
Claude Opus 4.7正式发布:编程、Agent、视觉全面升级,真香还是割韭菜?

2026年4月16日,Anthropic深夜发布Claude Opus 4.7,距离上一代Opus 4.6的发布,才刚刚过去两个月
这一手,多少有点不讲武德。
在AI模型竞赛里,旗舰级的更新通常以半年甚至更长为周期,这种发布节奏,把所有竞争对手都打了个措手不及。
Anthropic到底在急什么?是王者归来,还是旧瓶装新酒?
网上分为两派,有人说“这才是完全体”,这不是一次简单升级。有人则认为4.7就是未削弱的4.6,“这波操作我熟,先偷偷给4.6砍一刀,再把没砍的版本当成4.7发布出来,再赚一笔。”
我们不禁在想,Opus 4.7这瓜,真的保熟吗?


Mythos的影子
Anthropic官方表示,Opus 4.7是一个更安全、可大规模部署的版本,它搭载了从Mythos身上验证过的新防护机制。也就是说,Opus 4.7内部藏着被严格限制的神级模型Claude Mythos Preview,这个神级模型因网络安全风险被锁在了一个凡人之躯里,而Opus 4.7就是这个凡人之躯。
那么,这个凡人,究竟强在哪里?
以前我们用claude写代码,需要时刻盯着它的生成结果,怕它哪个变量名写错,哪个逻辑跑偏,现在Opus 4.7给人的感觉完全变了。你把一个软件需求扔给它,它不是闷着头就写。它会先想一想,先会自己设计一套验证方案,在跑通后,确认没问题了,再把带注释的代码交给你,更有章法,更让人放心了。
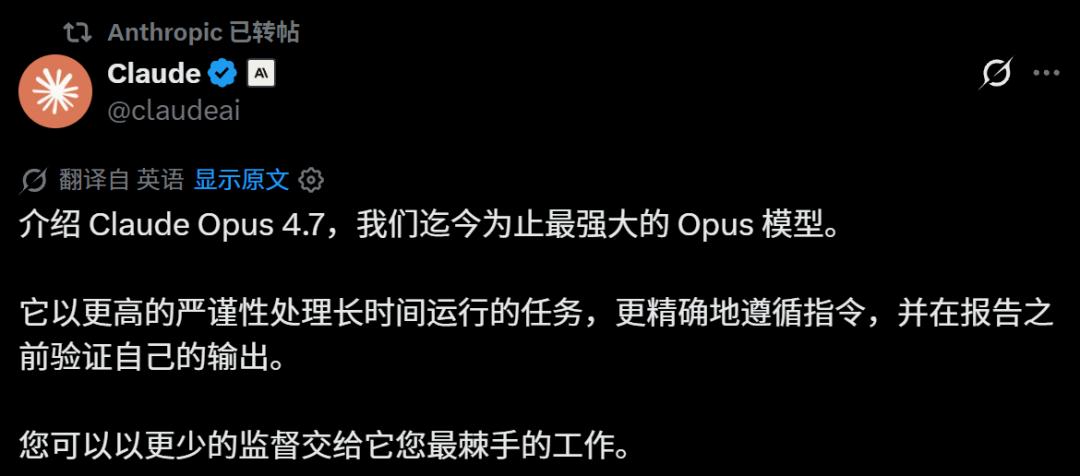
根据Anthropic的官方基准测试,Rakuten-SWE-Bench的任务集上,Opus 4.7解决问题的能力是4.6的三倍。以前三个棘手的编程问题,4.6能搞定一个,现在4.7能三个问题全摆平。
不仅如此,Claude Code工具集里还新增了一个“ultra review”的命令,能一键揪出代码里的bug。

定价的文字游戏
聊了这么多升级,也该谈谈代价了。
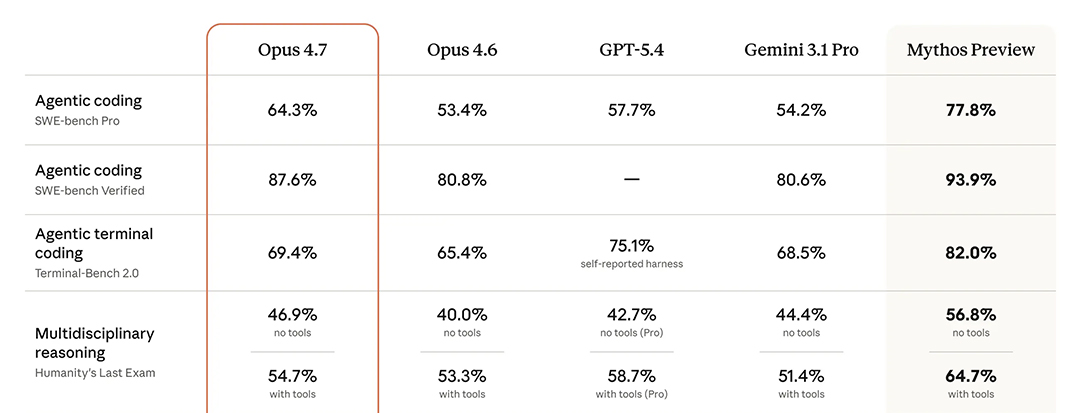
Anthropic说得很好听:“定价不变!” 每百万输入词元5美元,输出25美元。但我们很快发现,事情没有那么简单。
简单来说,AI模型算钱是按词元(token)来的,一个词元可以理解为一个单词或一个汉字。但Anthropic给Opus 4.7换了一本新的字典,也就是新的tokenizer。
在这本新字典里,一些你常用的词语、代码片段或者标点符号,被拆分成了更多个词元。所以,你和过去同样输入的一段话,用4.7来处理,它计算出的词元会比4.6更多,官方承认最多能多出35%。
单价没变,但计件的标准变了,典型的互联网大厂定价,明降暗升。

4.7是没被削弱的4.6吗?
聊完成本,我们再聊回最开始的话题,Opus 4.7这瓜,保熟吗?
在Reddit和X上,大家婆说婆有理,有人了详细的对比图,力证4.7在长文本问答上,和几个月前没被削弱的4.6几乎一模一样。
也有人反驳,认为新模型只在特定任务上有优化,不能一概而论。他们认为,单单编程能力的提升,就证明这是个全新的模型。

面对舆论,Anthropic的官方解释是:“Opus 4.7是首个搭载了我们从Project Glasswing项目中验证过的网络安全防护机制的旗舰模型。”
这个说法非常巧妙,没直接回答Opus 4.7究竟是不是换皮,我们只知道内部安全机制的确有调整。
官方说这是为了安全加了新锁,而部分用户认为是把之前的锁给解了。真相到底如何,也许只有Anthropic自己知道。(微信公众号:Tahou_2025)

