

阿里又一个王炸!Qwen3.5-Omni 全模态硬核实测


兄弟们,源神又发力了!
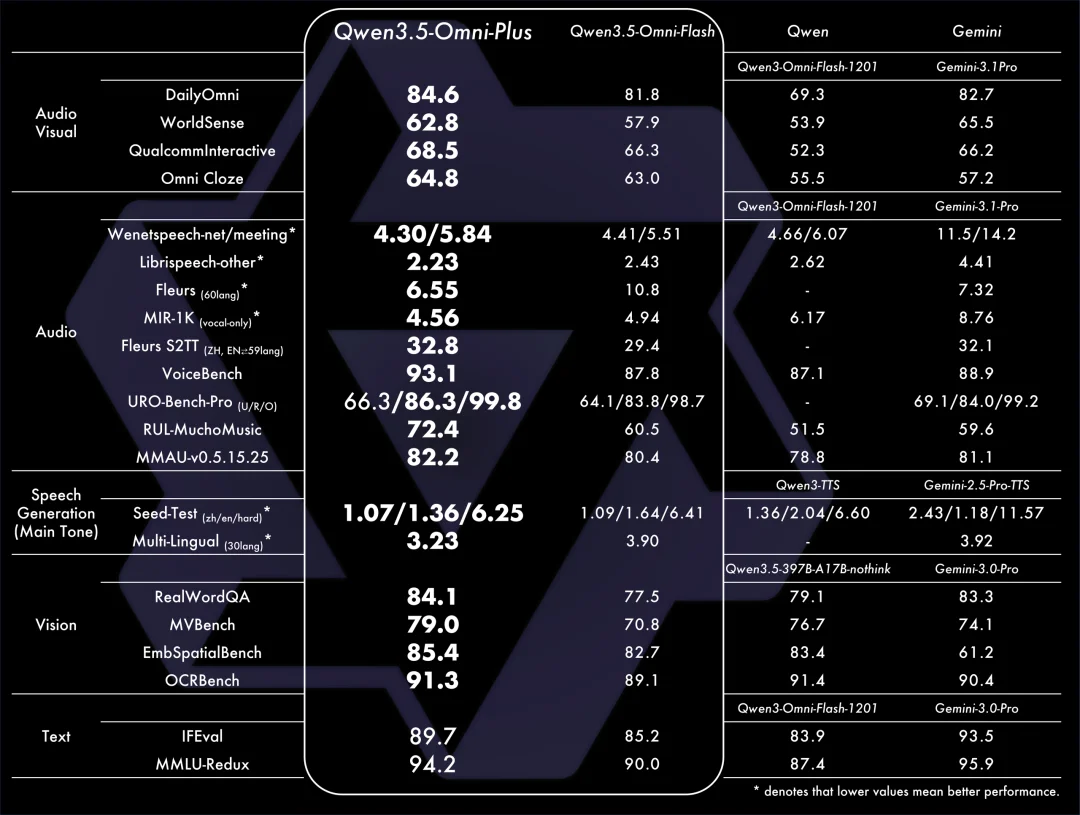
阿里刚刚发布了最新一代全模态大模型 Qwen3.5-Omni,在通用音频理解、推理、翻译和对话等维度,已全面超越 Gemini 3.1 Pro。
所谓全模态,在于它拥有了接近人类的“感官”。它能听、能看、能说、能写。
其实上一代 Omni 就已经很猛了,但这次 3.5 版本经过超过 1 亿小时原生音视频数据的淬炼,直接在 216 项音视频 Benchmark 里刷出了 SOTA 成绩。
我用三句话总结一下这次的升级幅度:
架构大换血: Thinker 和 Talker 模块均升级为混合注意力 MoE 架构,提供大中小三个尺寸,从云到端全覆盖。
256K 超长上下文: 能一口气吃透 10 小时的会议录音,或者 400 多秒的 720P 视频。
语种库扩容: 直接支持多达 113 种语种方言的精准识别,以及 36 种语音生成。相比上代翻了好几倍。
既然参数这么顶,实战到底能不能打?废话不多说,我们直接进入极限测试
测试一、Vibe Coding 跨代
这个是我最期待的功能,也是我觉得最能体现 Qwen3.5-Omni 代际升级的能力。
莫理之前写过不少关于 Vibe Coding 的内容,从最早的用文字描述需求,到后来的给AI看一张图,但这些本质上还是文字和图片作为输入。
而 Qwen3.5-Omni 把这件事推到了一个新阶段,我们可以给 AI 一个完整需求的视频,它就能直接帮你落地。真正实现了音视频 Vibe Coding。
为了验证这一点,我在 A4 纸上画了一个非常粗糙的产品手绘稿,就是一个外卖点餐页面的草图。然后用手机录了一段视频,一边拍这个手绘稿一边说着话描述交互逻辑:

然后把这段视频直接丢给Qwen3.5-Omni,让它根据视频内容,制作符合要求的 html 文件。

它不仅听懂了我说的每一个交互逻辑,还看懂了我画的那个潦草的手绘稿,先是仔细分析了我的需求,说明了网页包含的内容,最后直接输出了一套带有完整UI的前端代码。
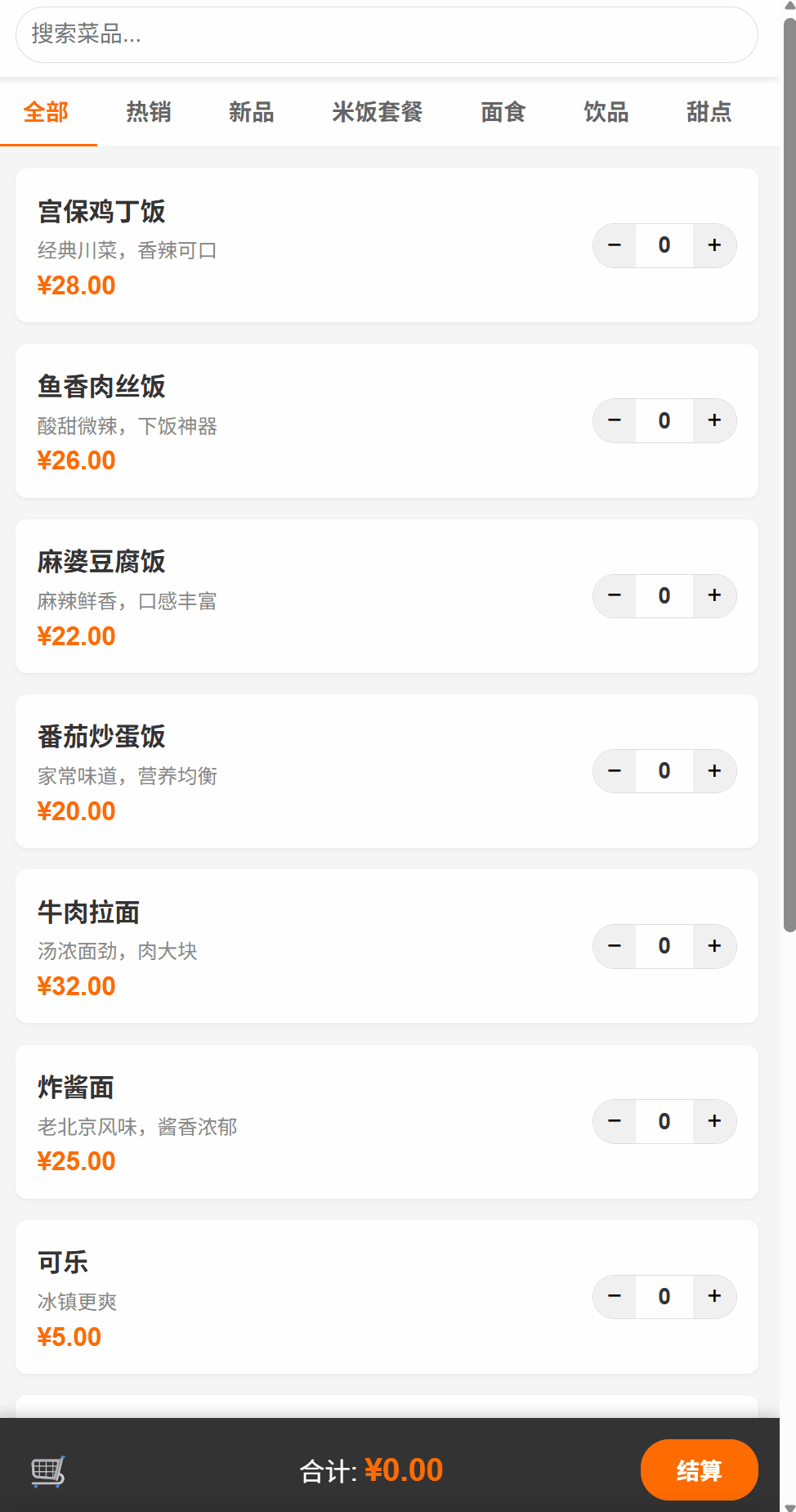
搜索栏、分类标签、菜品列表、加减按钮、底部购物车,全都有,而且交互逻辑和我口述的基本一致。甚至我在草图中没有画出来的底部购物车展开页面,它只听我说,就记住了要求。

从打字到动嘴,从画原型到拍视频,Vibe Coding 的门槛被再次击穿
哪怕是完全不懂技术的业务人员,只需像跟同事开会一样边画边聊,AI 就能将想法转化为可运行的代码。这对整个开发流程来说,无疑是降维打击。
测试二:实时语音对话
这个环节,我原本是抱着找茬的心态来的。因为市面上的语音助手大多有个通病:要么疯狂抢话,要么反应极其迟钝(比如你说句“嗯嗯”,它就以为你在下指令而强行打断)。
但 Qwen3.5-Omni 这次强化的“语义打断”,据称能精准区分用户的真实指令与无意识附和。为了探探它的底,莫理专门设计了一个充满陷阱的实战场景——“武汉一日游规划”,连续对它进行四重抗压测试:
① 联网搜索

得益于原生支持 WebSearch,我先让它查武汉明天的天气,并推荐 3 个适合带老人小孩的户外景点。它准确播报天气后,顺势推荐了地势平坦的东湖绿道,起步很稳。
② 无意识附和识别
当它滔滔不绝介绍东湖时,我故意用极其随意的语气插话:“嗯”、“哦,这样啊”。关键点来了:Qwen3.5-Omni 毫无波澜。它没有卡顿,没有傻乎乎地回一句“我在”,而是保持原有节奏继续介绍。也就是说,它知道这是人类交流时习惯性的附和,而非打断指令。
③ 强语义打断与需求急转弯
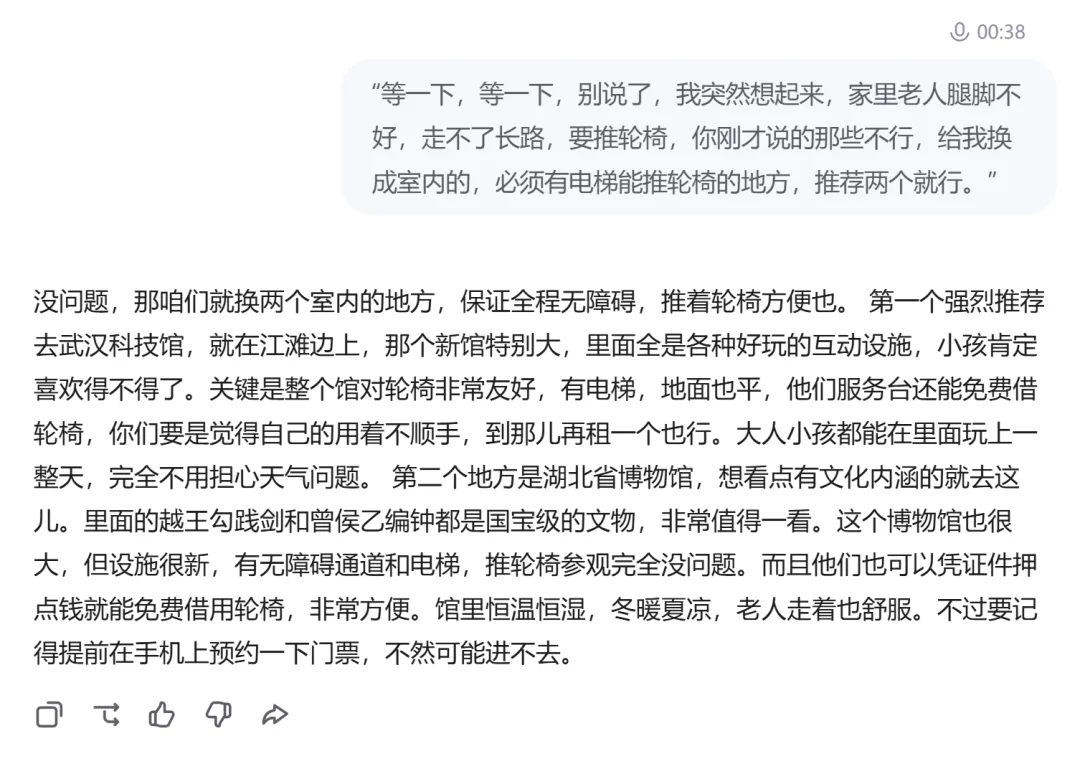
这是最核心的测试。当它介绍到第二个景点时,我突然提高音量:“哎等一下!别说了。我突然想起来……” 就在听到“等等”的瞬间,系统干净利落地闭嘴了。没有把剩余的半句话硬憋出来。紧接着,我要求把户外景点全换成室内无障碍场所,它在几秒内迅速完成了逻辑的转弯,给出了全新方案。
④ 短期记忆回溯
最后莫理还设了一个陷阱。
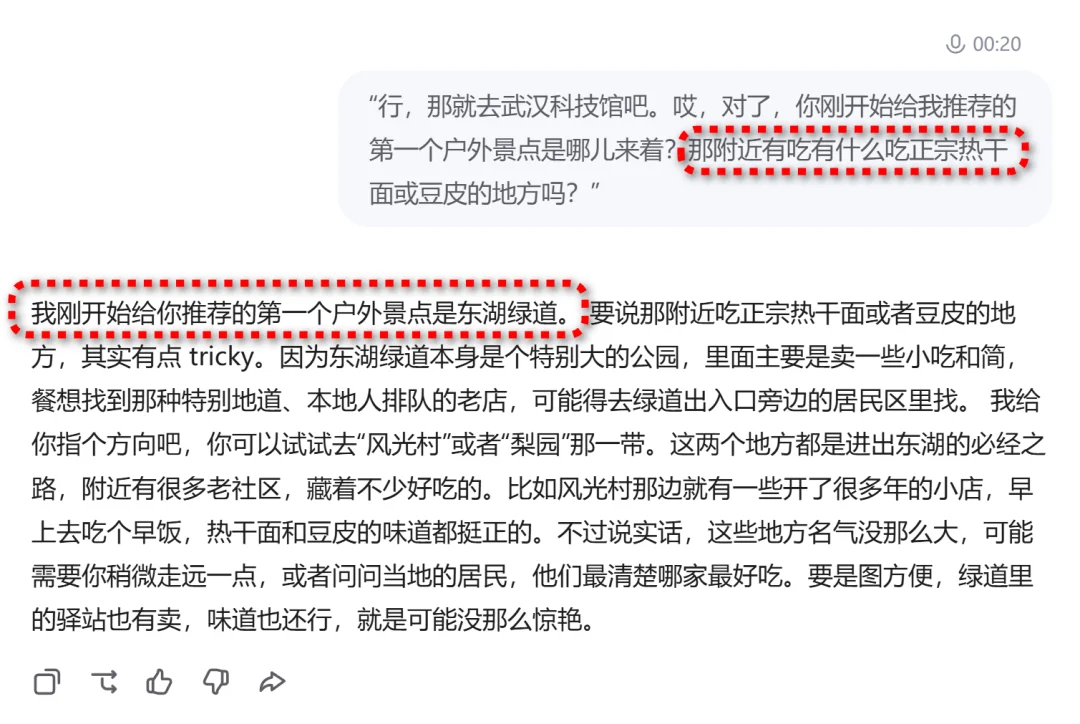
我问它:“你最开始给我推荐的第一个户外景点是哪儿来着?附近有吃正宗热干面的地方吗?”。
要知道“东湖绿道”已经是好几轮对话之前且被打断的信息了。结果它不仅精准调取了记忆,还给出了一份极其诚实的美食攻略。回看聊天记录,它把我说瓢的那几个字也给自动修复了
这套行云流水的表现,已经完全达到了一个优秀人类助理的基准线。联网、识音、急停、回溯,四个能力全部满分通过。该听时听,该停时停,交流质感与真人无异。
并且,它还支持端到端的语音控制,可调节情绪、音量,甚至支持音色克隆。甚至于你可以让模型像人一样遵循指令来对声音的大小、语速、情绪等自由控制。
测试三:复杂音频与方言解析
最后,我们来看看它在多语言和复杂声学环境下的解析力。
① 高噪环境 + 多方言混杂
我找了一段极具年味的“各地方言拜年合集”。这段 34 秒的音频里,不仅有男女老少混杂的普通话与各地方言,还有嘈杂的乐器音。
在转录指令下达后,不到十秒就完成了带有时间戳的逐句分析。

这个输出结果确实意外。
因为这段音频的声学环境极其恶劣,全程都伴随着高分贝的背景音乐。但最让人惊喜的,是它展现出来的推理深度,是真正听懂了方言背后的文化特征:
你仔细看分析过程,它把判断依据讲得清清楚楚:
面对四川话,是因为“乐”和“康”在西南方言里的声调起伏;听到“老少爷们”、“吃嘛嘛都香”,就能凭借这些极具地方特色的词汇锁定天津话;甚至连台湾腔那种语速平缓、咬字温柔的声学特质,都被它敏锐地解析了出来。这已经完全脱离了传统语音识别单纯听字的范畴
② 粤语俚语 + 情绪音效解析
拜年那个还算规矩,我又找了个更刁钻的,一段粤语麻将梗的搞笑音频。
这段音频 32 秒,一个女生用撒娇又带点俏皮的语气反复问对方"你想我叫牌呀?",中间还夹杂着弹簧声、whoosh音效,结尾还有突兀的牛叫。
结果同样令我惊叹。它不仅一字不差地转录了“你唔出声,我点知你想我叫牌呢”这种极具地方特色的俚语。
还可以让它交付一份音频特征报告,从说话人的性别、语气,到背景音乐的节奏感,再到那几个搞笑的物理音效,全部分门别类地标注得清清楚楚。

从这几个刁钻的测试不难看出,Qwen3.5-Omni 在多语种和复杂音频环境下的解析力,已经具备了极高的商用价值。对于出海企业或需要高频处理跨国会议的团队来说,无疑是重塑工作流的顶级利器。
压轴测试:视频深度解析
刚才我们测的都是极端条件下的纯音频环境。但既然叫全模态,音画高度协同的理解能力也必须得拉出来溜溜。这几天我正好被拉片折磨得够呛,干脆就把这个纯粹拿命熬的苦力活丢给了它。
我找了一段两分半的《沙丘》预告片,给它的指令非常直接:“对视频进行切片,标注时间戳,细致分析每个镜头的构图、色彩和运镜。”

为了直观,我截取了其中两个反差比较大的切片节点,大家可以看一下它的原话:
00:10.500 – 00:19.700
画面突变为辽阔沙漠远景,暖黄色调,阳光洒满沙丘。一对年轻男女坐在帐篷内,女子头带蓝色发带,男子轻抚她肩膀。两人低声交谈,字幕同步出现:“如果我们有女儿…给她取甚么名字?”、“她的名字会是甘尼玛”。镜头由中景推近至面部特写,捕捉眼神交流,背景虚化,突出情感细腻。
00:54.000 – 01:04.800
快速剪辑战斗场面:激光束划破夜空、爆炸碎片四溅。镜头多用手持晃动模拟临场感,配合激昂合唱与鼓点。字幕:“我越是战斗,敌人就越会反击”。视觉冲击力强,节奏紧凑。
平心而论,作为一份由机器生成的拉片报告,已经非常扎实了。
学过影视的同学都知道拉片有多折磨人。以前这就是个纯体力活,你得一帧帧按空格键暂停,肉眼死抠画面,再把构图法则、调色倾向、镜头的推拉摇移以及背景配乐的情绪变化。
但你看 Qwen3.5-Omni 的输出,它没有在这里给你强行抒情或者瞎编剧情,而是像一个极其严谨的场记。它不仅准确踩中了时间轴上的每一个切分点,还能准确抓取了“低角度仰拍”与“心理张力”的对应关系,看懂了武戏里“手持晃动”带来的临场感,甚至连背景音里“低频弦乐”和“激昂合唱”的切换都没放过。
它在做的事情,本质上是把一段极其复杂、非结构化的音视频流,扒成了一份高度结构化的数据字典。对于影视创作者找视听参考、或者相关专业的学生做拉片分析来说,这省下的是结结实实的几个小时的“垃圾时间”。
写在最后
从刚才那些实测场景中抽离出来,纵观整个赛道,这两年国产大模型的进化速度,用一个“卷”字都不足以形容。
我们见证了它从最初只能单纯敲字聊天,到后来学会看图写诗,再到今天 Qwen3.5-Omni 展现出的全模态融合:听、看、说、写、实时交互,一气呵成。
256K 的超长上下文、10 小时的极限音频解析、113 种语种方言精准识别、音视频原生的 Vibe Coding、真人级别的语义打断、甚至音色克隆与原生 WebSearch 工具调用……
这些能力单拎出来,每一个都足够硬核。但它最恐怖的地方在于,它们都生长在同一个底层架构里,是一种真正意义上的原生全模态,而不是靠多个单模态模型东拼西凑出来的“缝合怪”。
这种底层技术的质变,可以说在 B 端产业界撕开了一个巨大的想象空间。比如海量短视频和直播智能审核、长视频平台的自动打标签分类。
而对于我们普通玩家来说,你可以把 Qwen3.5-Omni 当成“龙虾”的大脑,让它去后台挂机收听那些动辄几小时的硬核播客、纪录片或者公开课。
纸上得来终觉浅。目前模型已经全面开放,想要亲自给它上上强度的兄弟们,即刻就可以登录阿里云百炼以及 Qwen Chat 去实操体验啦
Qwen Chat: https://chat.qwen.ai
API 离线(国内):
https://help.aliyun.com/zh/model-studio/qwen-omni
API 实时(国内):
https://help.aliyun.com/zh/model-studio/realtime
文章来自于微信公众号 "莫理",作者 "莫理"
