
SVG性能比肩GPT/Claude,腾讯开源3B模型HiVG,让Token「懂几何」


当所有人都在卷模型规模的时候,有人换了一种思路:
与其无限堆参数,不如从根本上重新思考「token该怎么设计?」
仅3B参数的HiVG,在SVG生成任务中多项指标超越了GPT-5.2、Claude-4.5-Sonnet等闭源模型。
一句话概括:
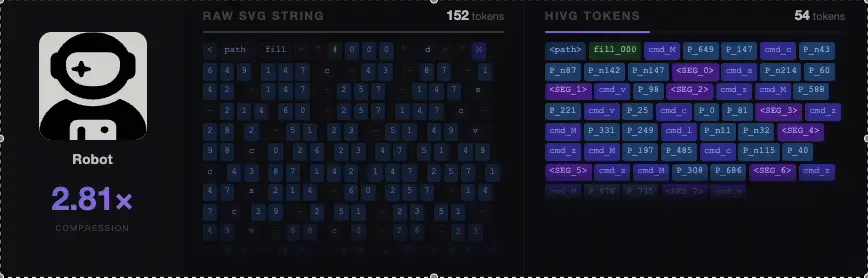
HiVG是一个面向SVG生成的层次化分词框架,在减少63.8% token数量的同时,以仅3B参数在多项指标上超越所有开源SVG模型和GPT-5.2等闭源模型。
背景:SVG生成为什么这么难?
矢量图形(SVG),设计圈的“六边形战士”——无限缩放不糊、文件小到离谱,图形编辑友好,一直是设计师和开发者的心头好。最近,随着大语言模型(LLM)的崛起,研究者开始尝试将SVG当作“代码”来生成——给一句话描述,甚至丢一张图,模型直接吐出可渲染的矢量代码?
然而,现有方法存在一个被严重低估的问题:分词方式不对。
大语言模型沿用NLP领域的BPE分词器来处理SVG代码。问题是,SVG的核心不是“文本代码”而是“几何坐标”。一个简单的坐标100会被BPE拆成“1”、“0”、“0”三个独立token——空间上紧密相关的数字在token空间中被彻底打散。这种割裂带来两个严重后果:
1. 坐标幻觉(Coordinate Hallucination):模型无法理解坐标之间的空间关系,频繁产生几何上不合理的输出。
2. token冗余爆炸:一个简单图标可能膨胀到数百个token,严重拖慢训练和推理效率。
一边是自然语言token的高信息密度(一个语义词通常只需1-2个token),另一边是SVG代码中大量低信息密度的坐标token——这种表征的不匹配,才是SVG生成质量的真正瓶颈。
既然根源在token设计,能否从根本上重新定义SVG的分词范式?
HiVG给出了肯定的回答。
技术方案:层次化分词,让每个token都「有意义」
核心思想:从字符碎片到可执行几何单元
HiVG的核心洞察简单而有力:SVG不是普通文本,它是可执行的几何程序。分词器应该尊重这一本质。
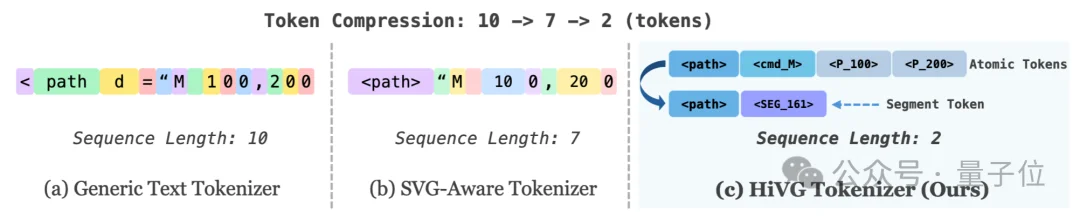
△ 三种Tokenizer分词策略对比图
如上图所示,对于同一段SVG代码
(a)通用文本分词器(LLM):暴力拆分为10个碎片token,坐标被打散
(b) SVG感知分词器(现有方法):识别了SVG元素,但坐标仍被逐个拆分,产生7个token
(c) HiVG分词器:将绘图命令和其关联坐标组合为一个可执行的矢量路径片段词元(segment token),仅需2个token
token压缩率:10→7→2,这就是层次化的力量。
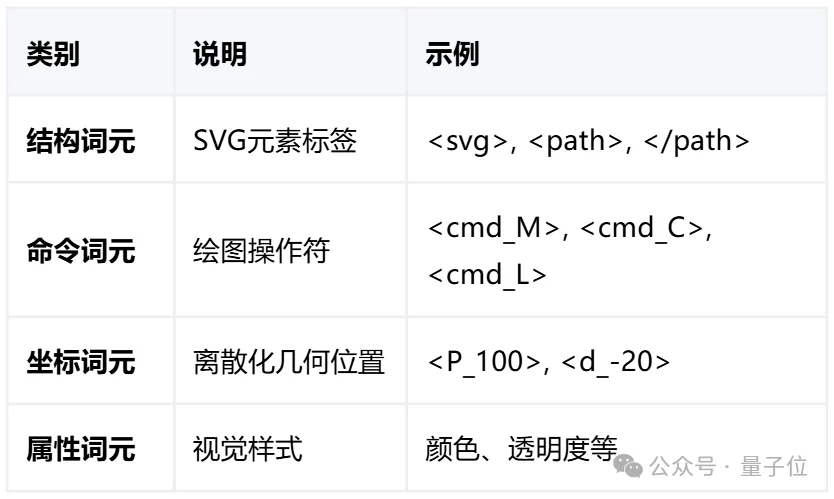
第一层:原子词元(Atomic Tokens)
HiVG首先将原始SVG字符串分解为四类不可再分的原子词元:
关键设计:路径参数采用相对坐标表示——每条路径的首个命令用绝对坐标定位,后续参数相对于前一个点偏移。这不仅降低了全局平移方差,还大幅提升重复几何模式的可发现性,为下一层压缩奠定基础。
第二层:路径片段词元(Segment Tokens)——真正的杀手锏
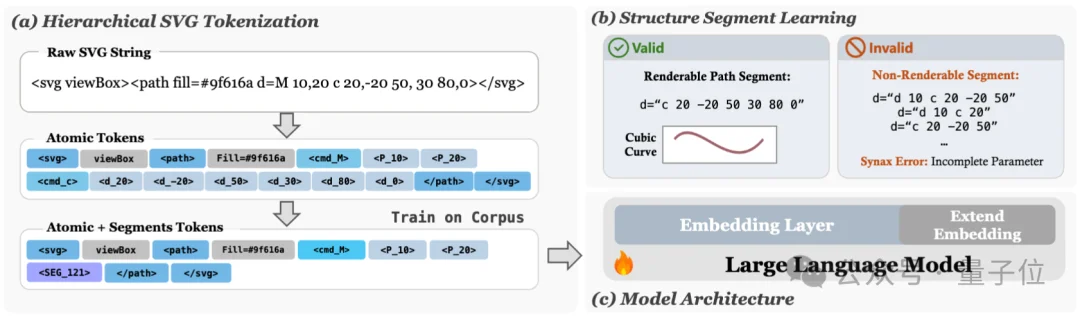
△ HiVG框架总览
这是HiVG最具创新性的设计。在原子token之上,HiVG将「绘图命令+其全部坐标参数」视为一个不可分割的矢量几何片段(segment):
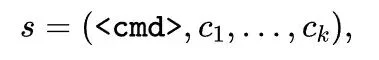
然后在大规模SVG语料上执行迭代配对合并(类似BPE的思想,但作用在段级别而非字符级别),将高频共现的相邻段合并为新的复合路径片段词元。
核心约束:合并只在段边界发生,且合并结果必须是语法有效的、可渲染的几何单元。这意味着学到的每个路径片段词元都对应一个真实可执行的SVG几何图元。
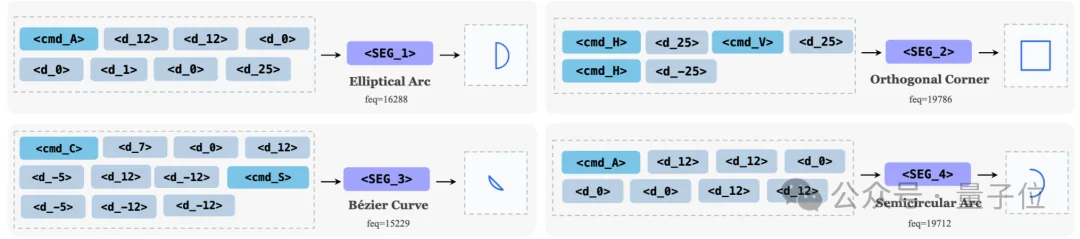
△ 学习到的路径片段词元示例
上图展示了实际学到的路径片段词元:椭圆弧、正交拐角、贝塞尔曲线、半圆弧——这些都是SVG设计中最常用的几何原语。每个token在语料中出现频率高达15000-20000次,证明它们确实捕捉到了可复用的几何结构。
压缩效果:相比原始SVG字符串,路径片段词元将序列长度压缩了62.7%-63.8%(2.68×-2.76×)。
HMN初始化:让坐标Token从一开始就懂「空间」
在预训练LLM中引入全新的SVG token,如何初始化它们的embedding?随机初始化会破坏预训练空间的分布;用全局均值初始化又丢失了token间的结构关系。
HiVG提出了层次化均值-噪声(HMN)初始化策略:
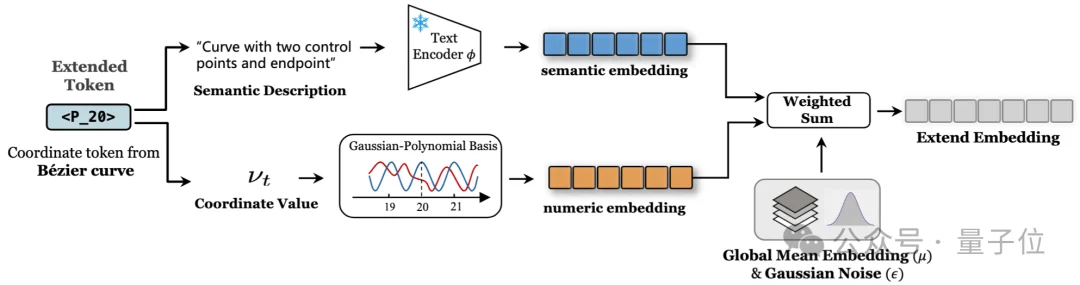
△ HMN初始化示意图
每个新token的embedding由四项组成:
et=λμμ+λnϵ+wsemΦ(desct)+wnumdt
- 全局均值+噪声(μ+ϵ):保持与预训练词表的分布对齐同时增加Token间区分度
- 语义先验(Φ(desct)):利用冻结模型权重编码token的文本描述
- 数值编码(dt):通过高斯-多项式基函数将归一化坐标值映射到embedding空间
将归一化坐标通过高斯径向基(RBF)与多项式特征映射,并经随机投影得到embedding,使相近坐标在表示空间中保持邻近,从而赋予模型初始的空间感知能力。
实验结果:3B参数,多项指标超越8B模型
定量对比
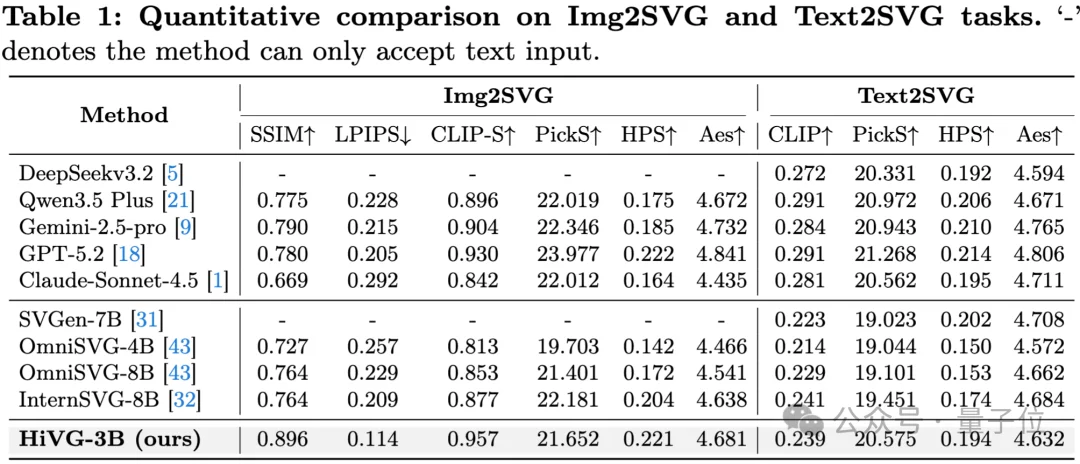
在Image-to-SVG任务上,HiVG-3B取得了0.896 SSIM(vs. Gemini-2.5-pro的0.790)和0.114 LPIPS(vs. GPT-5.2的0.205),CLIP-S得分0.957同样显著领先。
值得注意的是,HiVG仅有3B参数,却在多项关键指标上超越了GPT-5.2、Claude-4.5-Sonnet、Gemini-2.5-pro等闭源模型,以及OmniSVG-8B、InternSVG-8B等8B级开源模型。
视觉对比

△ Image-to-SVG生成方法比较

△ HiVG Image-to-SVG生成结果

△ Text-to-SVG生成方法比较
从视觉对比可以看到,面对复杂布局(如Mastercard logo、含文字的日历图标),其他方法频繁出现形状残缺、文字错乱、颜色偏差等问题,而HiVG生成的SVG在结构一致性和细节保真度上表现更优。
特别值得一提的是,HiVG在生成包含字体(glyph)的SVG时表现出色——这是此前方法极少能做好的能力。
人类评测:专业设计师投票
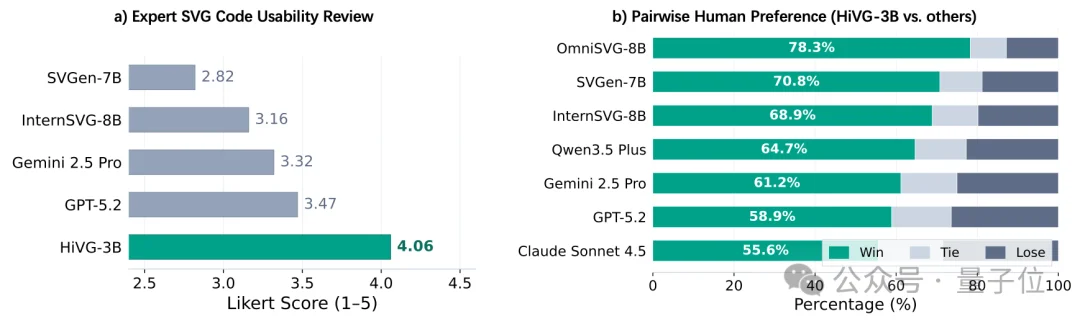
△ 人类评测结果
研究团队招募了8位专业SVG从业者进行双盲评测:
可用性评分:HiVG以4.06分(满分5分)位居第一
配对偏好:HiVG在与所有对手的头对头比较中获胜率达58.9%-70.8%
此外,在Adobe Illustrator中的实际编辑测试中,HiVG生成的SVG在语义分层、可编辑性、冗余控制和整体可用性四个维度上均获得最高分。这意味着HiVG不仅“看着好”,在实际设计工作流中也更实用。
Token效率:用更少的token达到更好的效果
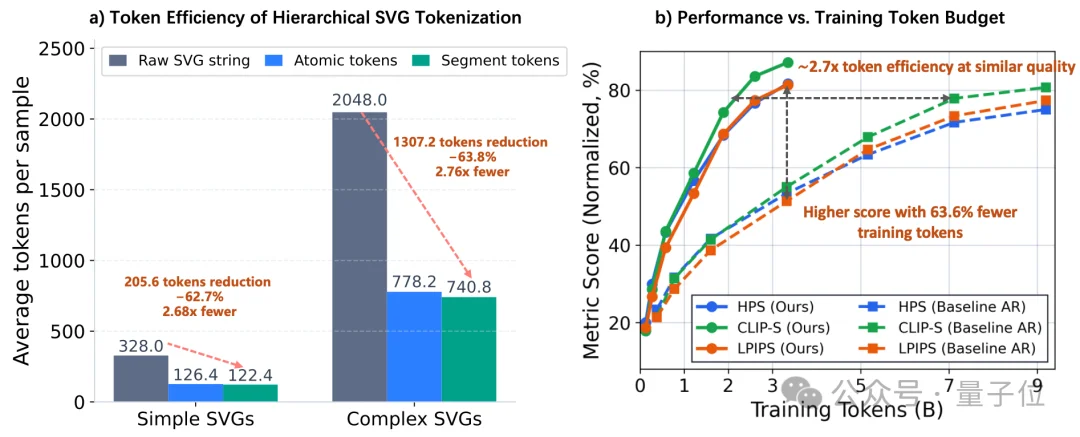
△ Token压缩效率vs.训练使用Token预算
HiVG将SVG序列压缩了62.7%-63.8%,用约2.7×更少的训练token即可达到与基线方法相当的生成质量。这意味着更快的训练速度、更低的推理延迟、更少的计算资源消耗。
项目价值
HiVG的意义,不止于SVG生成任务本身。它传递了一个重要信号:
在结构化生成任务中,「Token设计」的价值可能被严重低估了。
当前AI社区的主流思路,是不断扩大模型规模、堆叠数据。但HiVG以3B参数在多项指标上超越更大模型的事实表明:当数据天然具备结构时,让表征与结构对齐,往往比单纯增加参数更有效。
这一思路有望推广到CAD生成、3D Mesh生成、机器人动作序列建模等所有涉及「结构化序列」的领域。
同时,HiVG在SVG代码可用性上的领先表明,该技术具备直接落地设计工具链的潜力——可以想象,未来设计师只需输入一句描述,就能获得一个结构清晰、可直接编辑的矢量图标。
arXiv:
https://arxiv.org/pdf/2604.05072
主页:
https://hy-hivg.github.io/
代码:
https://github.com/ximinng/HiVG
文章来自于微信公众号 "量子位",作者 "量子位"
