

Qwen3.5-Omni发布:Plus/Flash/Light三版本、215项SOTA、多模态能力超Gemini

昨晚,阿里千问团队正式发布新一代模型Qwen3.5-Omni,该模型不仅原生支持文本、图片、音频、视频的实时交互,更在215项第三方基准测试中拿下了SOTA(业界最优)。
特别是在音频与音视频理解能力上,它全面超越了全球顶尖的Gemini-3.1 Pro。而且API调用价格不足Gemini-3.1 Pro的十分之一,每百万Tokens输入不到0.8元。
它所带来的声音克隆与音视频编程能力,将彻底改变游戏开发、短视频直播和自媒体内容生产。

215项SOTA
多模态已经成了如今模型的标配,很多人觉得Deepseek没豆包好用,就是因为Deepseek缺少多模态。但问题在于,过去大多数所谓的“多模态”,实际上是把语音转成文字,然后再把文字转成语音,本质上还是文本大模型处理。这种拼接模式不仅延迟极高,而且会丢失语气、情绪和环境背景音等大量关键信息。
但是这次最大的变化在于,Qwen3.5-Omni实现了真正的原生全模态。

Qwen3.5-Omni采用了先进的Hybrid-Attention MoE架构,并延续了经典的Thinker-Talker分工模式进行了底层重构。Thinker(理解中枢)支持256k的超长上下文,结合TMRoPE技术,它能精准抓取长时序中的信息,不会出现前面看完后面忘的现象。Talker(表达中枢)则引入了全新的ARIA技术与RVQ编码,这种架构直接替代了沉重的DiT运算,不仅彻底解决了语音输出中常见的漏字、数字误读问题,还赋予了模型强大的实时语音能力。
正是基于这种原生架构,Qwen3.5-Omni在DailyOmni、QualcommInteractive、Omni Cloze等视听交互测试中,得分大幅领先Gemini-3.1 Pro。在检测嘈杂环境抗干扰能力的WenetSpeech测试中,它的错误率更是远低于竞品,识别准确率极高。

但跑分高就一定好用吗?真正让业界坐不住的,是它在业务场景里的惊人能力。

声音克隆与实时交互
在声音方面,Qwen3.5-Omni简直是一位顶级的配音演员。
在官方展示的Voice Chat实时交互体验中,Qwen3.5-Omni展现出了恐怖的声音克隆能力。只需提供几秒的参考音频,模型就能迅速克隆出音色,连情感起伏、停顿习惯和说话风格都一并复刻。官方透露,这项功能的工程化部署即将全线上线。
我们来看看它的核心亮点。
实测案例一:情绪控制与语义打断
在实时对话场景中,用户可以随时通过语言指令控制AI的语速、音量和情绪。例如,你可以直接对它说:“请用开心一点的语气,语速加快一倍给我讲这个故事。”AI会在下一秒无缝切换状态。
同时它还支持语义打断,以前我们和AI语音,咳嗽一下或者旁边有杂音,AI就会停止说话。而Qwen3.5-Omni能够分辨咳嗽、背景噪音与真正插话的区别。当用户想要打断并提出新问题时,它会自然地停下,听取新指令,实现自然对话。

实测案例二:方言与小语种
在多语言Multi-Lingual测试中,Qwen3.5-Omni显著优于Gemini-2.5-Pro-TTS。新模型支持113种语种及方言的语音识别,同时支持36种语种及方言的语音生成。哪怕是使用人数不足一百万的毛利语,或者是国内的海南方言,它都能识别并流利对答。
声音克隆与多语言能力的结合,将对诸多行业产生颠覆性影响。
在游戏行业,开发一款拥有大量NPC的RPG游戏,配音成本占据了极大的预算。现在,游戏公司只需要录入样本,就能批量生成无数个拥有独立音色、情绪饱满的NPC对话,并且可以根据玩家的实时互动,动态改变NPC的语气。
在直播与自媒体领域,虚拟主播和内容生产也同样受用。创作者可以克隆自己的声音,输入文案,就能批量产出短视频配音,解放人力。
除了声音克隆大放异彩,Qwen3.5-Omni在视觉与代码的结合上也同样出色。

音频Vibe Coding
AI编程最火的词莫过于Vibe Coding(氛围编程),但过去的Vibe Coding大多依赖纯文本或静态图片驱动。Qwen3.5-Omni开启了下个阶段,Audio-Visual Vibe Coding(音视频氛围编程)。
在实测视频中,测试者打开电脑摄像头,拿出一张画有迷宫草图的白纸放在镜头前,一边指着草图,一边口述:“帮我写一个网页版的吃豆人游戏,UI界面参考这张纸上的布局,主角颜色要设置成亮黄色,吃到金币时要有音效反馈。”
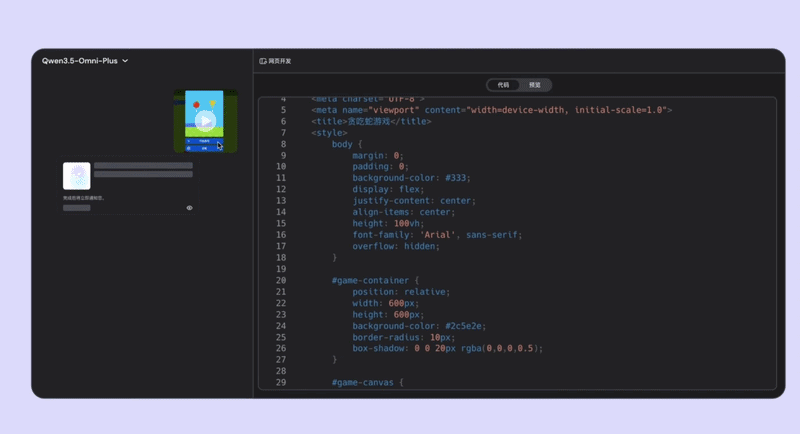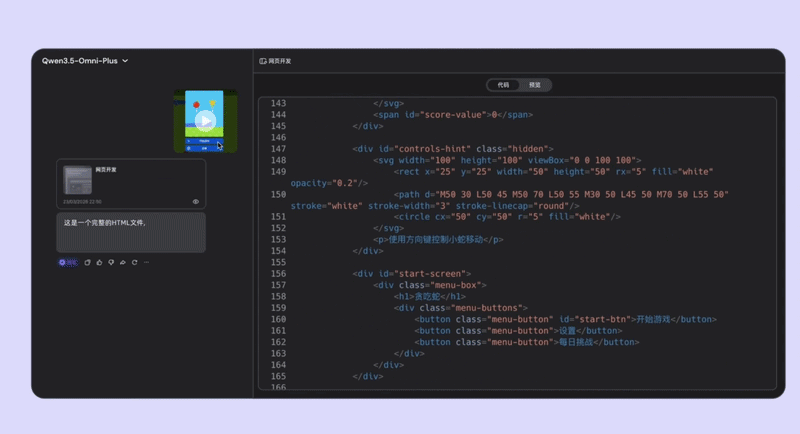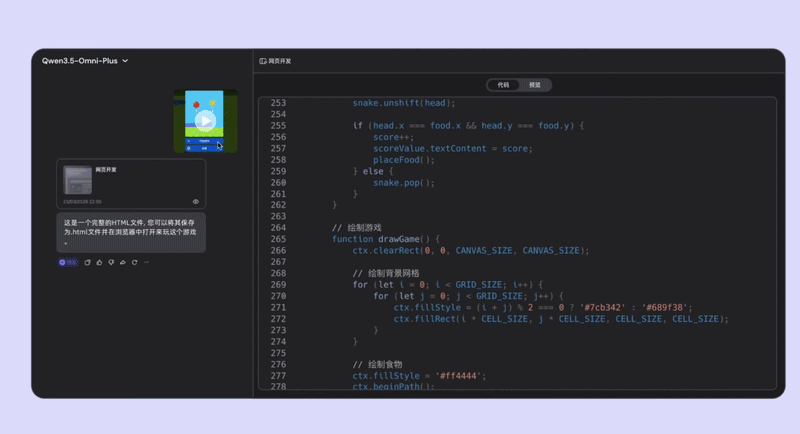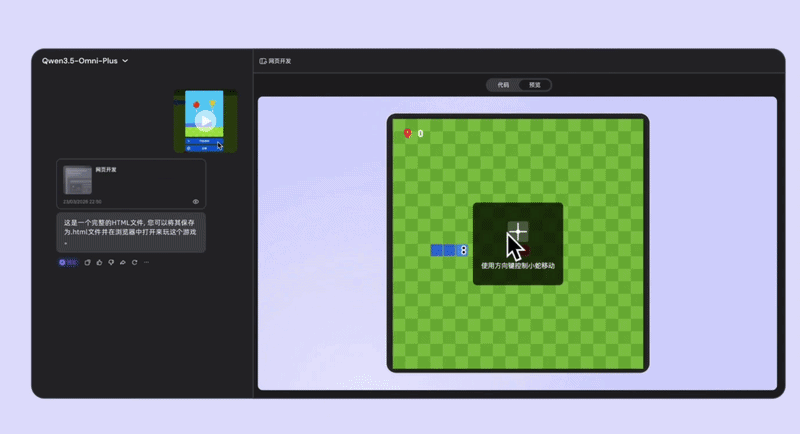
Qwen3.5-Omni在短时间内就理解了画面中的草图结构,结合语音需求,生成了带有复杂UI的产品原型界面和完整的Python/前端代码。用户只需点击运行,一个完整的网页游戏就诞生了,真的“动动嘴即可编程”。
在另一个实测视频中,Qwen3.5-Omni对于游戏录屏进行了拆解。它可以自动生成带有时间戳的字幕,精准识别画面主体、人物关系、背景音乐变化、镜头场景切换,甚至还能进行说话人映射,分清每一句话是谁说的。
结合其原生支持的10小时音频或400秒720p视频输入能力,开发者可以直接把一段热门游戏的游玩视频发给模型,要求它:“分析这段视频里的战斗逻辑和角色互动,帮我生成一个类似的核心玩法代码框架。”模型就能直接从游戏画面和视频输入中提取逻辑,生成动态内容。
实质变化在于,过去开发一款独立游戏,需要写案子、美术画图、程序敲代码,需要一个专业团队耗费数月。现在,AI根据看视频或作者描述出Demo,对于独立游戏开发者来说,是史诗级升级。

千问的生态版图
为了满足不同企业和开发者的需求,Qwen3.5-Omni放出了全家桶阵容:
- Plus版:旗舰级高性能模型,适合处理复杂的全模态推理和重度开发任务。
- Flash版:主打平衡,在保证极高智能水平的同时,提供更快的响应速度,适合实时直播互动和高频次调用的自媒体工具。
- Light版:轻量级模型,成本低,为边缘设备和简单查询任务打造。
在定价策略上,阿里云展现出了极强的野心。
在阿里云百炼平台上,开发者和企业调用Qwen3.5-Omni模型的API,每百万Tokens输入不到0.8元。这比它的直接竞品Gemini-3.1 Pro的十分之一还要低,主打一个价格战,抢占市场。
目前,Qwen3.5-Omni的生态入口已经全面敞开。普通用户可以直接前往Qwen Chat网页端,点击右下角的语音/视频按钮免费体验实时交互;开发者可以在Hugging Face的专属合集页面找到离线Demo和在线语音Demo进行二次开发;企业级用户则可以直接登录阿里云百炼控制台,调用已经全面上线的Plus、Flash、Light三种API。
同时,当前通义千问已稳居中国企业级大模型调用市场第一,服务涵盖互联网、金融、消费电子及汽车等重点行业超过100万家客户。这次Qwen3.5-Omni的发布,凭借其原生多模态预训练(包含海量文本/视觉以及超过1亿小时音视频数据)的深厚底蕴,必将进一步巩固其在企业级市场的霸主地位。微信公众号:Tahou_2025)
关注塔猴公众号,扫码下载塔猴APP,查看更多干货

扫码加入官方社群

