
MiniMax开源M2.7模型:程序员福音?部署教程与全面测试

MiniMax正式开源3月份发布的旗舰模型M2.7,性能直追Claude Opus,并适配华为昇腾等国产AI芯片。
消息一出,国内外开源社区直接炸锅。Hugging Face上122GB的文件被全球开发者疯狂下载,各大LLaMA版块被各种测卡贴、跑分图和部署教程刷屏。
我们来看看,229B参数到底有多能打?

跑分逼平Opus
作为旗舰模型,参数量早就不新鲜。但M2.7的硬指标,依然让人倒吸一口凉气。
M2.7总参数量高达230B,而且每次推理只激活10B。这意味着什么?它用极低的算力消耗,就撬动了极其庞大的知识库。这种低激活率让推理效率大大提升,降低了调用成本。
超长记忆:支持约20.4万tokens的上下文,相当于半年的系统报错日志。
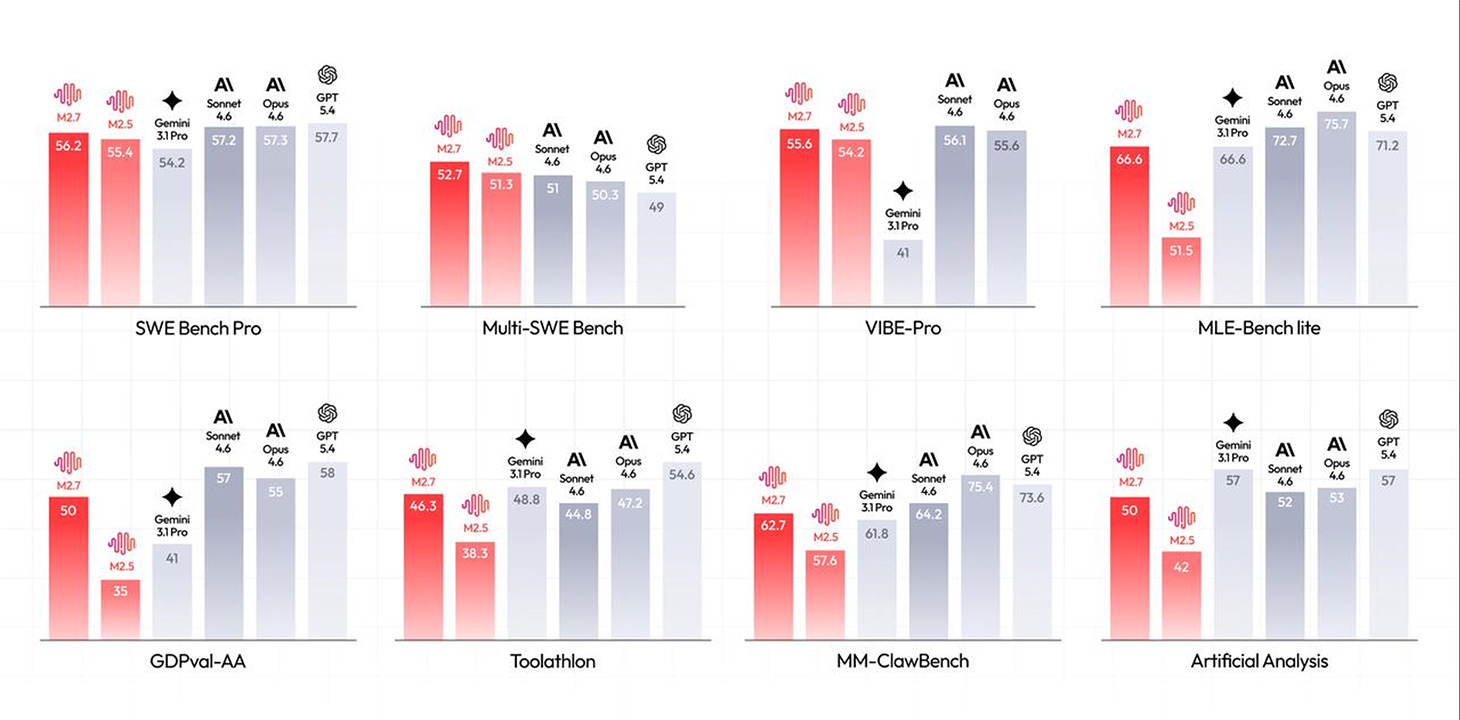
在SWE-Pro基准测试中,M2.7直接拿下56.22%的成绩。SWE-Pro是最考验代码能力的测试,它直接抓取开源项目中的真实GitHub问题,要求模型定位问题、修改代码并进行测试。56.22%的胜率,逼近了Claude 3 Opus,在多语言编程中的表现尤为强悍。
GDPval-AA ELO评分中,M2.7的数值位1495,这是衡量综合智能水平的测试,M2.7稳坐开源模型头把交椅。在机器学习竞赛的MLE Bench Lite测试中,它拿到了66.6%的奖牌率,仅次于少数顶级闭源模型。在多代理任务处理的PinchBench中,它获得了86.2%的高分,与Claude Opus的86.4%处于同一水平线。
与其他国内大厂(如阿里Qwen系列)的同级别模型相比,M2.7在复杂Agent多代理协作、长时序任务处理以及代码库级重构上遥遥领先。第三方评测机构Artificial Analysis的数据也印证了这一点:它在深度上下文分析上的优势明显,对复杂技能的遵守率高达97%。
不仅跑分漂亮,API定价也便宜。通过OpenRouter等平台接入,其输入成本约为0.30美元/百万tokens,输出成本约为1.20美元/百万tokens。

模型自我进化
“打铁还需自身硬”,M2.7最大的杀招,就是它独创的“自我进化”能力。
过去的大模型,更像是填鸭式教育,工程师喂什么数据,它就学什么。不仅耗时耗力,而且依赖高质量的人工标注。
M2.7打破了这个常规,根据MiniMax官方发布的技术细节,M2.7能够直接参与训练流程。它不仅能自主构建agent 测试台,还能自己去优化强化学习实验。在遇到复杂编程或工作流阻碍时,M2.7可以自主生成中间推理步骤,验证这些步骤的有效性,然后将其作为新的训练信号反哺给自身网络。内部测试显示,这套“左脚踩右脚上天”的玩法,让它的性能提升了30%。
这也带来了更强的场景适应力。面对数十个文件的前端加后端项目,M2.7能实现端到端的项目交付。它不只提供几行代码片段,而是能查阅系统运行日志,排查深处Bug,并帮你完成代码的安全扫描与底层重构。
在处理Excel数据透视、PPT编写、Word长文档多轮修改时,它的指令服从度惊人。用户连续提出了十几个修改要求,它依然能记住第一轮的上下文,不会改了东墙倒西墙。
得益于自我进化带来的逻辑韧性,M2.7在多代理协作和工具使用上也游刃有余。它可以调度一个负责搜索网页的Agent、一个负责运行Python代码的Agent以及一个负责操作本地文件的Agent,有条不紊地完成一项跨平台的自动化任务。
那么,普通人能使用吗?这就必须掏出我们的实操指南了。

本地部署与API指南
M2.7的参数量高达229B,RTX 4090大概率是带不动的。针对不同需求的开发者,我们准备了“穷游”和“富玩”两套方案。
方案一:API在线白嫖与接入
如果你只是想体验M2.7的代码生成能力,或者把它集成到自己的业务中,调用API是最具性价比的选择。
MiniMax官方开放平台(platform.minimaxi.com)已经上线了M2.7的接口,注册即可获取API Key。平台提供了M2.7和M2.7-highspeed两个版本,后者在保证质量的同时,推理速度可达100 TPS。
更爽的是,MiniMax在接口设计上兼容性极强。它支持OpenAI SDK和Anthropic SDK格式,如果你之前的项目是用的GPT-4或Claude 3作,你只需要替换Base URL和API Key,两行代码就能实现无缝替换。
如果你连代码都不想写,可以直接登录MiniMax Agent平台,这是一个可视化界面,开箱即用,直接体验M2.7的各种预设工作流。
方案二:本地部署
以下是在Linux环境下,通过llama.cpp实现CPU+GPU混合推理的完整实操记录。
首先,你需要一台运行Linux(推荐Ubuntu)的机器,拥有至少110-125GB的可用硬盘空间,以及125GB以上的系统内存。GPU方面,本次演示租用了一张NVIDIA H100 80GB。如果你的显存不够,模型会自动将多余的计算层卸载到CPU上,但这会大幅牺牲推理速度。
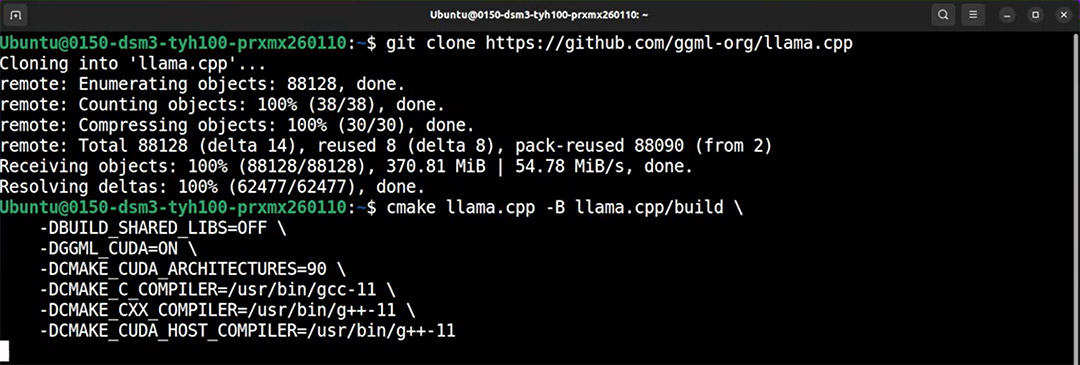
第一步:安装 llama.cpp
打开终端,首先拉取llama.cpp的源码并进行编译。这个工具是目前在单节点服务器上运行超大模型的最优解。
编译完成后,必须验证CUDA是否正常挂载。执行 ./llama --list-devices,如果终端成功打印出你的NVIDIA GPU型号,说明环境配置无误。
第二步:配置Hugging Face CLI
M2.7已经发布在Hugging Face仓库中。我们需要安装官方的命令行工具来加速下载。
在浏览器中打开Hugging Face的设置页面,创建一个read token,复制并粘贴回终端完成鉴权认证。
第三步:下载GGUF量化模型
这里我们强烈推荐使用开源社区大佬Bartowski制作的GGUF量化版本。考虑到硬件,我们选择IQ4_XS量化级别(约122GB大小),这能在损耗极小的情况下,最大程度压缩显存占用。
由于文件很大,这一步需要耐心。下载完成后,所有的.gguf文件都会在 ./minimax-m2.7-gguf 文件夹中。
第四步:启动OpenAI兼容服务器
退回到llama.cpp的根目录,我们要用一条指令唤醒模型。请根据你的实际硬件配置严格调整以下参数:
参数解析:
--n-gpu-layers 60:它决定了有多少层神经网络会被扔进GPU的显存里。在我们的H100测试机上,设置60层大约会吃掉70GB的VRAM。如果你的显存较小,请逐步降低这个数值(例如降到30-40),多余的层会让CPU去硬扛。
--ctx-size 16384:我们将上下文窗口限制在了16K,虽然M2.7原生支持20万上下文,但在本地推理时,超大上下文会瞬间吞掉大量内存,16K对于日常代码测试已经完全够用。
--threads 20:分配给CPU的物理线程数,请根据你的CPU核心数进行压榨。
敲下回车后,当屏幕上出现“Offloading 60 layers to GPU”,并在最后提示服务器已成功运行在 http://localhost:8001 时,恭喜你,部署成功。
在这套混合推理架构下,M2.7的输出速度大约维持在7-10 tokens/sec。虽然因为CPU的拖累算不上快,但对于一个229B参数的模型来说,这个可用度已经很可观。
环境搭好了,服务器跑起来了,我们来看看它的代码生成能力到底有没有那么神。

实测M2.7代码生成能力
我们给M2.7准备了三道测试题,这三个项目包括了系统架构、3D物理引擎、音视频交互。
案例一:操作系统
提示词设定:我们要求M2.7生成一个操作系统,必须包含5个独立的应用程序,并且具备更改桌面壁纸的能力。
实测表现:代码生成完毕后,我们点开index.html,M2.7给出了一个“RetroWave OS”的完整界面,左下角有开始菜单。
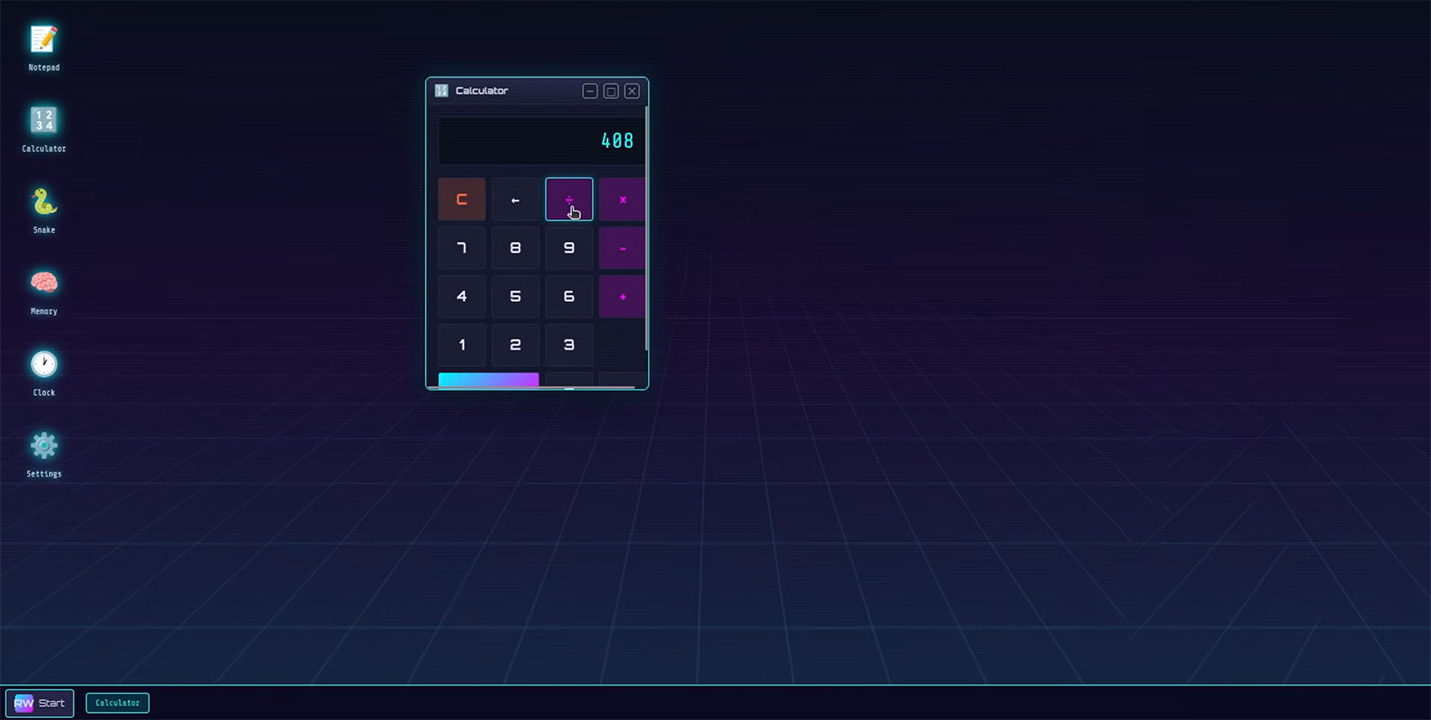
我们逐一测试了它生成的应用,记事本支持文本输入与保存;计算器能做运算,有除以零的错误提示;两款游戏分别是“贪吃蛇”和“记忆翻牌”,没有任何卡顿或逻辑死循环。
案例二:战舰世界游戏
前端页面大部分模型都能设计,调用C++库处理3D物理反馈,才是硬仗。
提示词设定:我们要求M2.7使用C++和raylib图形库,创建一个3D战舰世界模拟器。必须包含玩家控制的舰船、敌方AI舰船、真实的物理反馈、水面渲染效果以及伤害计算系统。
实测表现::M2.7迅速给出了几百行C++源码。编译运行后,程序确实跑通了,没有任何语法错误。但是,玩家的舰船竟然沉在水面以下,而且键盘操作时,船体的转向没有任何物理惯性反馈。我们把视觉Bug和操作体验反馈给了M2.7,几秒钟后,第二版代码生成。
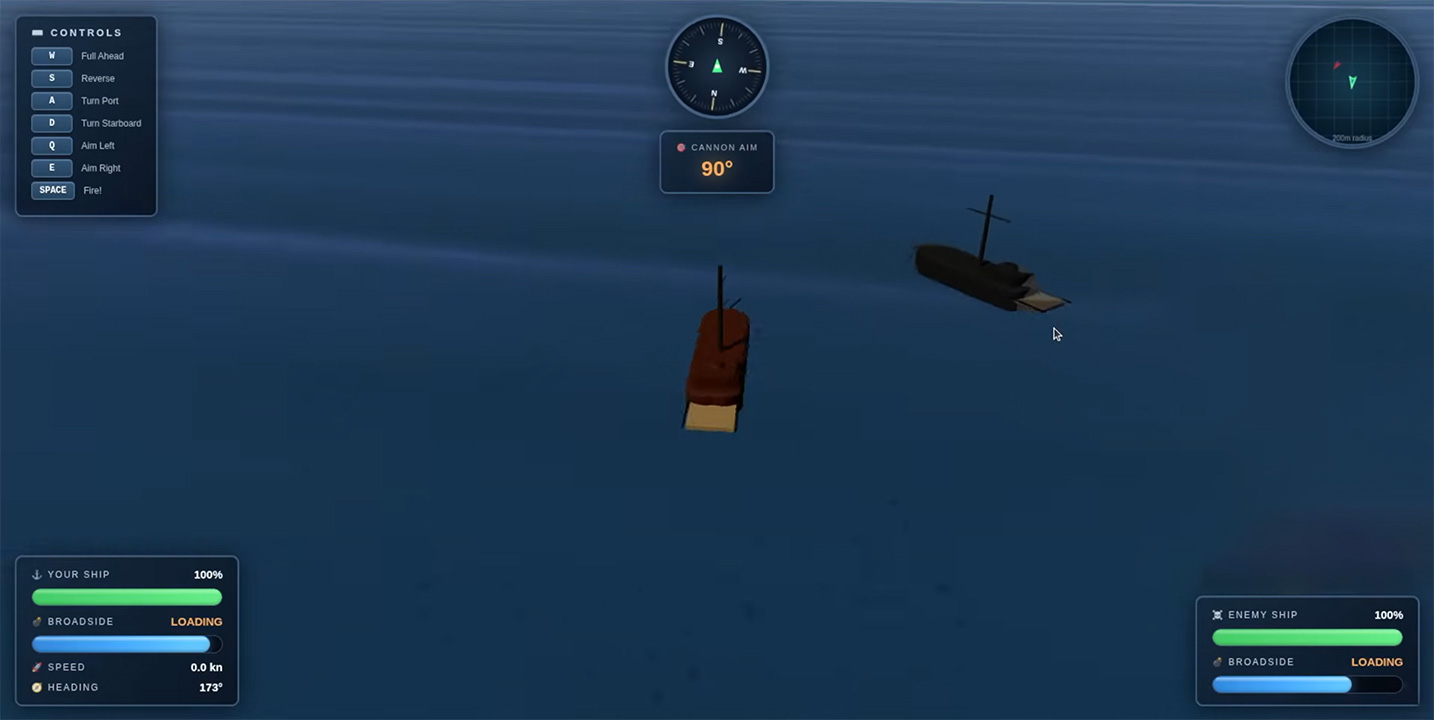
改进后的版本修正了Y轴的浮力坐标,舰船随波浪浮在水面上,而且M2.7还在屏幕右上角增加了一个指南针和小地图。更夸张的是,当玩家舰船的血量归零时,它生成了一段爆炸动画和Game Over提示。
案例三:虚拟架子鼓
第三个项目,我们将测试它的实时交互与音频同步。
测试过程:要求生成一个虚拟架子鼓模拟器,用户可以通过键盘按键实时弹奏,还必须包含自动播放功能,要内置4首不同风格的预设鼓轨,允许用户随时切换。
实测表现:页面加载后,一套架子鼓UI呈现在屏幕中央。你按下对应的键盘字母时,会触发无延迟的鼓声采样,对应的鼓面还有视觉光效震动。

当我们点击自动播放时,预设的摇滚鼓点节拍,底鼓、军鼓和踩镲配合得严丝合缝。播放过程中,点击切换到爵士风格,节奏立刻变成了慵懒的爵士切分音。(微信公众号:Tahou_2025)
关注塔猴公众号,扫码下载塔猴APP,查看更多干货

扫码加入官方社群

