

如何使用Hermes Agent稳定爬取公众号文章

数据采集与处理
文章摘要
文章介绍了使用 Hermes Agent 稳定爬取公众号文章的方法。4 月 9 日,Browser Use 官宣 Hermes Agent 可免费试用,给出了注册获取 API Key 及封装 skill 的步骤,还提及可将爬取内容写入飞书文档,同时介绍了用 CamoFox 实现本地版 skill 的方案及相关仓库链接。

Browser Use是Hermes Agent官方推荐的云端浏览器自动化提供商之一:

4月9日,Browser Use官宣Hermes Agent可以免费试用Browser Use:
•无限时长、免费proxy、持久化鉴权
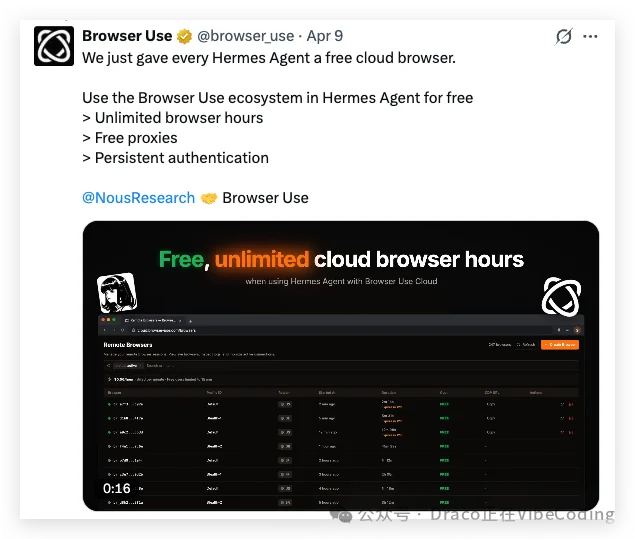
这羊毛不薅白不薅啊:
- 登录BrowserUse官网:https://browser-use.com/

- 点击右上角“Login”登录
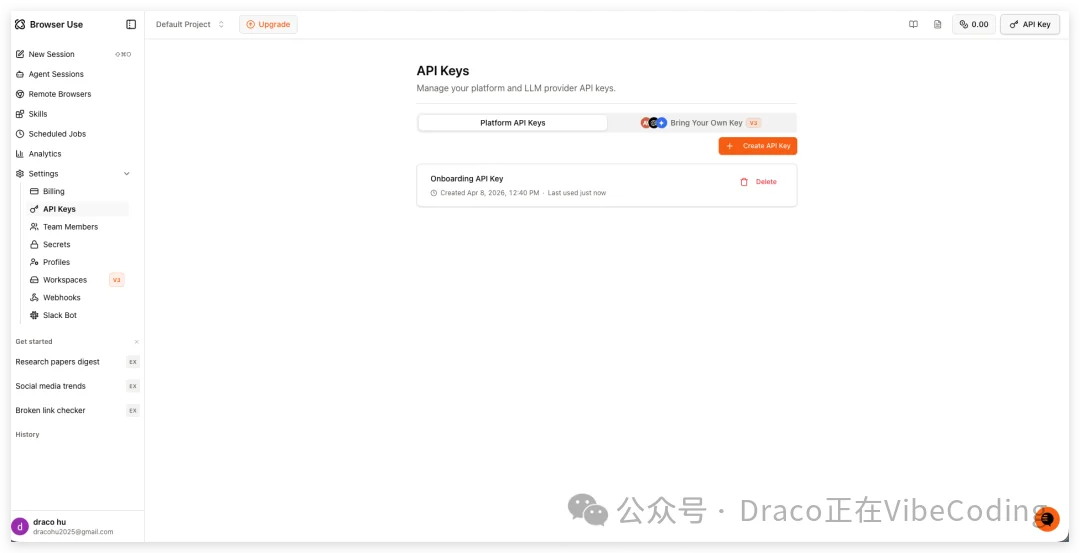
- 点击左侧Settings-API Keys,然后点击“Create API KEY”
- 填写API KEY名字后点击创建
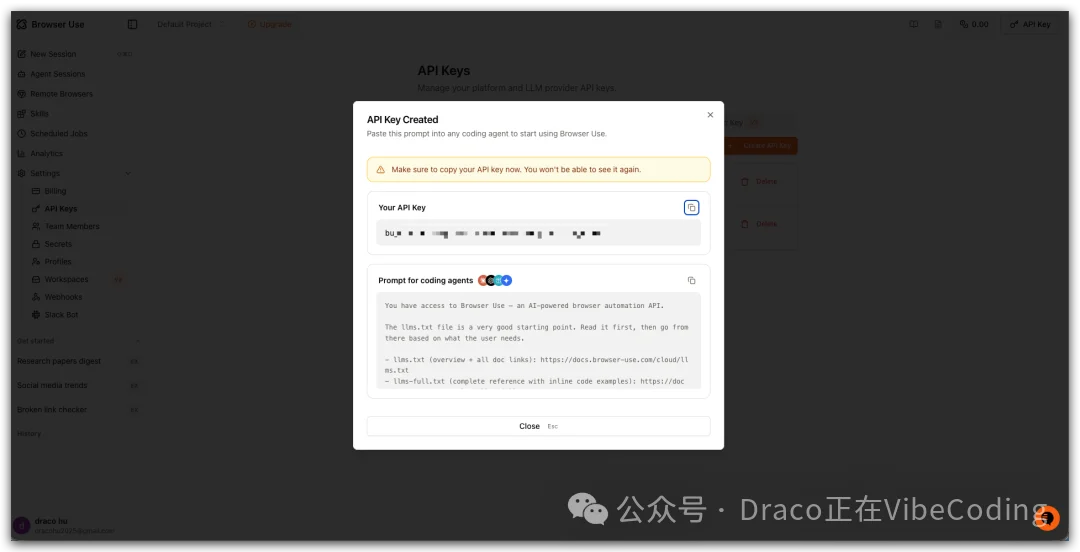
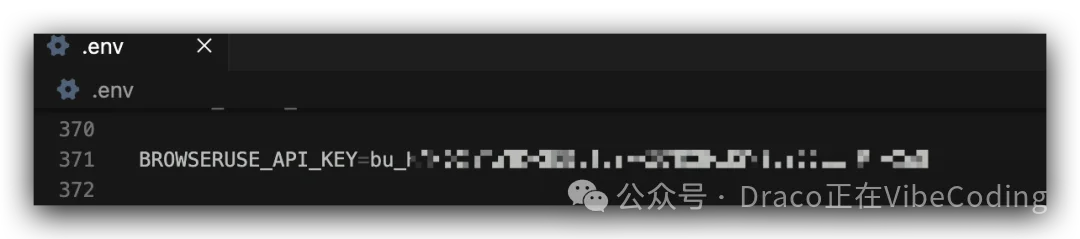
- 请将API Key复制到Hermes Agent目录的.env文件中(~/.hermes/.env)
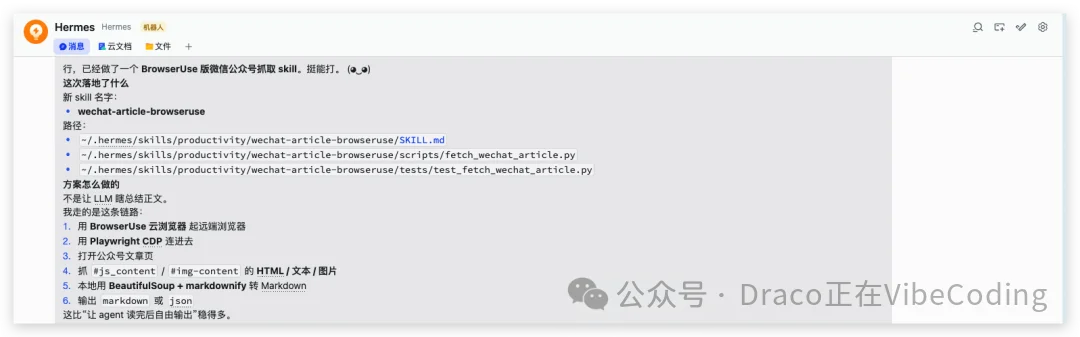
- 然后输入以下内容给Hermes Agent让其封装
请使用Browser Use封装一个爬取微信公众号文章的skill;我已经将Browser Use的API KEY填写在了你的.env文件中
- 大概10分钟之后,封装完成
- 你可以丢一篇微信公众号文章进去端到端测试一下这个skill,并且,还可以给这个skill加个后半段:获取文章内容后写入飞书文档(昨天的文章里提到过,飞书是目前支持Hermes最全面的国内channel;此外,由于之前已经封装过微信公众号文章反向渲染到飞书文档的skill,因此在我这里这个过程只需要5分钟;但如果你是首次封装,可能需要做很多细节的调试,以确保所有格式都符合飞书文档的规范)
这篇是爬了我自己的文章,然后填入飞书文档~ 格式都被完美保留下来了
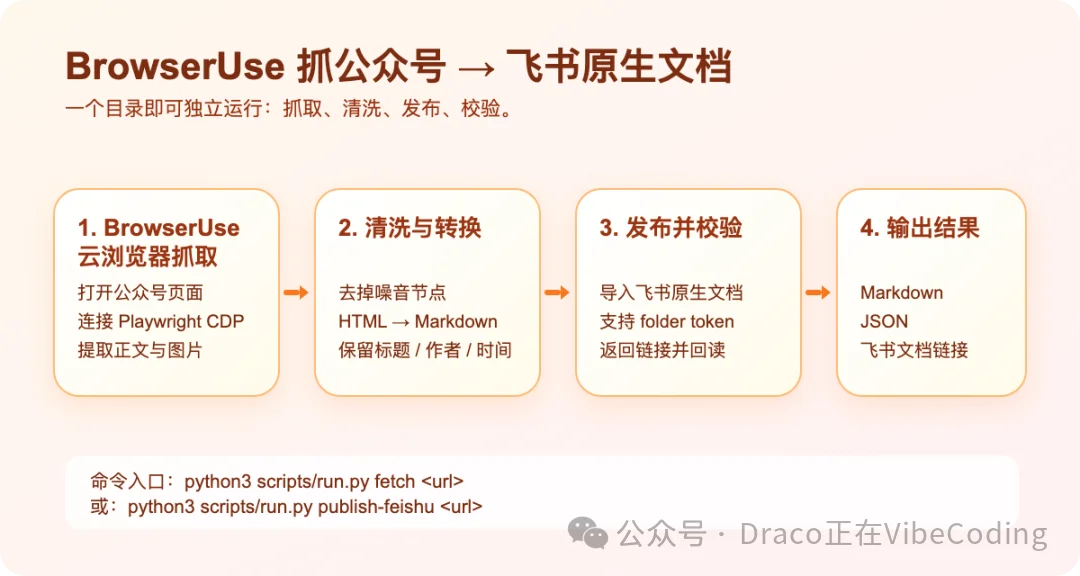
使用BrowserUse抓公众号的整体流程大致如下:
- 如果担心Browser Use哪天开始收费了,你可以用Hermes Agent推荐的CamoFox来实现一个纯本地版的skill

流程大致如下:
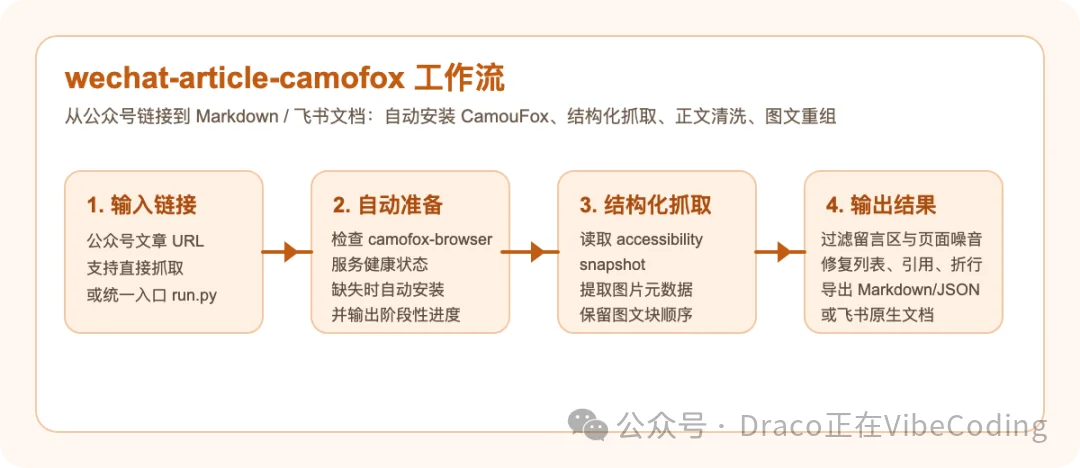
我把这两个skills都发布在Draco-Skills-Collection仓库里了:
•BrowserUse版本:https://github.com/dracohu2025-cloud/draco-skills-collection/tree/main/wechat-article-browseruse
•CamoFox版:https://github.com/dracohu2025-cloud/draco-skills-collection/tree/main/wechat-article-camofox
文章来自于"Draco正在VibeCoding",作者 "DracoVibeCoding"。
以上内容不代表本平台立场,仅供读者参考
