

斯坦福2026 AI指数出炉:全球投资5810亿美元,中国工业机器人反超美国?

如果你经常关注科技圈,可能会感到信息过载。
一会儿是淘金热,一会儿是泡沫,一会儿要抢走你的工作……每天,无数的标题和观点像潮水一样涌来,拍打着我们焦虑和兴奋的神经,我们分不清,这到底是最好的时代,还是最坏时代的开端。
就在今天凌晨,一份423页的报告,这个星球上关于AI最全面、最客观的报告发布。
一年一度的斯坦福大学《2026年人工智能指数》,它不贩卖焦虑,也不描绘天堂,它只告诉这个行业的底牌。
钱!

报告指出,2025年全球企业在AI领域的总投资,达到了5810亿美元。是的,你没看错,5810亿,还是美元
拆开来看:
- 私人投资,3447亿美元,增速127.5%。
- 生成式AI,最卷的赛道,投资增速超过200%。
- 十亿美元级别的融资事件,较去年翻了一倍。
全世界的钱仿佛都找到了同一个出口。但是,这场泼天的富贵,到底泼向了谁?这可能是这份报告里,最惊心动魄的故事。

中美擂台赛,谁才是真功夫?
在过去几年,中美AI实力的讨论从未停止。有人说我们望尘莫及,有人说我们早已并驾齐驱。而斯坦福今年的报告客观的支出,实力基本抹平。
这场AI模型竞赛中,中美两国在顶尖模型性能方面几乎不分伯仲。这可不是一句空话,报告引述了全球模型基准排名平台Arena的数据。
2023年初,OpenAI一家独大,ChatGPT的光芒掩盖了一切。但到2024年,随着谷歌和Anthropic的回过神来,差距开始肉眼可见地缩小。真正的转折点,发生在2025年2月。一家来自中国的公司DeepSeek,他们开发的模型R1,一度与美国最顶尖的模型并驾齐驱,站上了同一个山顶。
那是一个标志性的时刻。它意味着,在模型能力这个最核心的战场上,单点突破已经不再是神话。截至2026年3月,虽然Anthropic的模型暂时领先,但报告指出,美国模型对中国顶尖模型的领先优势,仅剩2.7%。
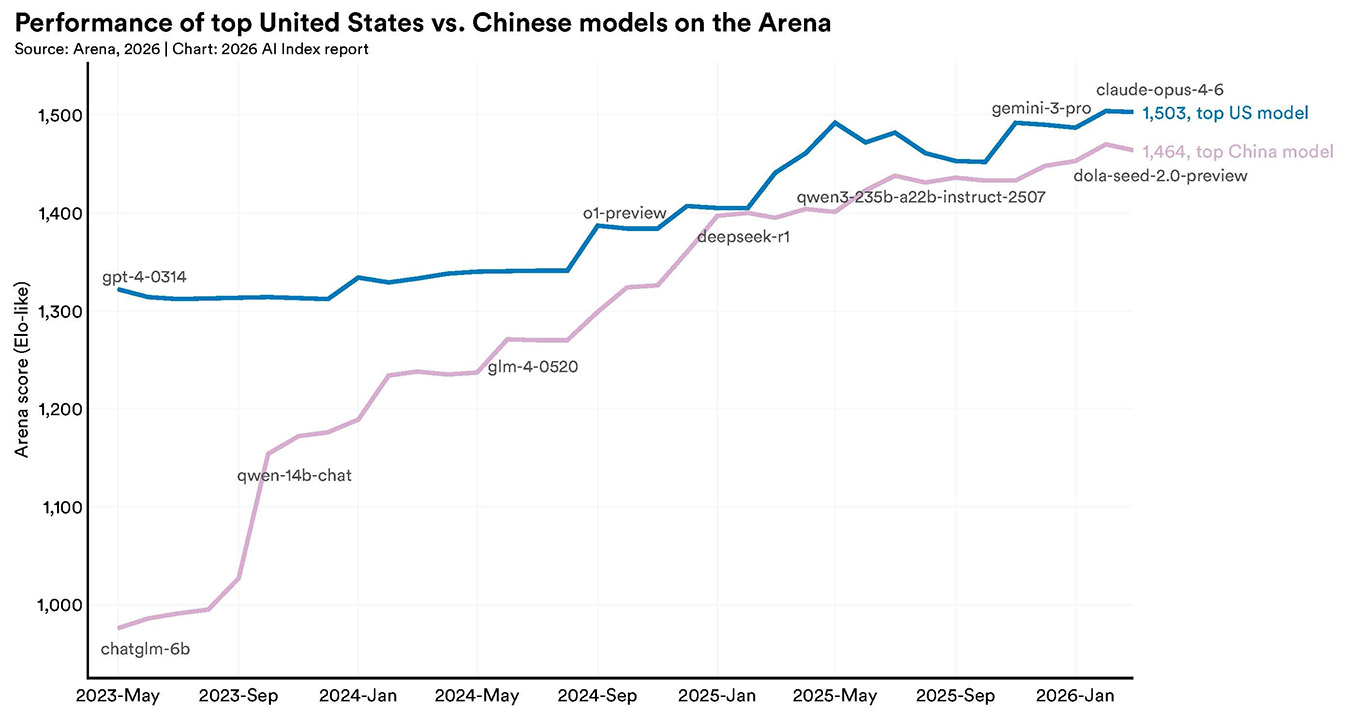
美国顶级模型VS中国顶级模型
这是一个什么概念?这意味着在最顶尖高手过招的层面,大家打出的拳风已经差不多了。这场比赛,已经从百米冲刺,变成了一场漫长的铁人三项。性能打平,只是第一关,真正的较量,早已蔓延到了水面之下。

美国的钱和算力
我们必须承认,美国的两套拳法,依然威力惊人。
第一拳:砸钱。
报告显示,到2025年,美国AI领域的风险投资将达到2859亿美元。中国的数字是多少?124亿美元。
是的,23倍。这泼天的富贵,确实没怎么下到东边。美国在AI创业公司的融资数量上,也是排名第二国家的10倍以上。从资金和创业活跃度来看,美国是最疯狂的淘金场。
当然,报告补充了一句:只看私人投资数据,可能会低估中国在AI领域的总支出。这句微妙的但书,为后面的故事埋下了伏承。
第二拳:算力。
如果说钱是内功心法,那算力就是武学招式。在这方面,美国的优势甚至可以说是碾压性的。报告统计,美国拥有约5427个数据中心,是其他任何国家的10倍以上。
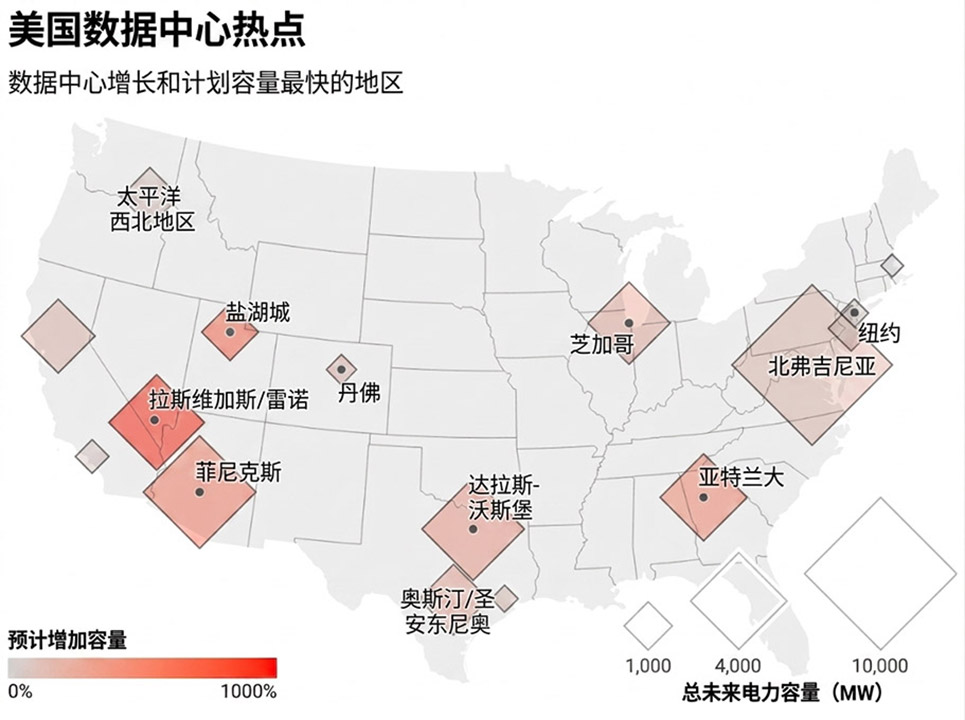
这些数据中心,就是AI时代的兵工厂,日夜不停地为大模型的进化提供着燃料。在可见的未来里,这依然是美国最坚固的阵地。

中国在你看不到的地方,弯道超车
面对美国的拳法,中国更像是一场教科书级别的“非对称作战”。你打你的,我打我的。
第一招:学术包围。
当全球目光都聚焦在那些模型发布会上时,中国在科研领域,已经悄悄完成了布局。报告显示,在AI研究论文发表数量和专利数量上,中国均领先全球。我们授予的AI专利数,占到了世界总数的74.24%。
这就像下棋,对手在抢占中原的战略高地,而我们则默默地把棋子布满了整个棋盘的边缘。短期内可能看不到杀伤力,但从长远看,这决定了整个行业厚度。
第二招:工业机器人。
这可能是整个故事里,最具有戏剧性的一幕。当美国投资人还在讨论大模型要颠覆好莱坞的时候,中国的工厂里,机器人已经装满了。
报告的数据显示:
- 中国占全球工业机器人装机量的份额,已经达到了54%。
- 新安装的工业机器人数量,中国的企业以295项排名第一,远超日本、美国、韩国。
- 更直接的对比,中国的安装量是美国的7倍。

这是一个极其重要的信号。
我们可以做一个对比。就像当年的智能手机革命,美国用iOS定义了软件;而中国,凭借强大的制造业和供应链,把硬件本身做到了极致。
今天在AI领域,似乎正在发生类似的故事。美国在定义AI最聪明的大脑,而中国,正在为AI装上最强大的“手和脚”。当AI的能力需要从云端走向现实世界,从虚拟走向物理时,谁的优势会更大?
这个问题,报告没有回答。但它把一个全新的、充满想象空间的局面,摆在了所有人面前。

谁在买单?
从中美对抗中抽离出来,报告为我们揭示了这场狂欢背后的代价。速度的提升并非没有代价,而账单,已经悄悄寄到了我们每一个人的手上。
第一笔账:环境成本。
AI的智能,是用巨大的能源堆出来的。
- 如今,全球AI数据中心的耗电量,足以满足整个纽约州高峰时期的用电需求。
- 运行OpenAI的GPT-4o一年,所消耗的水量,就可能超过1200万人的饮用水需求。
每一次看似轻巧的对话和生成,背后都是数据中心里呼啸的风扇和奔流的冷却水。AI时代的狂欢,地球正在默默买单。
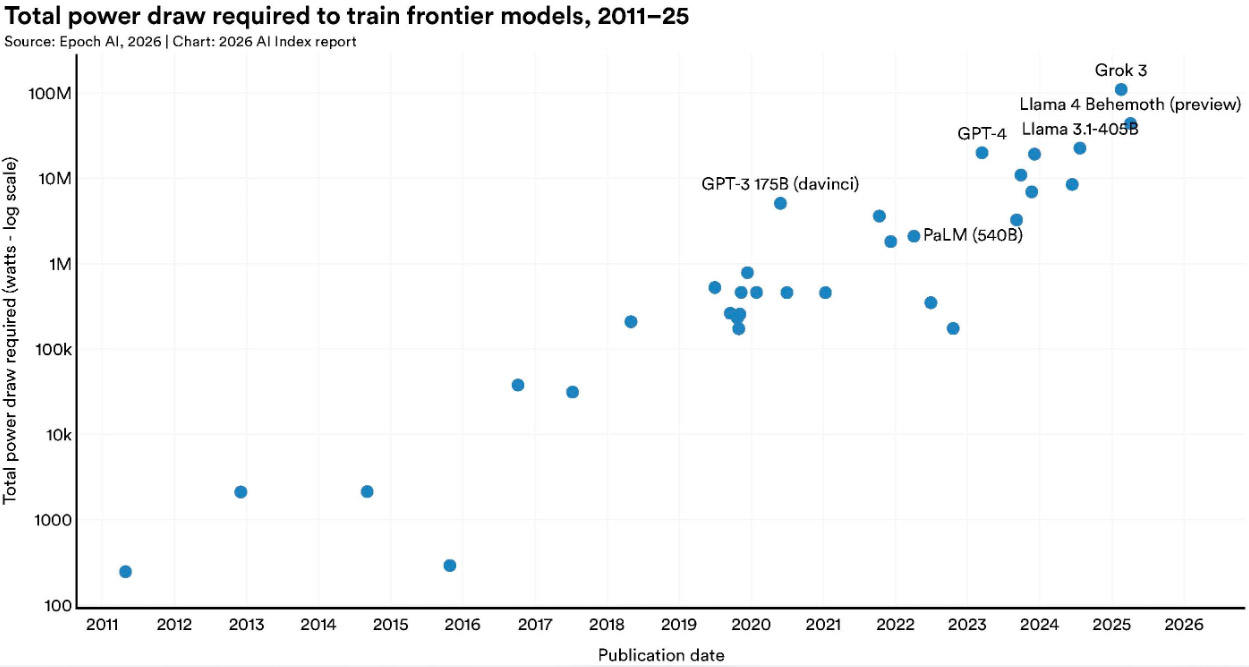
据估,Grok 4的训练排放量达到了72816吨,相当于17000辆汽车一年的温室气体排放量
第二笔账:透明度成本。
一个更令人不安的趋势是,AI模型越来越强,但它们的“心事”,也越来越难猜了。
报告指出,随着竞争加剧,OpenAI、Anthropic和谷歌这些顶尖的门派,开始纷纷闭门练功。他们不再公开训练代码、参数数量,数据集的大小。
整个AI世界,正在变得越来越“黑箱”。报告里显示:基础模型的透明度指数,在短暂上升后,从2024年的58,暴跌回了2025年的40。
我们创造出一个聪明的“大脑”,但却不清楚它在想什么,它是如何思考的。这种未知,可能比它不够聪明,更让人感到寒意。
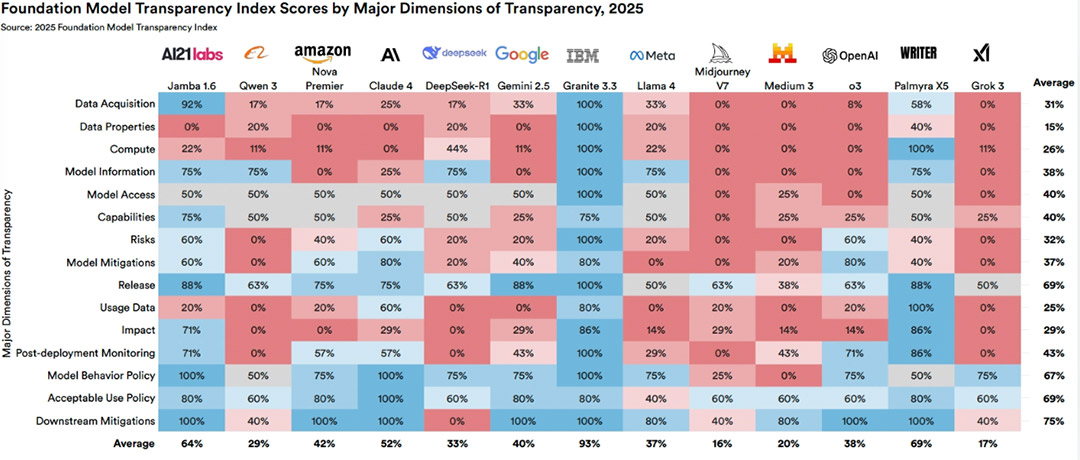

进步,可能全是假象?
如果说环境和透明度的代价,还在可预见的范围内。那么报告接下来的发现,则是对整个行业根基的拷问。它提出了一个问题:我们用来衡量AI进步的尺子,本身可能就是歪的。
第一重反转:测试基准,一戳就破。
我们怎么知道一个模型比另一个模型更聪明?靠的是各种基准测试,比如MMLU、SWE-bench。这就像AI的高考,
但一个被用于测试模型数学能力的基准,其本身的错误率,就高达42%。
高考的试卷有近一半是错的,我们还用来给AI打分,这简直是个笑话。
更离谱的是,报告还指出一个潜规则:很多模型,会直接用基准测试的数据来进行训练。这就好比一个高考生,在考试前拿到了原版试卷和答案,然后背了下来。他考出的高分,到底有多少是真本事,又有多少是开卷考试?
既是裁判,又是运动员,这波操作属实玩明白了。
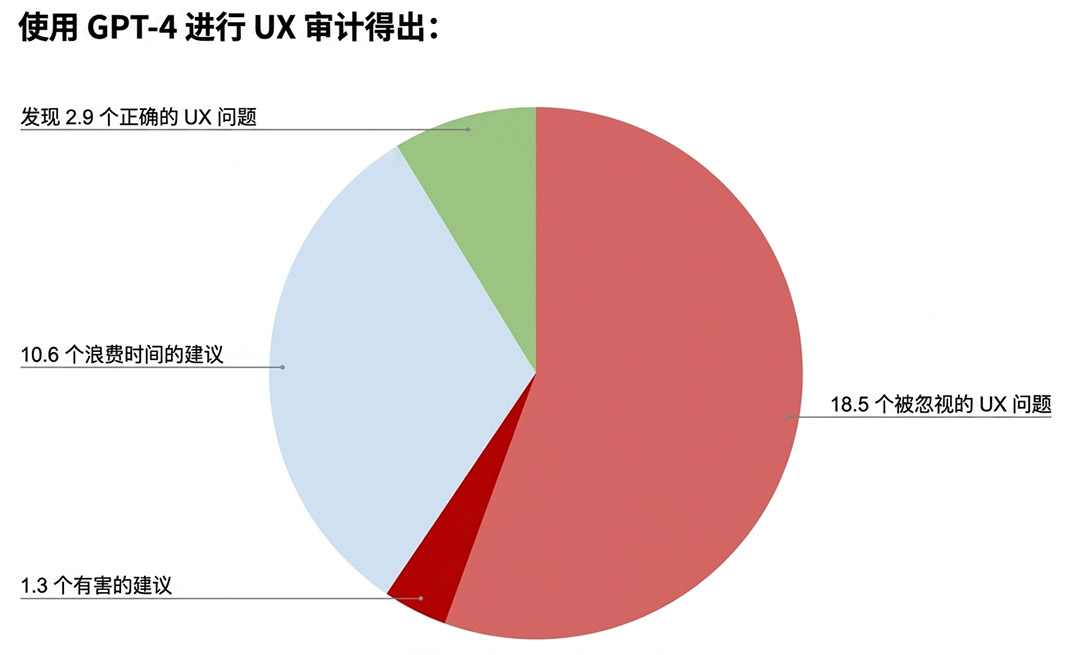
第二重反转:幻觉率,集体翻车。
如果说基准测试的漏洞还能修复,那么AI的幻觉问题,则像是无解。所谓幻觉,就是AI一本正经地胡说八道。
报告引入了一项新的准确率基准测试,结果所有顶尖模型都翻车了:
- GPT-4o,特定场景下的准确率,从98.2%下跌到64.4%。
- DeepSeek R1,从90%下跌到14.4%。
那些看起来无所不能的AI,面对它不熟悉或者被巧妙设计的场景时,胡说八道的概率高得吓人。

众生相,我们何去何从
最终,报告的视角从宏大的竞争和数据,拉回到了每一个普通人身上。在这场近乎失控的狂欢中,我们的生活,正在被悄无声息地改变。
第一幕:打工人的饭碗,真的悬了。
AI对就业的影响,不是“狼来了”,狼已经悄悄进了村。
自2022年以来,22至25岁的软件开发人员,就业率下降了近20%。这还只是开始,麦肯锡的调查显示,三分之一的企业预计,AI将在未来一年内,帮助他们缩减员工规模。客户服务、软件工程赫然在列。
第二幕:民众的情绪,一半火焰,一半海水。
面对AI的快速发展,世界各地的人们,情绪都极其复。
报告的调查显示:59%的人认为AI带来的好处大于弊端,但同时,有52%的人表示AI让他们感到紧张。73%的专家认为AI将对人们的工作方式产生积极影响,但只有23%的美国公众认同这一观点。
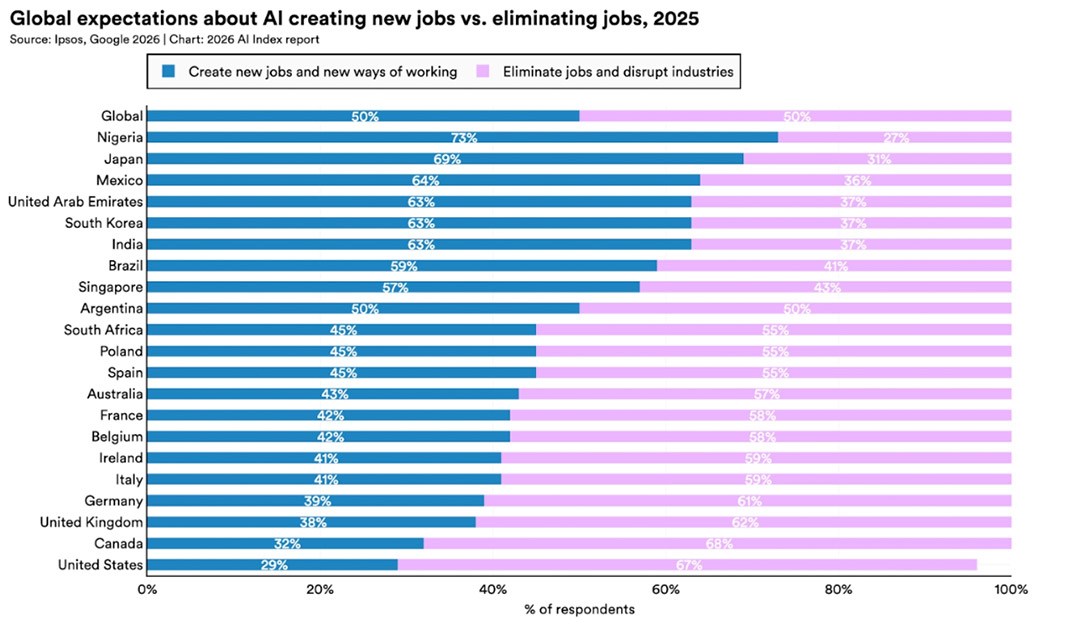
59%的人认为AI好处大于弊端
第三幕:政府的缰绳,追不上的野马。
面对AI,世界各国的政府,都在拼命地想要拉住缰绳。
报告里的一张折线图:从2016年到2025年,美国各州通过的与AI相关的法案数量,那条线几乎是垂直向上拉升的,在2025年达到了150项的峰值。
全世界的立法者都狂奔,试图为AI建立护栏,防止不法分子钻新时代的空子。
但所有人都清楚,AI技术迭代的速度,显然比任何一项法案的起草和通过速度,都要快得多。(微信公众号:Tahou_2025)
关注塔猴公众号,扫码下载塔猴APP,查看更多干货
关注塔猴公众号,回复“1”加入专属社群 扫码下载塔猴APP,查看更多干货

