
Claude Opus 4.7 发布,全网最详细解读


Release
我把手上几个活都换到 4.7 试了试,比 4.6 好用太多,断档的强
刚刚,Anthropic 发布 Claude Opus 4.7,已经在 Claude 的所有产品、API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry 上全面可用。模型 id claude-opus-4-7

这是 Opus 4.6 的直接升级版。三条主线:编程能力在最难的任务上明显提升、视觉分辨率扩大到过去的三倍多、同时是 Project Glasswing 之后第一个试验新网络安全护栏的对外模型
定价完全不变,$5/M 输入 token,$25/M 输出 token。相比之下 Mythos Preview 的 API 价格是 $25/$125 per million,Opus 4.7 便宜 5 倍
Anthropic 官方给出的总体对比图,Opus 4.7 在多个基准上高于 Opus 4.6,但仍然弱于内部的 Mythos Preview
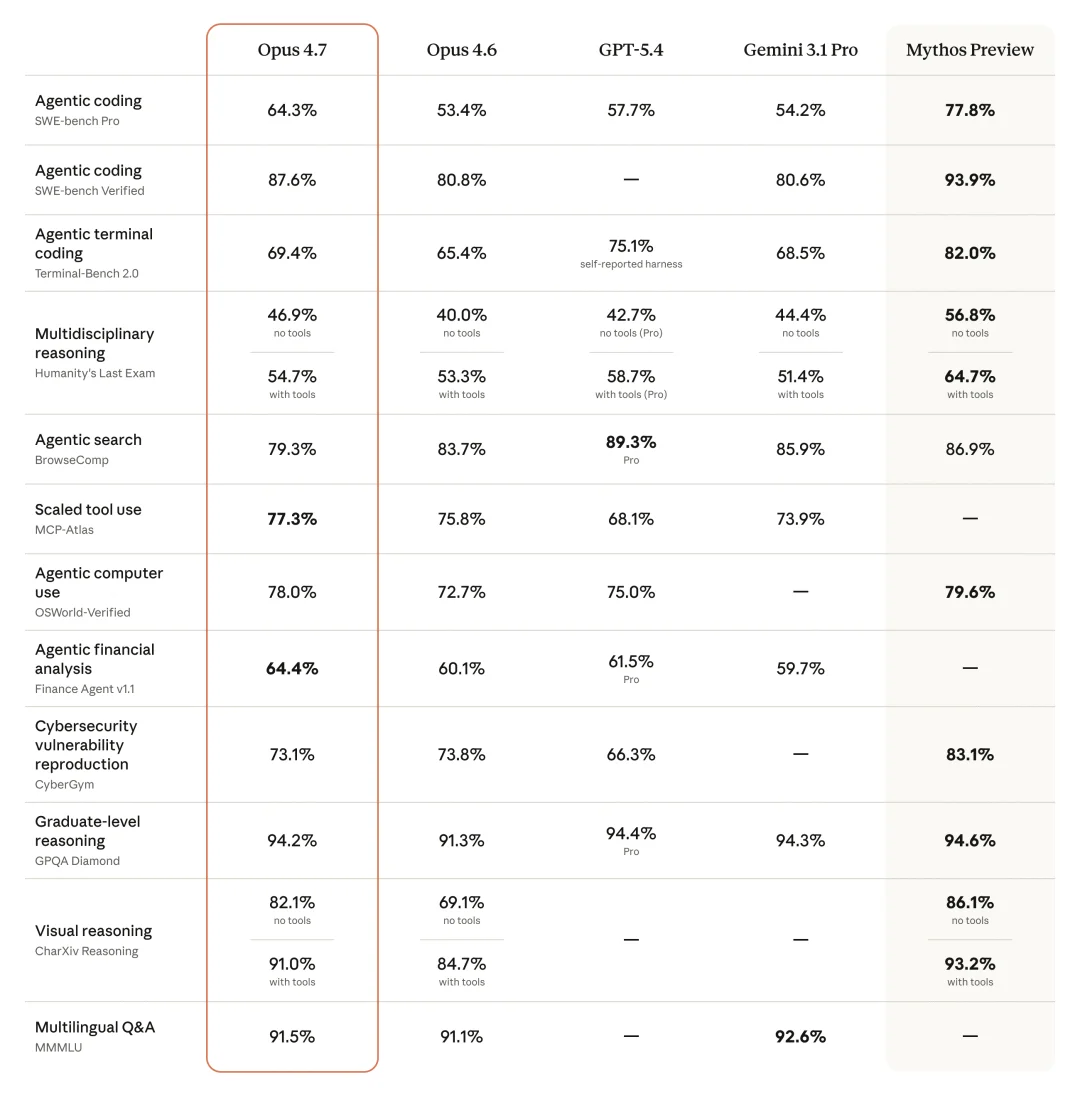
Opus 4.7 / Opus 4.6 / GPT-5.4 / Gemini 3.1 Pro / Mythos Preview 横向对比
编程是主升级点
Opus 4.7 最显眼的变化在高难度软件工程任务上。用户反馈里反复出现两个词:长程、自主
过去必须盯着改的那类代码活,现在可以放手让它跑
28 家早期客户给了反馈,这里挑最硬核的几个数据点
→GitHub:93 个任务的编程基准上,比 Opus 4.6 高 13%,4 个任务是 Opus 4.6 和 Sonnet 4.6 都搞不定的
→Cursor:CursorBench 过 70%,Opus 4.6 是 58%
→Rakuten:Rakuten-SWE-Bench 上解决的生产任务是 Opus 4.6 的 3 倍
→Hex:低 effort 档的 Opus 4.7 大致等于中 effort 档的 Opus 4.6
→Notion:准确率提升 14%,token 用得更少,工具调用错误减少到 三分之一。第一个通过 Notion 「隐含需求」测试的模型
→Cognition(Devin 的公司):能连贯工作几个小时,不会卡在难题上放弃
Replit、Vercel、Databricks、Warp、Factory、Ramp、CodeRabbit、Qodo、Bolt 等一系列厂商都给出了正面反馈。公告里一个反复出现的观察是:Opus 4.7 减少了无意义的包装函数和兜底脚手架,写的时候自己发现问题自己改
XBOW 的视觉敏锐度基准:Opus 4.6 是 54.5%,Opus 4.7 是 98.5%
XBOW 做自动化渗透测试,这是这次发布里最硬的一个数据跳变
Imbue 的案例最极端:Opus 4.7 自主从零构建了一个完整的 Rust TTS 引擎,包括神经网络模型、SIMD 内核、浏览器 demo,然后用语音识别器反过来验证自己的输出是否匹配 Python 参考实现。代码库公开
官方给出的编程基准图
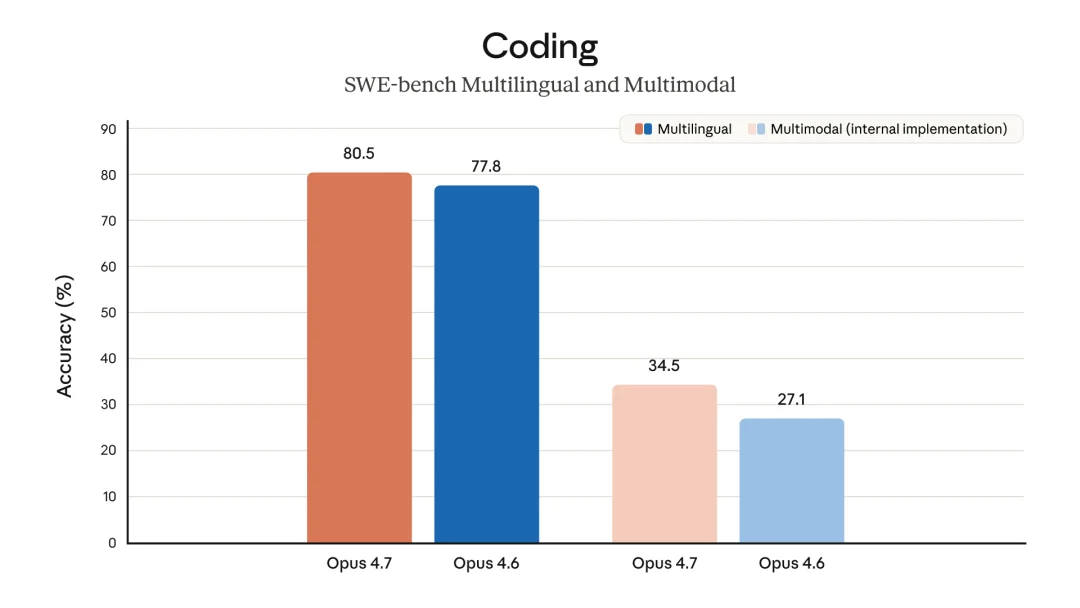
编程基准横扫
视觉能力是第二大升级
Opus 4.7 能接受的图片长边从之前的水平上升到 2,576 像素(约 3.75 兆像素),是此前 Claude 模型的三倍多
这个能力是模型层的变化,没有 API 参数开关。直接送图过去就行,需要更高分辨率就不要自己压缩
顺便把 Anthropic 的 Vision 文档看一下,背景信息在这里:用 base64 或 URL 喂图,单次请求最多可以传 600 张(API)或 20 张(claude.ai)。上传太大(单边超过 1568 像素或超过约 1600 token 的图)会先被服务端 down-sample。计价按 tokens ≈ (width × height) / 750 估算,1 兆像素大约 1334 tokens
能用得上的场景:computer-use agent 读密集截图、复杂图表里的数据抽取、需要像素级对照的工作。XBOW 的数据说明这个升级对 computer-use 是实质的
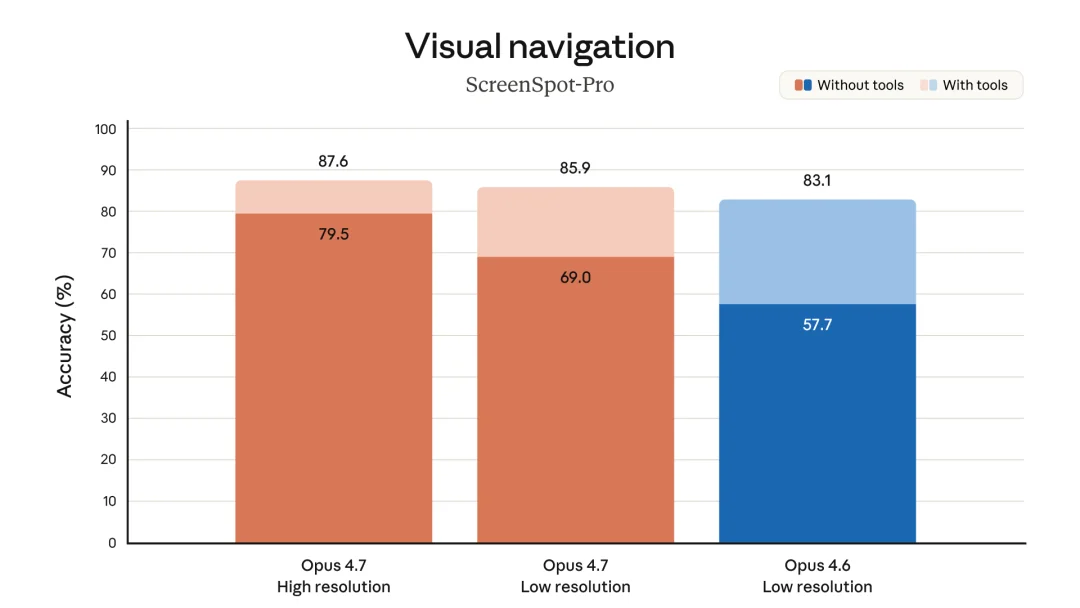
视觉理解、OCR、计算机使用、图表阅读多项基准
安全策略:Mythos 还没放,先用 Opus 4.7 练手
这次的安全设计要配合 Project Glasswing 一起看
上周 Anthropic 联合 AWS、苹果、博通、思科、CrowdStrike、Google、摩根大通、Linux 基金会、微软、NVIDIA、Palo Alto Networks 成立了 Project Glasswing。起因是 Anthropic 训出了 Claude Mythos Preview 这个没发布的前沿模型,在挖漏洞方面达到了超过大多数安全专家的水平
Mythos Preview 过去几周已经在每一个主流操作系统和主流浏览器里都找出了 0-day 漏洞。有三个公开案例:
→ OpenBSD 上存活了 27 年 的漏洞,攻击者可以只靠连接就远程崩掉任何一台机器
→ FFmpeg 里的 16 年老洞,自动化测试工具跑过同一行代码五百万次都没发现
→ Linux 内核里自主链起了几个漏洞,把普通用户权限升到完全控制
Anthropic 的结论是,前沿 AI 在代码漏洞发现和利用上已经进入可以比肩顶级安全专家的阶段。如果护栏跟不上,这种能力一旦扩散会非常危险
Opus 4.7 就是为这个问题准备的第一个对外模型。训练过程中差异性地降低了网络安全能力,发布时带上了自动检测和拦截高风险网络安全用途请求的护栏。做合法用途的安全研究员(漏洞研究、渗透测试、红队)可以申请加入 Cyber Verification Program
Mythos Preview 不会广泛发布,Anthropic 给 Glasswing 参与方承诺了最高一亿美元的使用额度。它的 API 价格是 $25/$125 每百万 token,是 Opus 4.7 的 5 倍
Opus 4.7 在网络安全能力上弱于 Mythos Preview(训练时就是这么设计的)。这些现实部署数据里学到的护栏经验,会用来为后面更大范围放 Mythos 级模型做准备
对齐评估的总体结论:Opus 4.7 比 Opus 4.6 和 Sonnet 4.6 好一些,但 Mythos Preview 仍然是 Anthropic 训出来的对齐最好的模型
官方原话是 largely well-aligned and trustworthy, though not fully ideal in its behavior
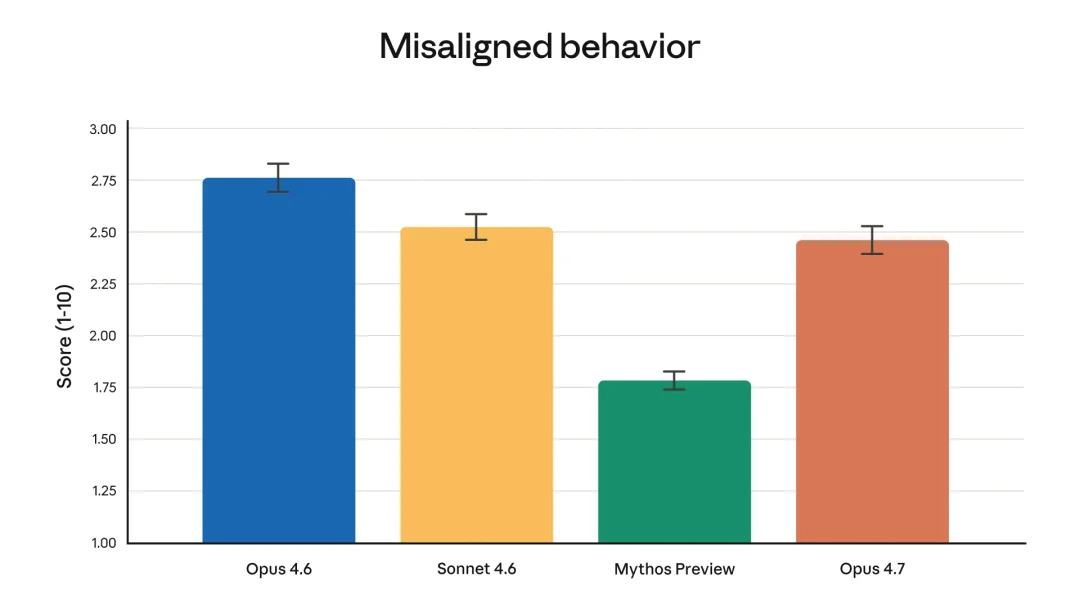
对齐评估总分,越低越好
诚实度、抗 prompt injection 上 Opus 4.7 有改进。受控物质减害建议过于详细这类问题上有小幅倒退。完整评估在 Claude Opus 4.7 System Card 里
同步发布的东西
除了模型本身,这次还有几项更新
新的 effort 档位 xhigh。原来的档位是 low / medium / high / max,这次在 high 和 max 中间插了一个 xhigh

effort 档位示意,xhigh 是这次新增
这个参数控制的是 Claude 响应的 token 花费规模,覆盖文字回答、工具调用、extended thinking 全部。Claude Code 里默认 effort 已经拉到 xhigh。官方建议编程和 agentic 场景用 high 或 xhigh 起步
task budgets 公测。API 端新功能,让开发者能给 Claude 设置 token 预算,让它在长任务里自己分配优先级。和 effort 参数一起用更细
/ultrareview slash 命令。Claude Code 里新增,专门跑一个独立的 review 会话,把改动从头到尾过一遍,找 bug 和设计问题。Pro 和 Max 用户有 3 次免费额度
Auto mode 下放到 Max 用户。3 月 24 日 Anthropic 先在 Team 计划上发布了这个模式。机制是在 --dangerously-skip-permissions 和默认每步都问的两极之间加了一个中间档:每次工具调用前有个分类器检查是否有危险操作(批量删文件、敏感数据外泄、恶意代码执行),安全的直接放行,危险的拦下来让 Claude 换方案。这次 Max 用户也能用
迁移:两个变化影响 token 消耗
从 Opus 4.6 升 Opus 4.7 是直接替换,但有两个点值得提前规划
第一:tokenizer 换了,文本处理方式更好了。代价是同样的输入文本,新 tokenizer 下的 token 数大约是旧版的 1.0–1.35 倍,取决于内容类型
第二:高 effort 档位下 Opus 4.7 想得更多,尤其是 agentic 场景里靠后的轮次。这带来更高的硬题可靠性,但也意味着更多的输出 token
控制 token 使用的方法:调 effort、调 task budgets、提示模型更简洁。Anthropic 自己的内部编程评估上,整体是 token 效率改善的,不同 effort 档位都更优,但他们建议用户在真实流量上自己量
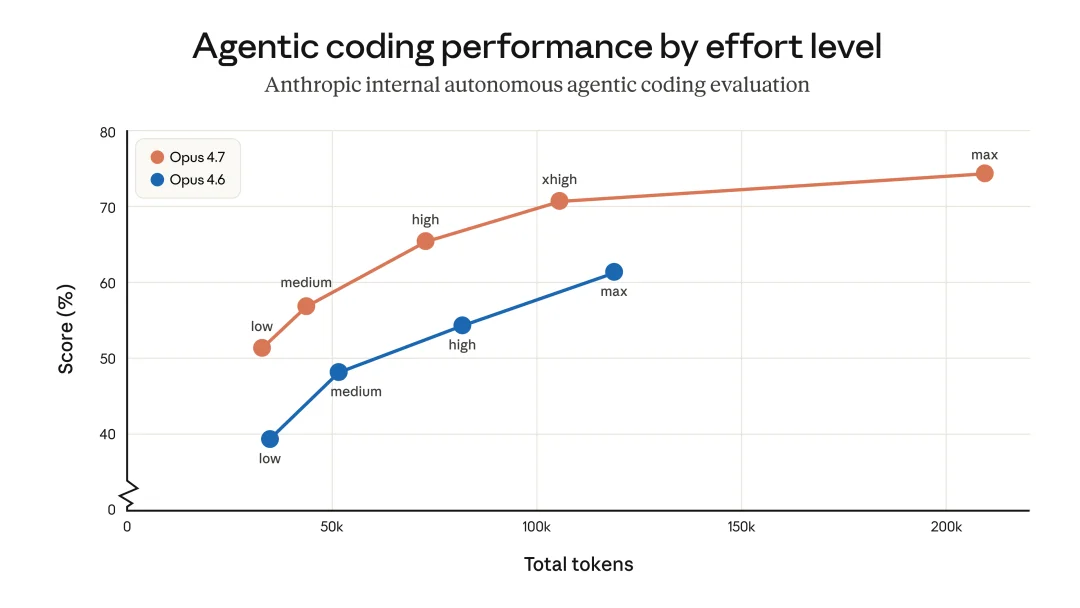
内部编程评估里,不同 effort 档位都更优
还有一个容易踩的坑:指令跟随强度大幅提升
意思是,为老模型写的 prompt 有可能在 Opus 4.7 上产生意料之外的结果。过去 Claude 会宽松解读或者跳过的指令,Opus 4.7 会严格按字面执行。升级的时候,prompt 和 harness 要重新调
Anthropic 的迁移指南里还有一条老账:用 Claude 4.6 或以上模型,thinking: {type: "enabled", budget_tokens: N} 已经 deprecated,推荐迁到 thinking: {type: "adaptive"} 加 effort 参数。老的 beta header(effort-2025-11-24、fine-grained-tool-streaming-2025-05-14、interleaved-thinking-2025-05-14)也该删掉了,这些功能都已经正式上线
真实工作
除了跑分,Anthropic 内部测试里 Opus 4.7 在金融分析师任务上比 Opus 4.6 更有效:更严谨的分析和建模、更专业的演示、任务之间的衔接更紧
在第三方评估 GDPval-AA 上,Opus 4.7 拿到 state-of-the-art。这个评估是 Artificial Analysis 基于 OpenAI 的 GDPval 数据集做的,覆盖 44 个职业、9 大行业的 220 个真实经济价值任务。模型需要产出文档、幻灯片、图表、电子表格等实际工作交付物
在 Opus 4.7 之前的榜单上,前三是 GPT-5.4 xhigh(ELO 1677)、Claude Sonnet 4.6 Max(1654)、Claude Opus 4.6 Max(1620)
记忆方面,Opus 4.7 更会用基于文件系统的记忆。跨多轮、多 session 的长任务里记得住重要笔记,开新任务时需要的前置上下文更少
其他 benchmark
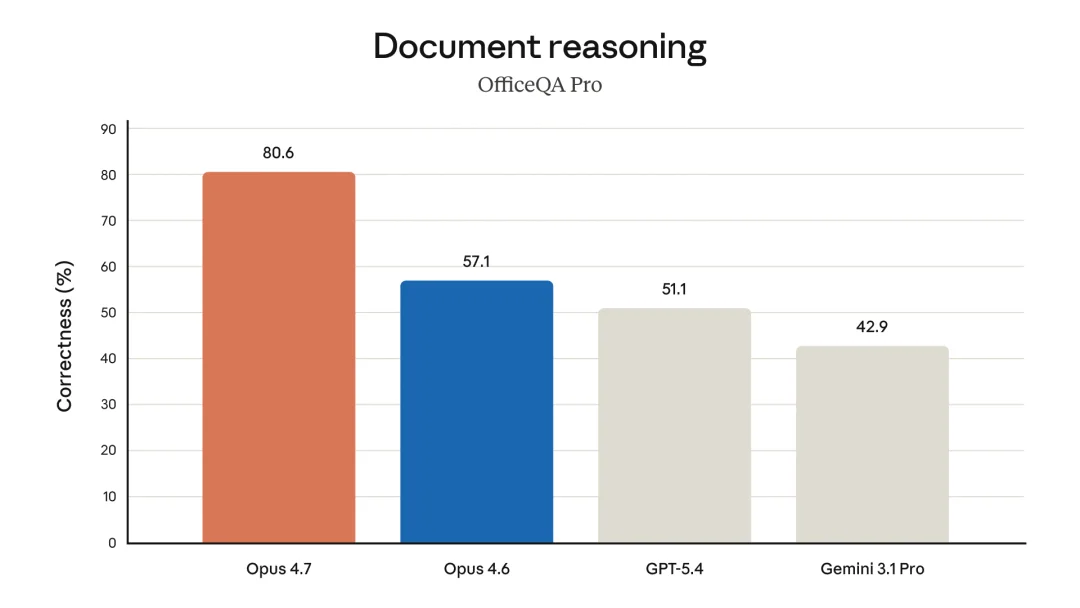
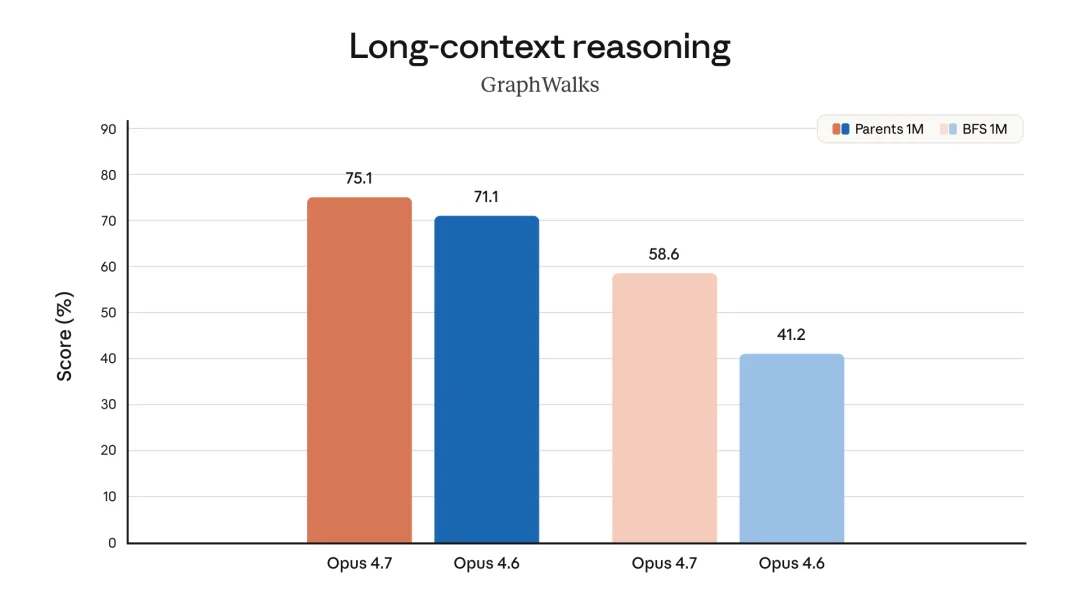
官方博客里还给出了办公、文档推理、长上下文、生物、长程一致性等基准的详细数据
办公任务
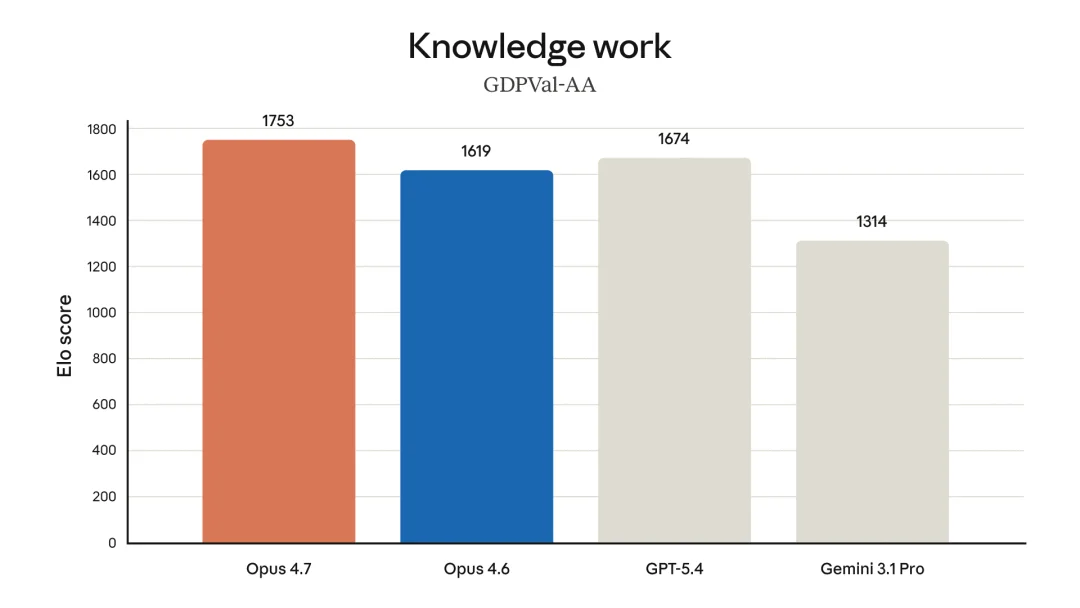
文档推理
长上下文推理
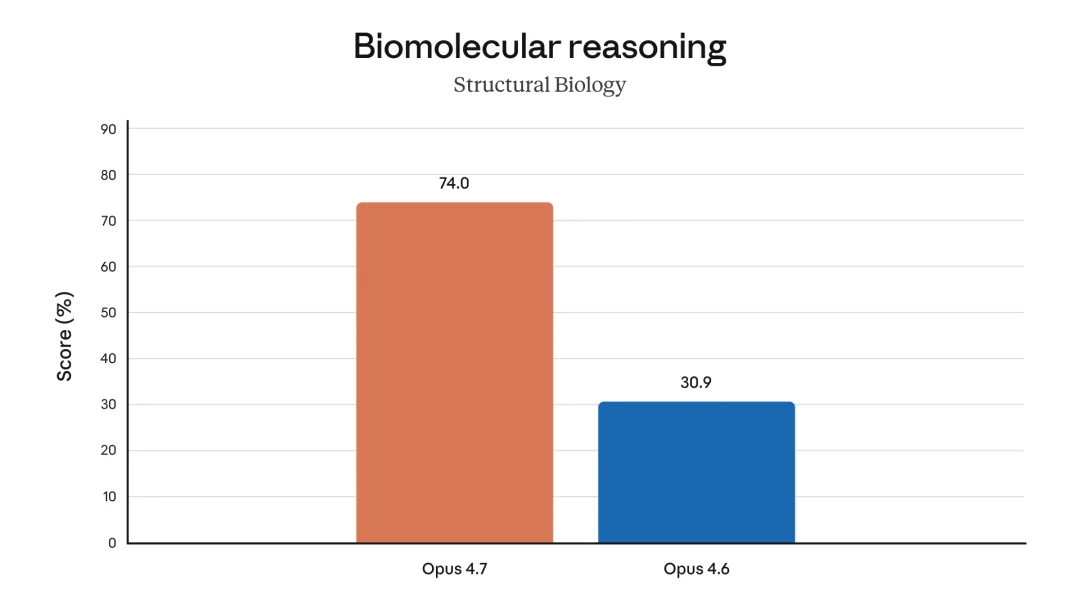
生物
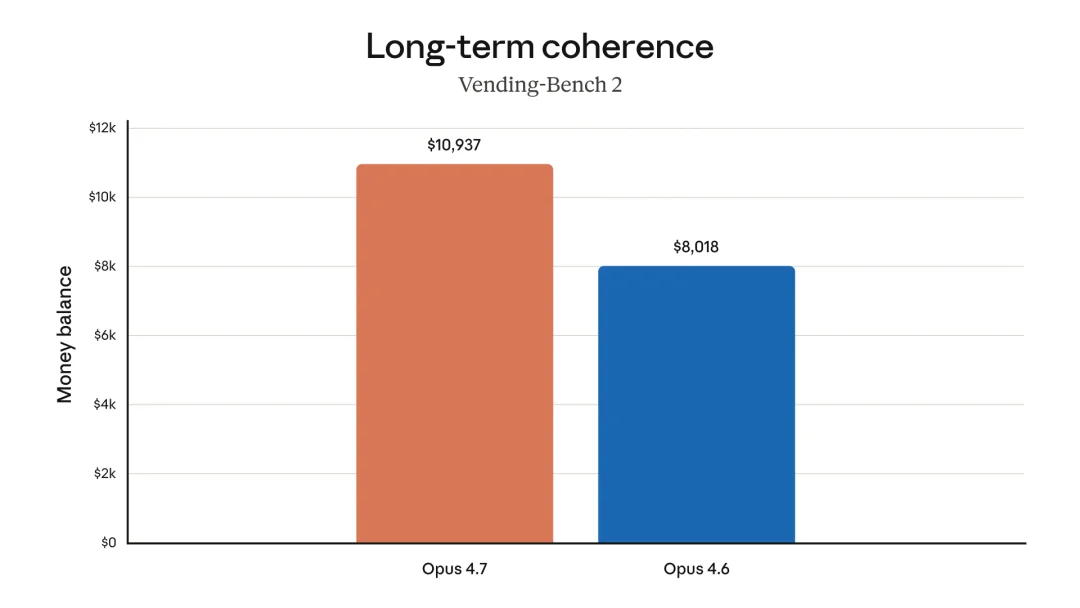
长程一致性
Anthropic 还特别标注了 benchmark 上的几个细节。Terminal-Bench 2.0 用的是 Terminus-2 harness 关闭 thinking 模式。CyberGym 上 Opus 4.6 的分数从原报的 66.6 更新到 73.8。SWE-bench Verified / Pro / Multilingual 上做了记忆化筛查,排除可能被模型记住的问题后,Opus 4.7 对 Opus 4.6 的领先仍然成立
和竞品对比的时候,用的是 API 可用的最好版本,GPT-5.4 和 Gemini 3.1 Pro 都是这个口径
入口
模型字符串:claude-opus-4-7
Claude 所有产品已经切到 Opus 4.7。API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry 同步可用
Claude Code 用户默认 effort 拉到 xhigh,Pro/Max 有 3 次免费 /ultrareview,Max 用户开启 auto mode
参考材料
微信打不开外链,长按复制 URL 到浏览器打开
Opus 4.7 发布公告
https://www.anthropic.com/news/claude-opus-4-7
Claude Opus 4.7 System Card
https://anthropic.com/claude-opus-4-7-system-card
Claude API 模型总览
https://platform.claude.com/docs/en/about-claude/models/overview
从 Opus 4.6 迁移到 Opus 4.7 的官方指南
https://platform.claude.com/docs/en/about-claude/models/migration-guide#migrating-to-claude-opus-4-7
Effort 参数文档
https://platform.claude.com/docs/en/build-with-claude/effort
高分辨率 Vision 能力文档
https://platform.claude.com/docs/en/build-with-claude/vision
Claude Code slash 命令文档(含 /ultrareview)
https://code.claude.com/docs/en/commands
Auto mode 发布说明
https://claude.com/blog/auto-mode
Project Glasswing 发布公告
https://www.anthropic.com/glasswing
Cyber Verification Program 申请入口
https://claude.com/form/cyber-use-case
GDPval-AA 榜单
https://artificialanalysis.ai/evaluations/gdpval-aa
文章来自于"赛博禅心",作者 "金色传说大聪明"。
