

腾讯云Agent Memory龙虾记忆服务:一键开启、插件接入与功能详解

今日,腾讯云正式发布Agent Memory(龙虾记忆服务)这款插件向全网开放,支持免费一键开启。
实测数据显示,接入该服务后,OpenClaw的回答准确率升至76.10%,原生记忆提升59%,事实召回率提升160%以上。

龙虾记忆服务强在哪?
原生龙虾依赖本地Markdown文件和每日日志,一旦对话周期拉长、交互频次升高,系统就会暴露缺陷。当日志文件不断膨胀,受限于模型的固定上下文窗口,检索效率会指数级下降。AI就会开始输出错误信息,忘记最初的用户要求。
而TencentDB AI-Memory的本质是一个云端增强层,它不直接作为记忆增强插件并行运行,通过持久化的数据存储方式,彻底解决交互信息丢失的问题。它能将的文本记录,升级为了结构化的数据资产。
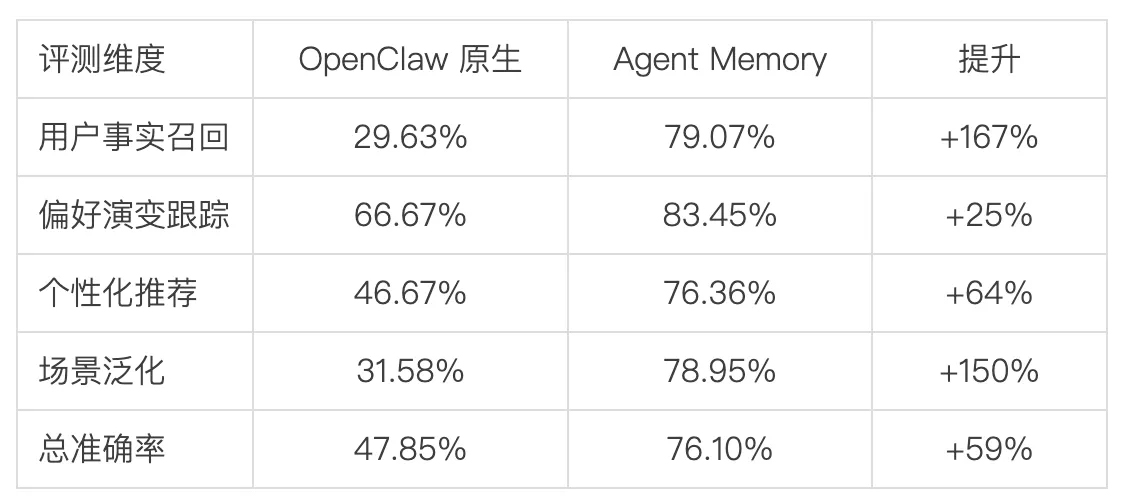
基于 PersonaMem 评测集结果
官方资料显示,腾讯云数据库团队自研了四层渐进式记忆金字塔,改变了数据留存方式。
首先是L0 原始对话,全量保存交互日志,不加任何过滤。这确保零信息丢失,无论系统运行多久,底层原始数据始终完整可溯。
其次是L1 原子记忆,,AI会自动提取高价值事实、偏好与约束条件。用户告诉它一次“我只用Python写后端”,系统就会生成一条原子记录,在后续的每一次代码生成中强制生效,避免对话越久越健忘。
接着是L2 场景分块,系统会按项目或上下文聚类记忆块,实现结构化召回与精准匹配。工作场景聊代码,生活场景聊菜谱,两套数据完全分离,不串场。专用索引引擎的介入,让信息提取的准确度远超上下文搜索机制。
最后是顶层的L3 用户画像,系统通过长期的数据积累,持续构建用户画像。这带来了跨会话个性化体验,AI彻能底适应用户的交互习惯,形成专属的数字人格参数。
看懂了这四层架构,我们就能明白这款插件的亮点:核心偏好锁定、跨会话任务接力、高精度结构化召回、统一多平台体验。无论用户通过微信、企业微信还是飞书接入,都能获得高度一致的交互反馈。

一键接入指南
Agent Memory的接入体验非常简单,对于部署在轻量应用服务器上的用户,腾讯云提供了一键开启功能,整个激活过程最快1分钟完成。
第一步,登录腾讯云控制台,进入Lighthouse实例列表。
第二步,选择正在运行的OpenClaw实例,在左侧菜单点击“应用管理”,进入“记忆管理”面板。
第三步,找到TencentDB AI-Memory记忆增强插件,将底部开关拨至“启用”状态。
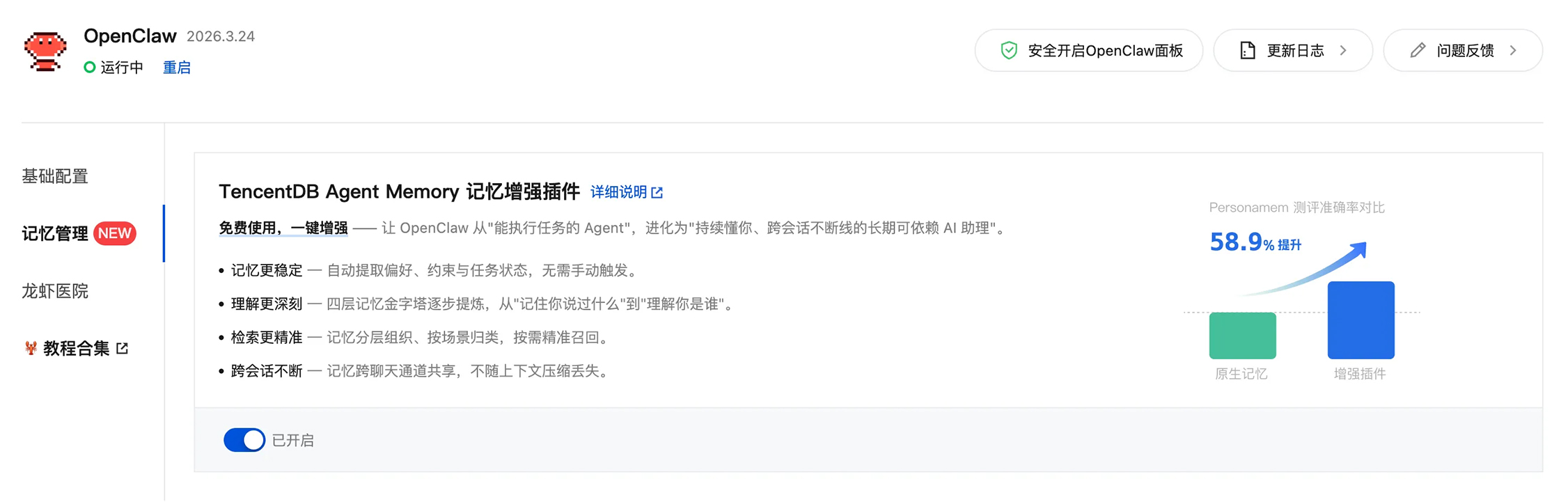
第四步,在弹窗中点击“确认”,系统会自动重启Gateway。
等待Gateway运行正常后,记忆增强服务立即生效。
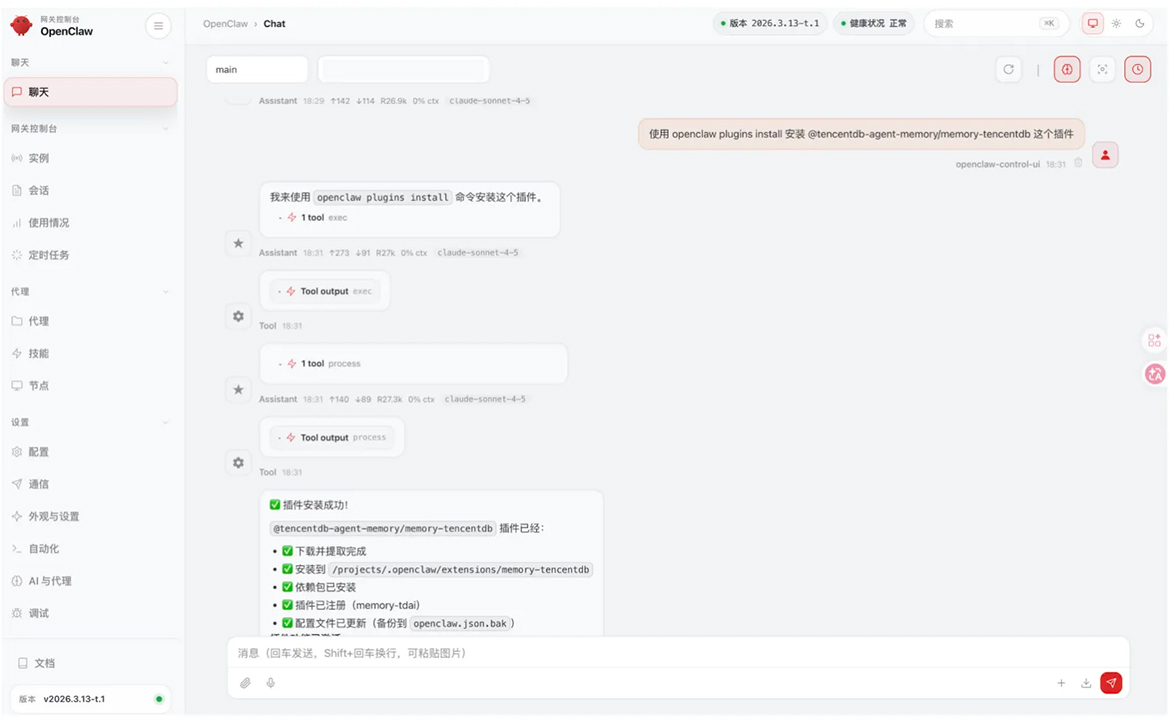
除了云端一键部署,针对本地用户,在龙虾聊天窗口输入指令:使用 openclaw plugins install 安装 @tencentdb-agent-memory / memory-tencentdb 这个插件,敲击回车,即可完成部署。
对于有高级语义检索需求的高阶玩家,还可以在服务器的openclaw.json文件中编辑插件配置。默认情况下该功能关闭可以节省资源,开启后将获得质的飞跃:
通过修改上述配置文件,开发者可以直接接入OpenAI兼容接口,调用更强大的向量模型进行数据检索。
此外,腾讯云还提供了基于COS Vectors向量存储桶的备选插件方案,通过执行简单的安装脚本,即可实现Auto-Recall与Auto-Capture功能。

Pro版
为了应对多用户、企业级协同场景,腾讯云即将推出Agent Memory Pro版。
该版本基于腾讯云向量数据库构建,解决了海量数据并发问题。在记忆规模持续增长至TB级别后,依然能保持毫秒级检索性能。同时,Pro版将全面支持数据备份、回档、权限控制等企业级数据治理能力,用于支撑企业长期记忆与安全管理。
这其实都是腾讯云Agent Memory Lake(记忆湖)架构的核心组成部分。
基于Data Platform,整合COS对象存储、GooseFS分布式缓存系统、MetaInsight元数据提取等底层组件,这套记忆湖方案支持结构化与非结构化记忆数据的大规模存储、检索与RAG注入。
无论是自动驾驶的实时环境数据处理、千万级并发的智能客服系统,还是大规模机器人的协同作业,Agent Memory Lake都能提供强大的底层基建支撑,帮助智能体突破算力与存储的物理边界,实现持续的数据迭代与逻辑进化。
拥有长期记忆能力的智能体才具备持续交互能力,这次TencentDB AI-Memory以最轻量的方式,让小龙虾彻底摆脱了遗忘的技术限制。(微信公众号:Tahou_2025)
关注塔猴公众号,扫码下载塔猴APP,查看更多干货

扫码加入官方社群

