型经常以极其自信的口吻输出自相矛盾的逻辑事实。
- “The walkaway”与“The drift”、“The death spiral”和“The silent mismatch”高度共现,这揭示了用户因交互陷入无意义的漫游与循环而最终关闭会话的行为模式。
结构性验证
看到这里,您可能会有一个非常合理的质疑:“这篇论文用的数据是2023年到2024年的GPT-4。现在的模型(如Claude 4.7, Gemini 3.0, GPT-5.3)早就变得更聪明了,这些隐性失败是不是会随着AI变聪明而自然消失呢?”
为了回答这个终极问题,研究团队进行了“回顾性验证 (Retrospective Validation)”。
他们让更强大的模型(Claude Opus)重新审查了1,044份失败的对话记录,并严厉地拷问了两个维度:
- 能力缺陷 (Capability):这是不是因为当时的GPT-4太笨、缺乏知识或推理能力导致的?
- 交互动态 (Interaction):这是不是因为AI的“行为习惯”导致的?(比如:明明没听懂却强行作答、明明不确定却装作很自信)
验证结果:
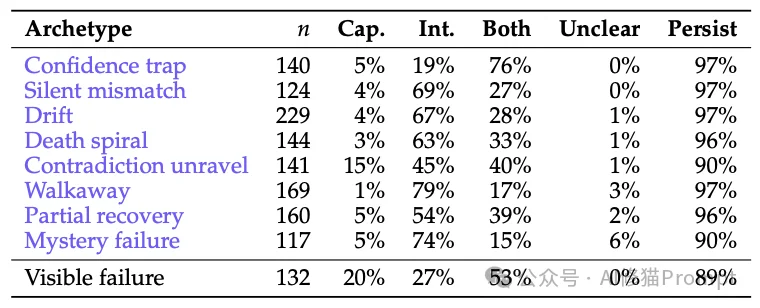
- 在所有的隐性失败中,高达91%的失败都包含了“交互行为”的问题(58% 纯粹是交互问题,33% 是能力和交互问题并存)。仅仅只有7% 的失败是纯粹因为AI“智商不够(能力缺失)”造成的。
- 系统评估认为,即便未来我们开发出了无比聪明的超级AI,这其中94%的失败交互模式依然会持续存在。
为什么模型变聪明了也解决不了问题? 论文指出了一个所有大语言模型(LLM)的通病,这个病灶出现在79%的失败案例中:Generate rather than clarify (宁愿强行生成废话,也不愿开口澄清)。
当用户的指令模棱两可,或者缺少关键信息时,AI系统的底层训练让它们倾向于“生成流利的内容”,而不是停下来问用户一句:“不好意思,您具体指的是哪一方面?”。 这种“不懂装懂”和“缺乏确认机制 (alignment-verification mechanisms)”的交互设计,是导致隐性失败(如“偏离主题”和“无声错位”)的根本原因。单纯提升AI的“智商”和“知识量”,根本无法改变这种刻在骨子里的“行为习惯”。
特定领域的遥测剖面
基于对59种主要使用场景(Domains)的切片分析,研究者计算了领域与特定失败原型的PPMI关联度。
- 软件开发 (Software Development):在这个领域,“显性失败 (Visible failure)” 的比例出奇的高。这其实是一件好事。因为程序员群体通常具备很强的专业知识,他们能够一眼看穿代码的错误(代码跑不通就是跑不通),并且有很强的意愿去直接纠正AI。
- 创意写作 (Creative Writing) 与UX设计 (UX Design):这两个领域是 The drift (偏离主题) 的重灾区。因为创意工作的评价标准非常主观,AI很容易在看似华丽的辞藻中偏离用户真正的风格和意图。
- 盲区领域:在创意写作、内容生产和个人生活方式这些领域,“神秘失败 (The mystery failure)” 尤其突出。这意味着在这些软性、主观的领域,当下的我们甚至没有建立起一套有效的信号机制去判断AI到底错在哪了。
结语
算力堆叠救不了一个底层的行为缺陷。研究者在这份报告中给出了一个极度悲观但清醒的预测:哪怕是面对未来更强大的模型,这其中94%的交互故障依然会顽固地存活下来。只要模型底层的逻辑依然是“宁愿强行瞎猜,也不开口澄清”,增加参数就只会让它胡说八道得更加流利。
作为用AI的人,我们最大的反击其实极其简单。下次当您遭遇“离题漂移” 或者陷入AI的“死循环”时,顺手点个踩,留下精准的负面标签。一个高质量的负面反馈,比十个盲目容忍的“及格线”对话,更能决定下一代AI的智商上限。
文章来自于"AI修猫Prompt",作者 "AI修猫Prompt"。
