
硬刚Gemini!京东开源了个“懂物理”的AI修图师JoyAI-Image-Edit
就在这几天,京东悄悄在开源社区扔了个大招:发布了一款叫 JoyAI-Image-Edit 的一体化图像模型。这个名字听起来挺长,但它懂点物理和几何学,让它在改图的时候,能真正理解真实世界里的空间关系。
从公开的跑分成绩来看,这匹国产黑马冲得挺猛。在空间理解能力上,它直接追平了谷歌那个没开源的杀手锏 Gemini 2.5 Pro。甚至在空间编辑的精度上,还顺手反超了像Veo 3.1、Kling这些专门做视频的大模型。
京东突然掏出这么个“懂物理”的模型,到底打的什么算盘?咱们今天好好盘一盘这背后的技术门道,以及它到底能帮哪些人把钱给省了。


让AI转个杯子有多难?以前的模型都是“三维盲”
咱们先聊聊,为什么以前的AI一改图就容易翻车。
不管是你熟悉的Midjourney,还是市面上各种开源的生图模型,它们以前学画画,靠的是死记硬背。你给它看一万张猫的照片,它记住了猫的特征(语义理解),所以能画出一只很逼真的猫。
但问题出在编辑上。当你让它把照片里的猫换个姿势,或者把旁边的人挪开时,它就傻眼了。因为二维平面的照片里,没有告诉它猫有多胖、人离镜头有多远。AI缺乏对三维几何的理解,所以改出来的图经常出现比例失调、前后遮挡错误、光影满天飞的翻车现场。
说白了,以前的AI画画全凭感觉。
京东的 JoyAI-Image-Edit,相当于硬生生给AI报了个补习班,教它学几何。
为了治好这个“三维盲”,京东把空间编辑单独拎出来当成了核心。在这套模型里,你不光能让它换个背景、改个颜色,你甚至能对它下达带有具体数字的指令,比如“把这个沙发往左移动0.3米”、“把鞋子顺时针旋转45度”。
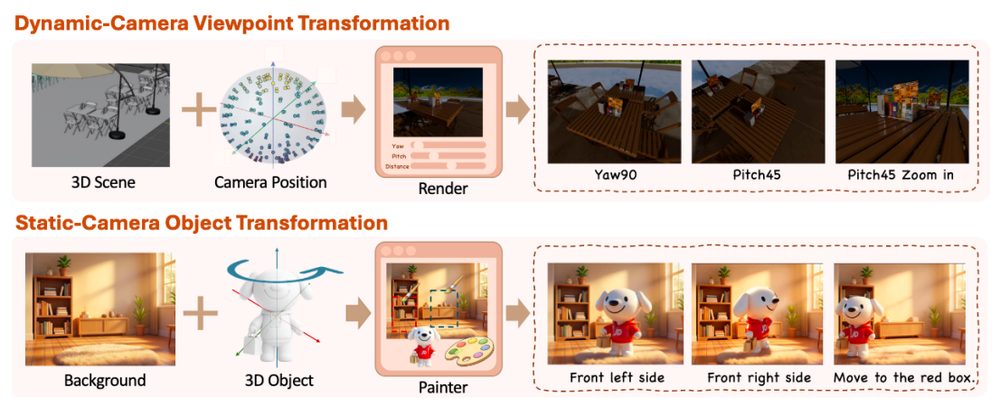

不管是面对阿里的 Qwen-Image-Edit-2511,还是风头正劲的 Flux2.Dev,JoyAI-Image-Edit 的表现都稳压一头。尤其是在空间编辑能力榜单(SpatialEdit-Bench)上,它的得分把所有图像编辑模型甩在身后,甚至比那些自带时间轴的视频模型还要准。
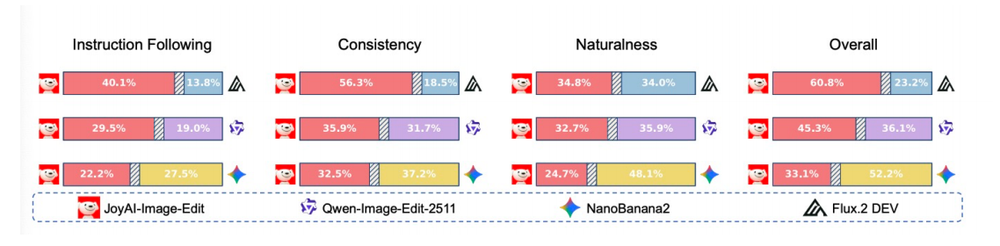
在249道评测集黑盒人工评测成绩:JoyAI-Image-Edit表现优于Qwen-Image-Edit-2511以及Flux2.Dev

怎么治好空间混乱症?脑子和手得分工明确
让AI听懂“转45度”这种话,听起来简单,做起来其实挺费劲。京东到底是怎么做到的?
我们可以把它的技术架构(MLLM+VAE+扩散模型MMDiT)翻译成大白话:就是让脑子、眼睛和手分工明确,搭配干活。
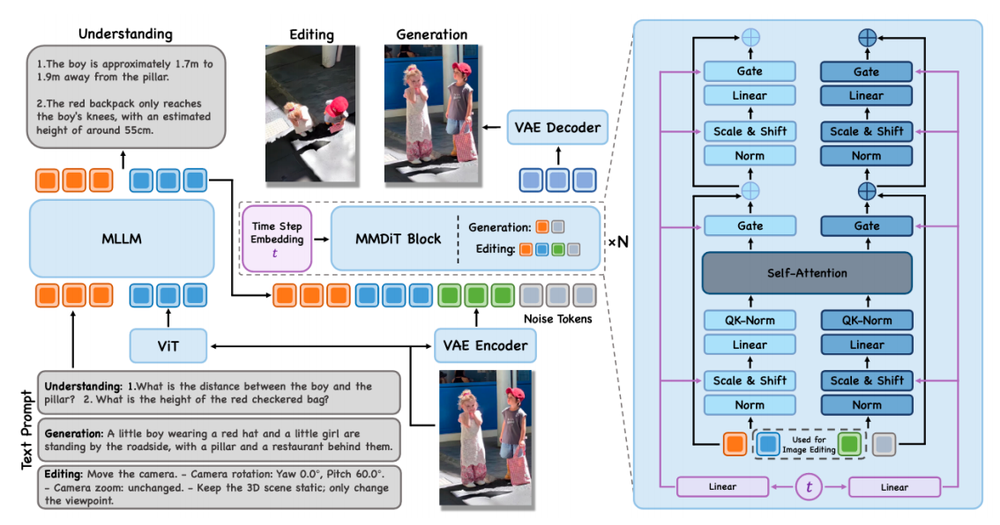
以前的模型,画图和想事情是混在一起的。JoyAI 则是让多模态大语言模型(MLLM)专门当“大脑”,负责搞懂空间关系。它先看懂这张图里谁在前面、谁在后面。弄明白之后,再把这些空间信息交给扩散模型这双“手”去具体画出来。画完之后,大脑再检查一遍,形成一个“理解—生成—再理解”的死循环,直到画面符合物理常识为止。
光有聪明的大脑还不行,你还得有教材。
为了教模型认清现实世界,京东砸出了一个包含300万规模的 OpenSpatial-3M 数据集。这里面装的不仅是图片,还有大量多视角的生成数据,以及精确记录了物体位置、姿态参数的空间编辑数据。
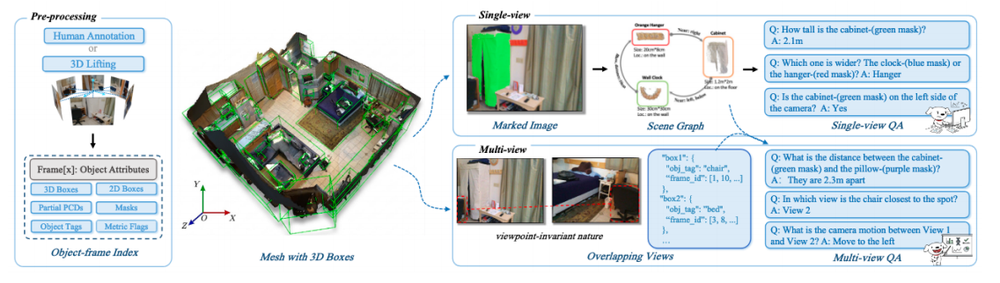
天天看着这些带有真实几何关系的数据训练,AI慢慢就学会了。

淘宝和京东商家的救星:不用花钱重拍商品图了
这东西做出来,最先爽的是谁?
毫无疑问,是每天被商品图折磨得死去活来的电商老板们。
如果你关注过这半年的电商圈,会发现大家其实都在用AI搞商品图(比如WeShop、触站这些AI模特工具)。以前拍个衣服,得请模特、租影棚、打灯光,一套下来几千块没了。现在用AI换背景、换模特,确实省了不少钱。
但商家的吐槽也很多:AI改图太不靠谱了。最后为了保证商品展示的严谨性,商家还是得咬咬牙,花钱把摄影师叫回来重新拍各个角度的特写。
JoyAI-Image-Edit 算是直接拿捏了这个痛点。
模型在把鞋子转过来的同时,鞋上的细节、鞋带的穿插全都稳稳当当,没有出现任何透视错乱。

对于卖家具、家电的老板来说更是个好消息。你想看看某家具放在大理石台面上和木头桌子上的不同效果,甚至想调整它在画面里的摆放角度。现在动动嘴皮子,输入几个角度参数,AI就能给你生成一套光影统一、比例正确的多角度素材。

这省下的可都是实打实的真金白银。

醉翁之意不在酒
如果以为京东费这么大劲开源个模型,只是为了帮平台上的商家省点修图费,那格局就小了。
咱们把目光从电商网页上挪开,看看物理世界。现在全科技圈都在搞具身智能,不管是特斯拉的Optimus,还是各种仓储物流机器人,大家都在面临同一个卡脖子的问题:数据不够。
机器人要在真实世界里干活,比如去货架上拿一瓶可乐,它需要海量的真实3D空间数据来训练它的视觉大脑。但是,让真机器人在真实的仓库里一遍遍去抓可乐、抓纸箱来收集数据,成本太高,周期太长了,李飞飞等一众顶尖学者都在为这个“数据饥渴”发愁。
JoyAI-Image-Edit 的空间理解能力,刚好成了破解这个难题的钥匙。
既然这个模型懂得真实世界的几何和光影规律,那它就能作为一个虚拟现实生成器。它可以根据指令,自动生成大量符合物理常识的高质量图像。比如生成一万张“不同光照、不同角度下,一个瓶子放在不同材质桌面上”的图片。
这些图片可以直接拿去喂给机器人,当作它们的训练数据。京东的机器人和配送车在虚拟世界里见识过了各种复杂的空间位置关系,到了真实的仓库里干活,自然就更利索了。
模型不仅能用来生产内容,还能反向给机器人提供看懂世界的经验。京东简直是一箭双雕。

京东死磕“搬砖送货”
回头看看这几个月的大模型战局。各家都在拼长文本、拼逻辑推理,甚至拼谁写的文案更有趣。
在大家都忙着秀智商的时候,京东的这套组合拳显得特别实在,甚至有些“土味”。不久前他们刚开源了降低开发者门槛的 JoyAI-LLM Flash 模型,现在又掏出了这个死磕空间编辑的 JoyAI-Image-Edit。
京东很清楚自己的家底是什么。它没有那种泛娱乐的超级流量App,它的基本盘是全中国最重、最庞大的供应链网络。
所以,京东做AI,一手搞开源降门槛,一手直接把模型塞进电商作图、物理物流和智能家电里。
在AI这波浪潮里,跑得快固然好,但能把技术踏踏实实换成效率和真金白银的人,往往才能笑到最后。
关注塔猴公众号,扫码下载塔猴APP,查看更多干货

