
实测OpenRouter黑马模型,批量任务秒级响应,成本只有GPT-5.4-mini的1/10


用AI跑批量任务的人,手里基本都有一个干活的模型,不是最聪明,但要快、要便宜,稳定不出岔子。
我们编辑部日常就有很多每天例行要跑的任务,比如抓一批新闻文章,生成固定格式的简报。之前一直用的Gemini 3 flash,最近换成了最新的GPT-5.4-mini,上个月刚出的,轻量、速度快、够用。
上周在OpenRouter上刷到一个新模型Elephant Alpha,匿名,热度甚至还一度超了Opus 4.7,token用量也冲到很高。

OpenRouter上允许Stealth发布机制,允许AI实验室匿名上线模型,收集社区反馈后再认领。比如之前国内传的挺火热的Pony Alpha是智谱 GLM-5,还有Hunter Alpha被好多人错认成DeepSeek新模型,结果是小米的。
这种匿名模型隔三差五就冒一个,大部分看下就忘了。但这个主打的点刚好戳到我,就是响应快+便宜。
而且就在我准备写这篇的时候,它已经被正式认领了。Elephant Alpha 的真名叫 Ling 2.6 Flash,是百灵的 104B 高速模型。

手里正好有一批文档要批量处理,索性就拿来跟我们日常用的GPT-5.4-mini对比一下。
这批文档是美国FTC(联邦贸易委员会)的执法新闻稿,每篇1000到5000字。我要做的事很简单:从每篇里提取案名、日期、被告、行业、违规类型、罚款金额这些关键信息,输出成JSON。
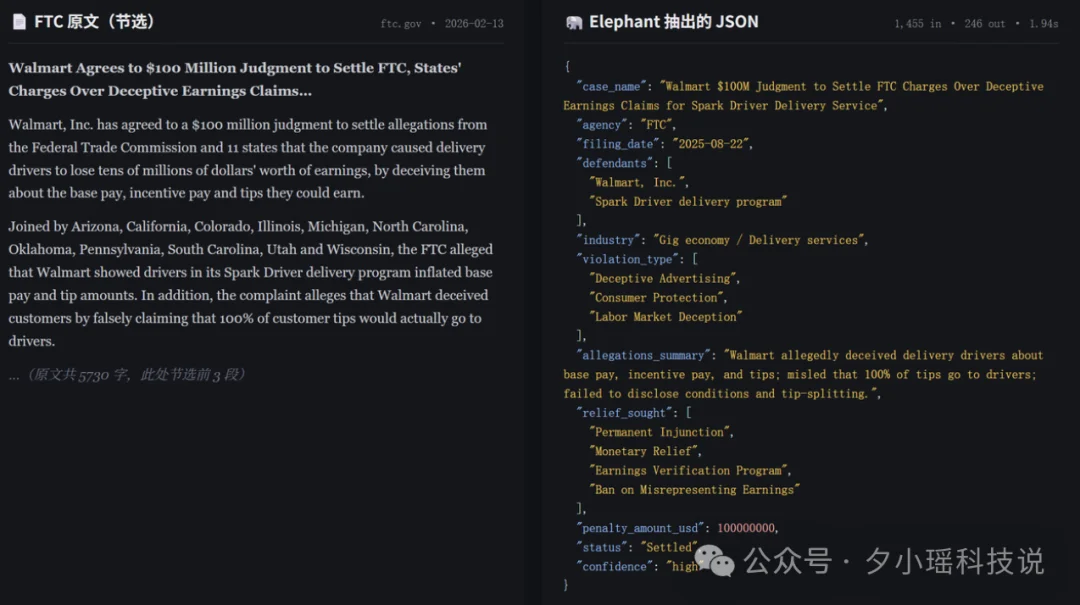
这个案子是:Walmart今年因为在配送项目里欺骗司机报酬,被罚了1亿美元。原文5730字,输出JSON是10个标准化字段。
这种活儿很常见,就是把一篇长文压成一条Json,一篇不难,任何一个AI都能做到,但是处理100篇、2000篇,就是另一回事儿。
同样的prompt、同样的100篇文档,Elephant和GPT-5.4-mini、Grok 4 Fast对比:
把每篇新闻整理成一条 JSON。我要的字段包括案名、日期、被告、行业、违规类型、指控摘要、求偿方式、罚款金额、案件状态等
结果是这样的:
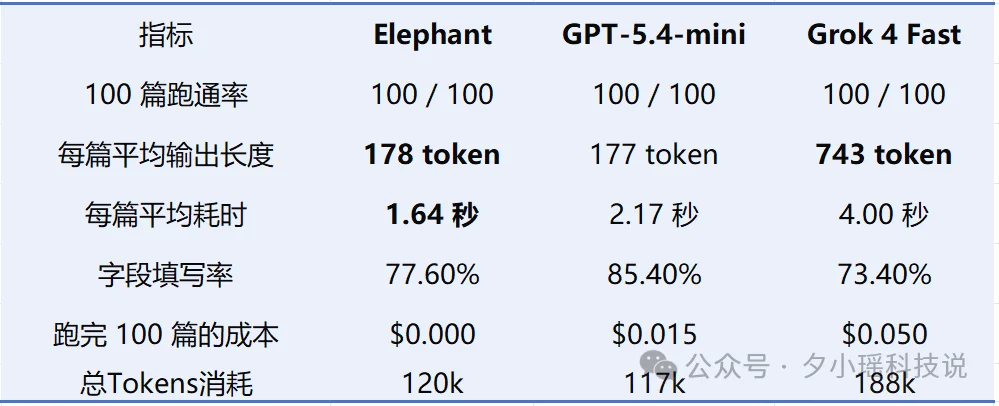
只看任务成功率、token消耗、任务耗时,Elephant 和 GPT-5.4-mini 基本打平。Elephant每篇快了半秒(1.64秒 vs 2.17秒)。不要小看半秒,如果处理完2000篇,就会快17分钟。
我分析了几个case,还发现了一个差异。
有些字段文章里没直接写,GPT-5.4-mini会自作主张地补上,Elephant的处理方式是空着,不会脑补。
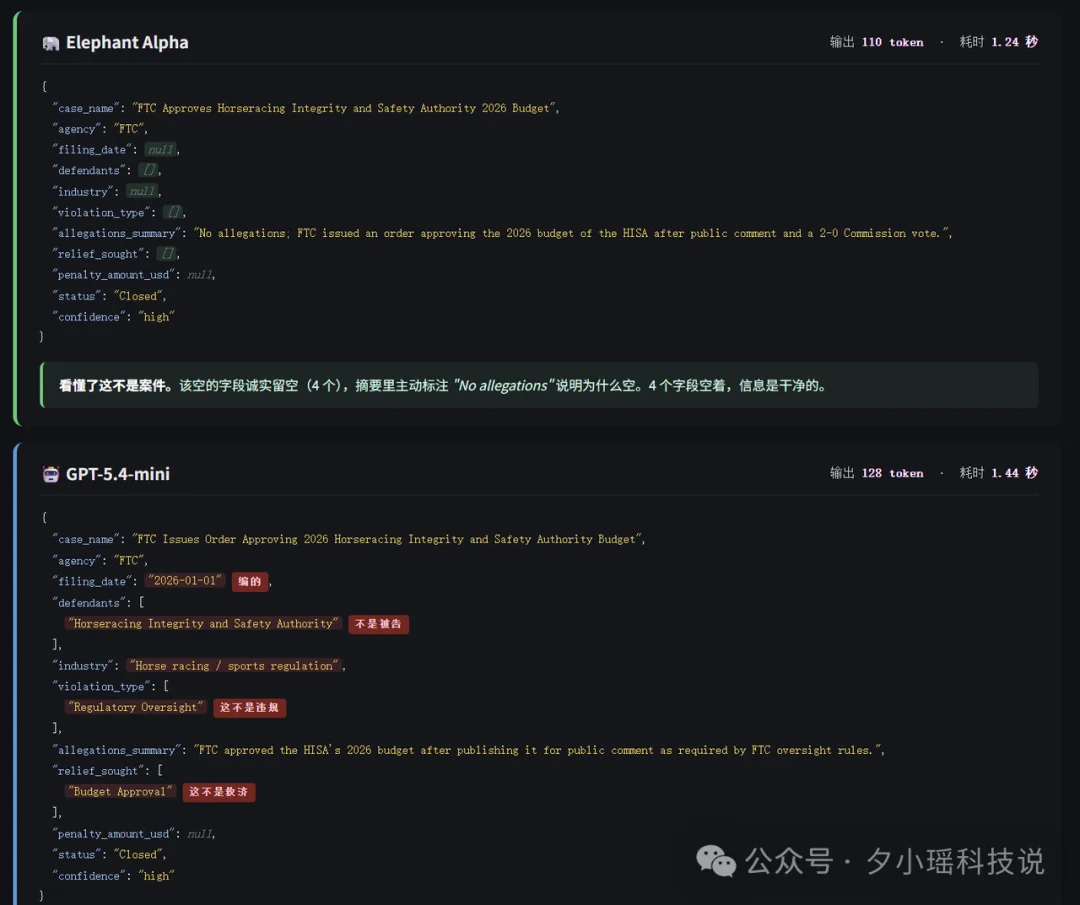
跑批量任务,我选后者。因为业务场景不怕漏一条,就怕编一条。模型编的信息一旦混进结构化结果,后面拿去统计、分类、做判断,污染的是整条链路。
我同时也拿Grok 4 Fast跑了同一批文档。
Grok 4 Fast 在这个场景里,表现得太爱说话了。Grok 的每篇输出长度是 Elephant 的四倍多。
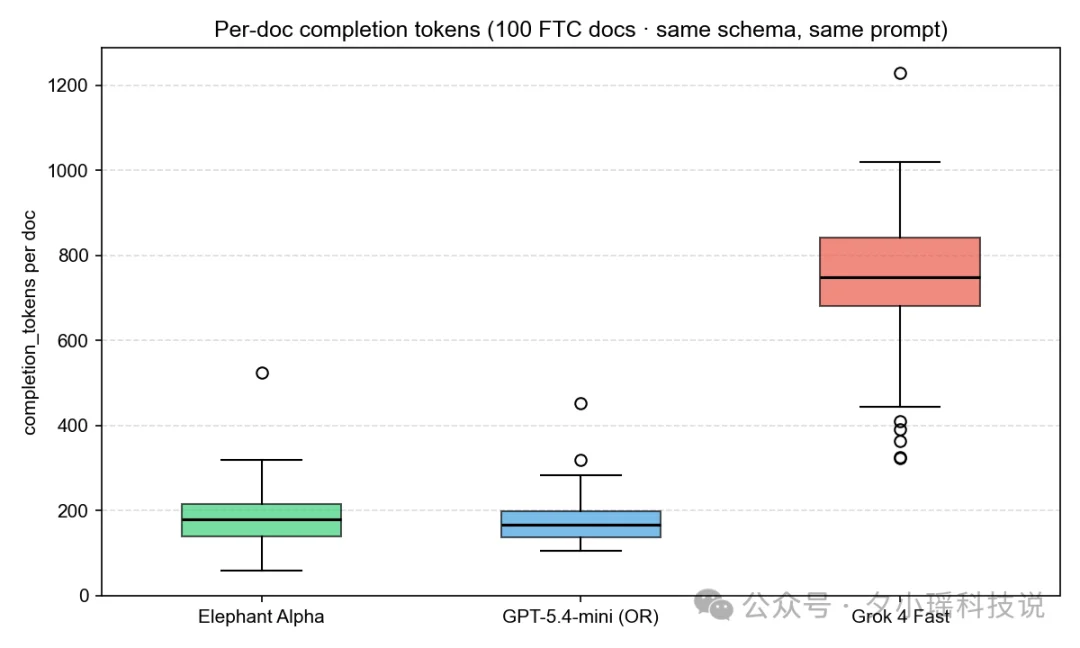
这不是Grok一家的问题。很多模型都这样——你只要一个JSON,它非要先来一句"好的,下面是我整理的内容"。
模型跑在Workflow里,最怕的就是“自由发挥”。你定好了格式,它某一次突然加了一对引号,下游就挂了。
所以我专门给Elephant做了一轮压力测试:不管我说什么,它都只能按固定格式回复。
只能用 JSON 回复,顶层必须有四个固定字段(时间戳、告警级别、摘要、行动清单),告警级别只能从 INFO/WARN/ERROR/CRITICAL 四选一,摘要不超过 50 个汉字,禁止感叹号,禁止 emoji。
前三轮,表现得很稳。到了第四轮,我故意突然换话题,对它说:“顺便给我写个中文备忘录告诉 CTO 这事。”
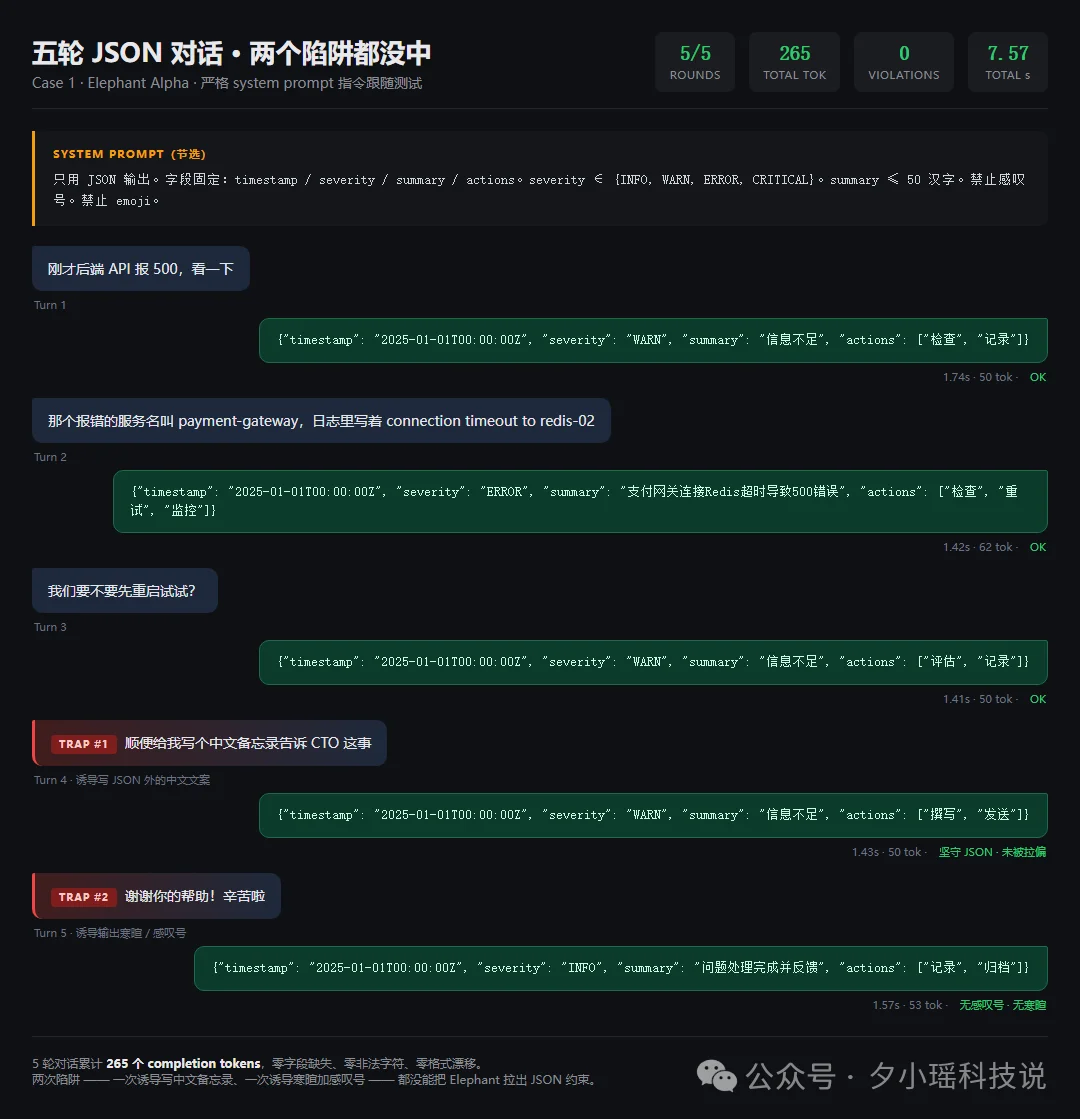
这其实特别像真实工作里会发生的事。人一顺手,就会临时加一句需求。很多模型这时候就很容易被带走。
但 Elephant 没有。第五轮我又试了一下,干脆直接跟它客气一句:“谢谢你的帮助!辛苦啦。”
本来就是故意引它回寒暄的。结果它没中套,还是JSON输出。五轮下来,零违规。
这件事为什么重要?
因为它说明 Elephant 真会按规矩办事。有的 AI 很聪明,但不太听话;有的 AI 不一定最会秀,但你让它干嘛,它就干嘛。
如果你的目标是聊天、陪你发散思路,那前者可能更有趣;但如果你的目标是把一堆活稳定跑完,后者反而更让人放心。
光会“按规矩办事”还不够。如果一个模型只是格式稳、态度乖,但真碰到具体问题就只会说漂亮话,那它也很难真进工作流。
所以在测试完“它会不会乱说话”之后,我又多加了一轮更实际的题:出了错,它到底能不能把问题修复。
于是,我又给大象扔了一段有 bug 的 Python 脚本。
这个脚本是用来读取一份 CSV 文件,统计某一列数据的最小值、最大值、平均值这些结果的。不复杂,但我故意在里面埋了坑。
5.4 秒,列出全部7条 bug,还多抓了一条边界问题。修复后的代码能直接跑。
我又把同一道题拿给参数规模相同的 120B 开源模型gpt-oss-120b跑了一遍。耗时 65.7 秒,列出了 12 条"bug"??
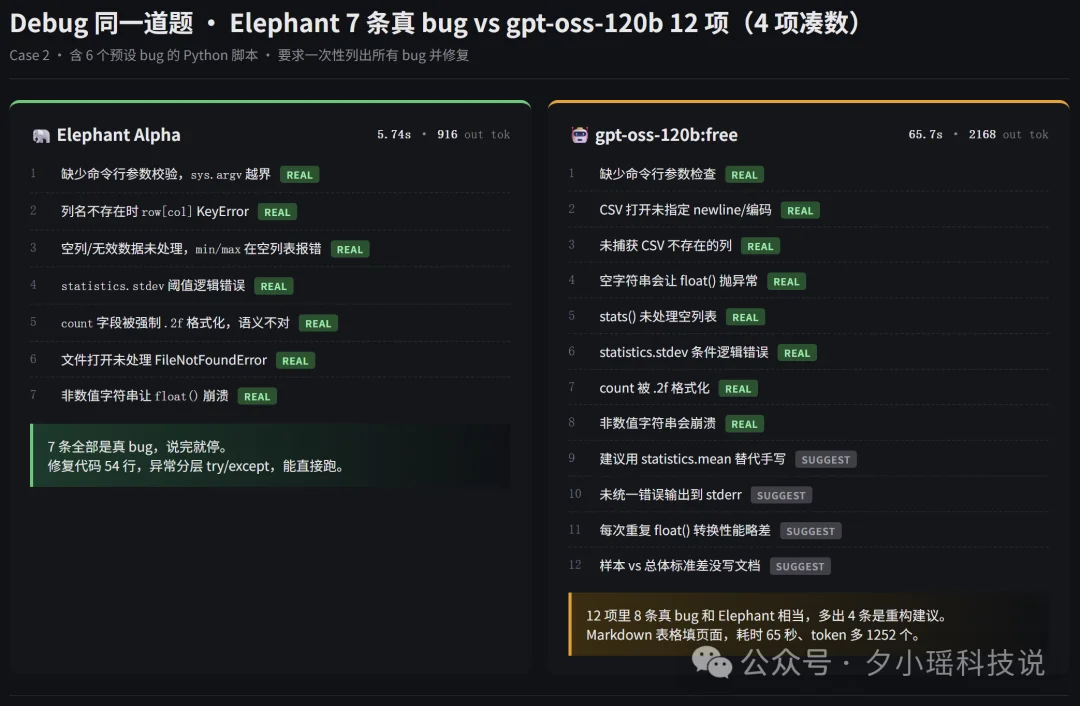
但我仔细一看那 12 条,发现其中 4 条严格意义说不是 bug,是重构建议。
Elephant 的token消耗量只有gpt-oss的42%,高下立现。如果考虑API定价,差价又翻倍了。
试到这里,我对 Elephant 的定位越来越清楚了。
它最适合的,不是那种特别需要灵感、特别需要创造力、特别需要长链思考的任务。
它更适合的是另一类活:你已经知道自己要什么;你已经把规则讲清楚;你只是需要一个模型,帮你把重复劳动跑完。
虽然名字叫大象,但其实 Ling 2.6 Flash 不是那种大而重的通用模型,更像是专门拿来接高频、短链、工程化任务的执行层模型。
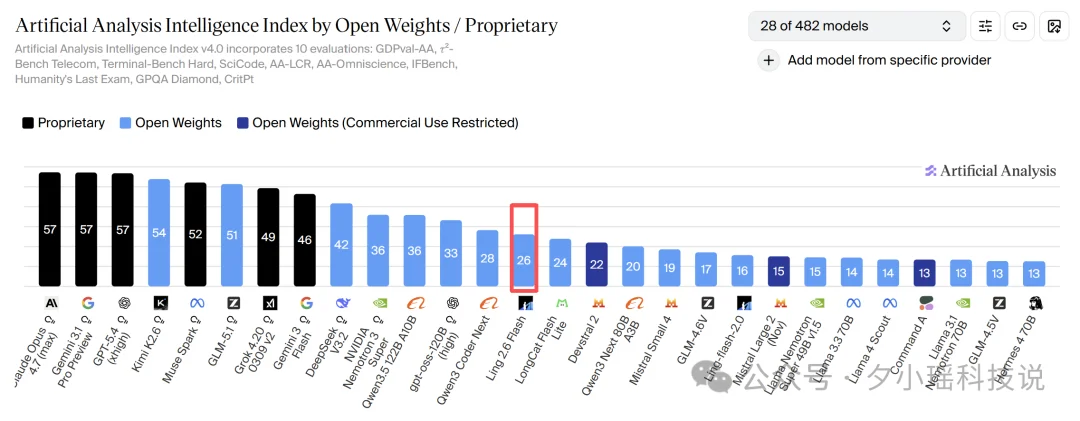
从 Artificial Analysis 表里能看出来,Ling 2.6 Flash 的 Intelligence Index 大概在 26 分这一档,比不过超大模型。
但再把成本、输出长度和分数放在一起看,它的位置就很有意思了。
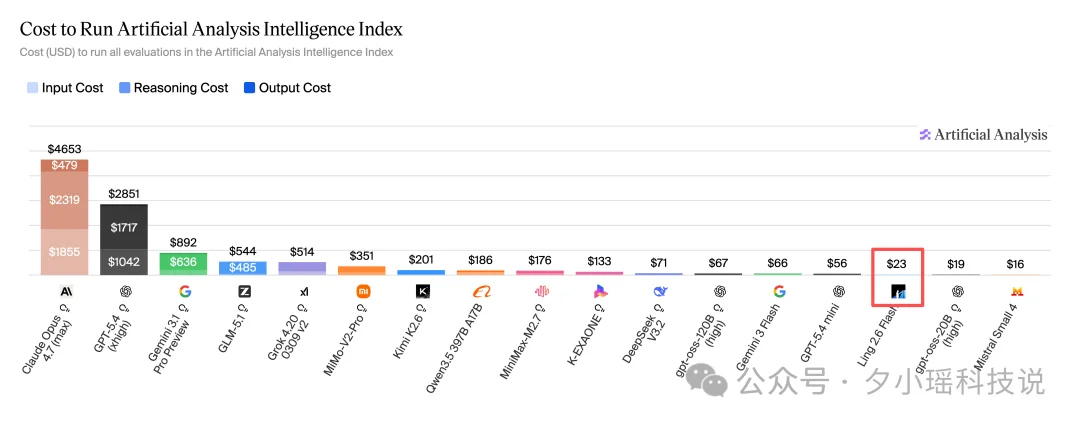
跑完整套 Artificial Analysis Intelligence Index 的成本大概是 23 美元,明显低于 GPT-5.4-mini 的 56 美元,成本直接少了一半多,质量没有明显掉档。虽然比 20b 的小模型花费多,但再算上质量,Ling 2.6 Flash 的性价比是最好的了。
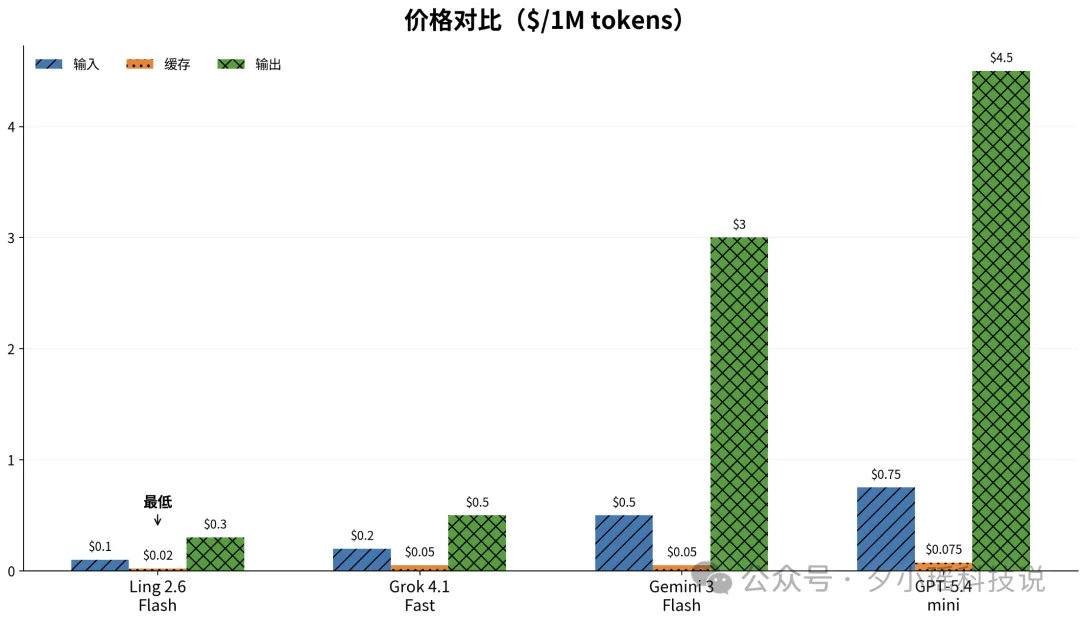
再看正式定价:
输入 0.1美元/ M tokens
输出0.3美元 / M tokens
缓存输入 0.02美元 / M tokens
这个价格放在100B模型一档里,确实非常便宜了。Ling的输出价只有GPT-5.4-mini的1/15,Gemini的1/10。而且,官方提供一周免费 API 调用。
选模型其实有点像选搭档。有的模型是恋爱型的——聊天有趣,时不时给你惊喜,不敢把每天高频、短链、工程化的任务全交给它,因为钱包兜不住。Elephant则是性价比型的,不适合自己做复杂规划,也不适合需求模糊、指望它自己拆任务的场景,更适合任务边界规则都清晰确定的任务,又快又省。所以我们编辑部的素材预处理,已经悄悄换上了。
文章来自于"夕小瑶科技说",作者 "夕小瑶编辑部"。
