
ControlNet教程:姿态骨架与深度图控制


ControlNet是Stable Diffusion生态中最具变革性的控制技术。本文针对AI绘画中“构图不可控、姿态难精准、空间易混乱”的核心痛点,系统讲解ControlNet教程,围绕姿态骨架控制与深度图控制两大核心技术展开,从工作原理到参数设置、从单一控制到多单元堆叠,通过完整案例帮助读者实现从“AI随机生成”到“AI精准构造”的进阶。
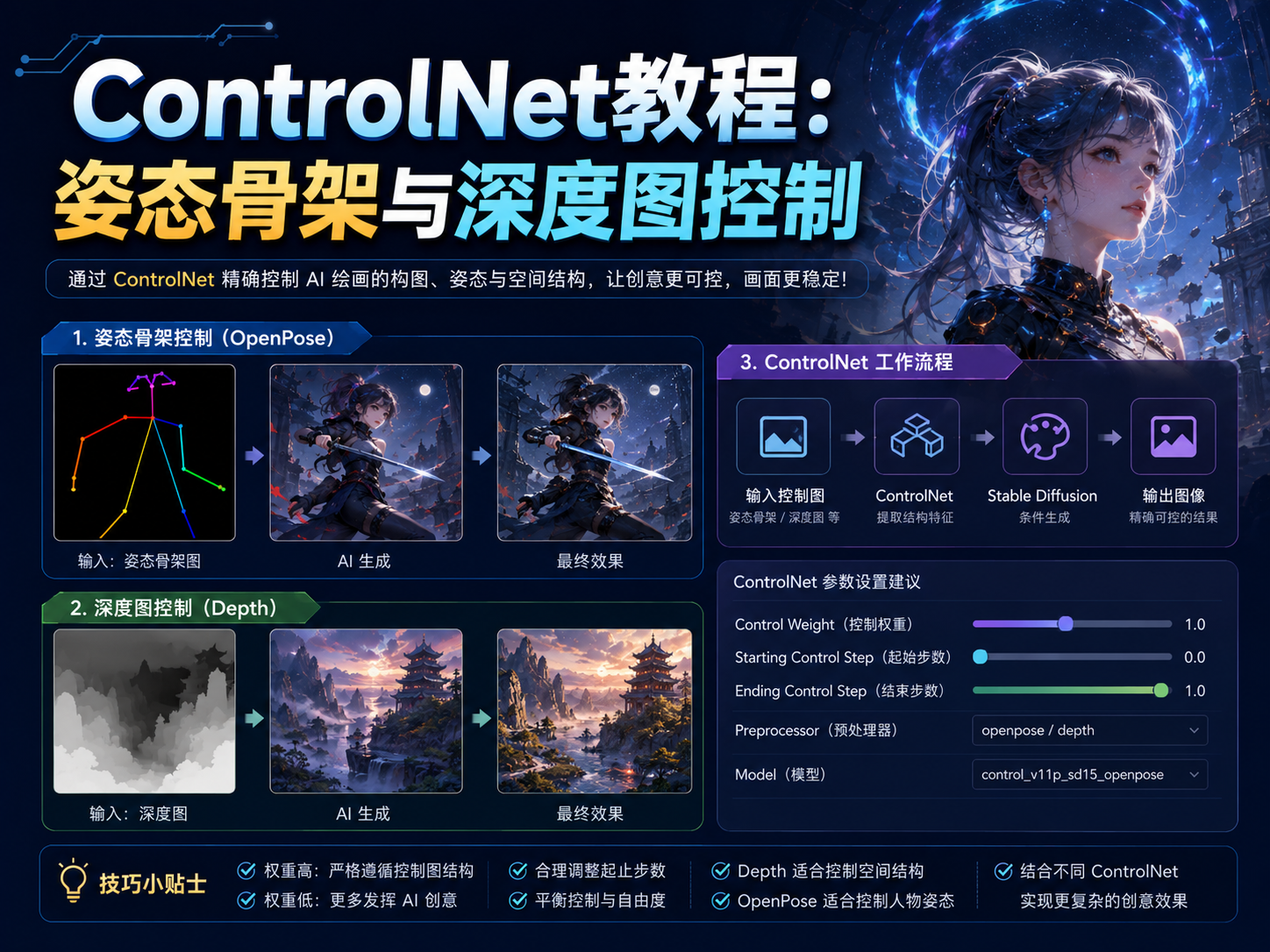
一、理解ControlNet:为AI建立空间与姿态的约束
1.1 为什么需要ControlNet
在AI绘画中,仅仅依靠文本提示词来引导图像生成,就像只给一位画家口头描述“画一个人”,这位画家的脑海里可能浮现出千百种不同的形象。即便在提示词中加入“双手叉腰站在海边”,模型生成的结果中,人物可能转身背对镜头、手臂姿势不对,或者构图完全不是预想的样子。原因在于纯文本控制存在着天然的局限。文本描述本身就存在着语义上的模糊,一个词可能对应多种不同的视觉表现。当场景变得复杂时,又难以精确描述空间关系、姿态和构图细节。即便写出了看似详细的提示词,文字描述的画面也和模型实际理解的图像之间,始终隔着一道语义的鸿沟。
ControlNet的出现,正是为了解决这一核心问题。如果说文生图是告诉AI“画什么”,那么ControlNet就是告诉AI“怎么画”。它好比是为AI戴上了“骨架”和“透视镜”,使其严格按照线条、姿势和空间结构进行绘制。
1.2 ControlNet的核心工作原理
ControlNet是一种基于扩散模型的图像生成控制框架,通过引入外部结构化信息作为条件输入,实现对生成图像的精准控制。它不仅解决了传统模型生成结果不可控的问题,更让AI绘画从“随机生成”转向了“按需定制”。
该技术通过构建额外的神经网络分支,将结构化控制信息与原始生成模型解耦,使创作者能够独立调整图像的布局、结构或特定元素,同时保持原始模型的美学风格。ControlNet能够兼容边缘图、深度图、法线图、人体关键点等多种条件输入,便于实现复合控制。而且,这套控制分支仅仅增加了约10%的计算开销。
在Stable Diffusion ComfyUI或WebUI中,ControlNet的工作流程可以分解为以下四个步骤:
- 步骤1:准备引导图像——原始图片经过预处理器处理,转换为边缘图、骨骼图、深度图等条件图
- 步骤2:提取条件特征——条件图通过ControlNet模型转换为条件特征向量
- 步骤3:注入扩散过程——条件特征在KSampler的每一步去噪中施加约束
- 步骤4:生成受控图像——扩散模型在每一步都被ControlNet的条件引导,最终输出同时符合提示词和条件约束的图像
ControlNet并不是一个“滤镜”,也不是“后处理”。它在扩散过程的每一步都在起作用,就像一位导演在整个拍摄过程中不断纠正演员的位置和动作,而不是拍完再修图。这种从像素级别上对生成过程进行精准约束的能力,正是ControlNet区别于其他工具的核心所在。
1.3 ControlNet的核心价值
| 维度 | 无ControlNet | 有ControlNet |
|---|---|---|
| 构图控制 | 全靠提示词描述,随机性大 | 用边缘图/涂鸦精确指定构图 |
| 姿态控制 | 提示词描述“双手叉腰”,但可能不生效 | 用OpenPose骨骼图精确控制每个关节 |
| 空间结构 | 难以控制前后景关系 | 用深度图保留精确的空间层次 |
| 风格迁移 | 提示词“转成油画风格”,构图可能走形 | Canny边缘约束构图+模型切换,风格转换不走形 |
通过以上维度对比,不难发现ControlNet的核心价值在于建立了一套可量化、可组合的控制体系,使创作者能够像操作专业设计软件那样去掌控AI的生成过程。
二、ControlNet核心参数体系详解
无论是姿态骨架控制还是深度图控制,理解ControlNet的核心参数设置都是入门的关键。这些参数决定了控制信号的强度和作用方式,是在控制精度与生成自由度之间找到平衡点的关键。
2.1 Control Mode:三种控制模式的选择
在ControlNet的主设置面板中,Control Mode(控制模式)提供三个选项:均衡模式、偏向提示词模式、偏向ControlNet模式。
- 均衡模式:在参考图结构与提示词内容之间取得折中。例如,参考图中包含不想要出现的元素时,均衡模式会保留部分特征但不会完全保留,也不会完全删除。
- 偏向提示词模式:优先遵循提示词指令。即使参考图不够精确,模型也能结合提示词来生成比较准确的图像。在需要进行大幅度画风转换时,该模式必不可少。
- 偏向ControlNet模式:严格遵循参考图的结构,尽最大努力保留参考图中的所有元素。
| 控制模式 | 适用场景 | 内容控制特点 | 风格控制特点 |
|---|---|---|---|
| 均衡 | 一般场景,默认选项 | 在保留与删除间折中 | 效果中等,可能混入参考图风格 |
| 偏向提示词 | 不同画风转换,修复参考图缺陷 | 偏向删除不希望出现的元素 | 效果最出色,可彻底切换风格 |
| 偏向ControlNet | 精准复刻,保留全部细节 | 倾向保留所有参考图元素 | 效果较差,强烈保留参考图特征 |
2.2 引导时机:控制介入与退出的节奏
引导时机是ControlNet控制中比较容易被忽视但实际上很重要的参数。该参数决定ControlNet在整个去噪过程中的何时介入、何时退出。当前采样步数固定后:
- 引导介入步数:对应采样过程的百分比值,设置为0.3表示从第30%的步数位置开始介入。当介入步数大于0.2时,整个构图就会发生非常大的变化。
- 引导退出步数:决定ControlNet在何时停止干预。退出步数的提前对控制程度的影响相对较小。
引导介入步数若设置为大于0.2,则会显著改变画面构图;引导退出步数的提前对控制程度的影响相对较小。通过精细调节介入与退出步数,可以为生成过程提供“初期临摹、后期润色”的空间。
2.3 控制权重:平衡约束与自由度
Control Weight(控制权重)决定了生成图像受ControlNet结构信号影响的强度。不同模型对权重的敏感度有所差异,但一般来说:
- 0.5-0.7:轻度约束,适合微调场景
- 0.8-1.2:标准约束,通用任务适用
- 1.3-1.5:强制约束,适合需要精细结构复刻的任务
- 大于1.8:强力驱动,可能使画面刻板生硬,一般不建议使用
在常见的Stable Diffusion 1.5与ControlNet的组合中,当权重值处于0.7-1.2范围内时,可保持较高的结构相似度。
2.4 预处理器分辨率与缩放模式
预处理器分辨率决定了预处理图的精细程度,默认512,数值越高线条越精细,越低则线条越粗略。Pixel Perfect模式勾选后,预处理图的分辨率会自动与目标图像的尺寸保持一致,从而确保画面细节表现比较理想。缩放模式用于调整预处理图与目标画布的匹配关系,包括拉伸、裁剪、填充等。
三、ControlNet环境搭建与基础配置
3.1 WebUI环境中的ControlNet配置
ControlNet的配置核心在于为预处理器和模型这两个核心单元建立正确的对应关系。预处理器负责将参考图像“翻译”为ControlNet可以理解的指令图;模型则是经过特殊训练的神经网络,专门学习如何处理某种特定类型的控制信号图。如果预处理后的信号类型与模型所训练的信号类型不够匹配,控制效果就可能不尽如人意。
因此,搭配的第一原则是:预处理器输出的信号类型,应与ControlNet模型所训练的信号类型严格匹配。
在WebUI中启用ControlNet的基本步骤如下:
- 在ControlNet面板中勾选“Enable”启用功能
- 将参考图像上传至ControlNet输入区域
- 在Control Type下拉菜单中选择对应的控制类型,系统将自动加载匹配的预处理器与模型
- 勾选“Allow Preview”预览预处理效果,确认生成的中间图正确反映了参考图的特征
- 设置Control Weight、Starting Control Step、Ending Control Step等参数
3.2 ComfyUI环境中的ControlNet工作流搭建
在ComfyUI中,ControlNet主要通过两个核心节点来实现:
- Load ControlNet Model:位于Loaders菜单,选择下载的.safetensors ControlNet模型文件
- Apply ControlNet:位于Conditioning菜单,接收正面条件、负面条件、ControlNet模型对象和预处理控制图像四个输入
节点连接时,Apply ControlNet会输出新的正负面条件值,取代KSampler原有的输入。模型文件需放置在ComfyUI/models/controlnet/目录下。ControlNet模型文件的命名通常能够反映出控制类型,如control_v11p_sd15_openpose.safetensors。
在ComfyUI的节点式工作流中,运用多个ControlNet并非简单的加法,而是一种可以连续传递的“接力跑”方式:第一棒ControlNet接入原始的Positive Prompt,输出经过它加工的条件数据;第二棒接收这一条件数据,叠加上自己的控制后再传递下去;以此类推,让生成图像同时受到多种控制力量的引导。
四、姿态骨架控制:OpenPose全攻略
4.1 OpenPose的技术原理
OpenPose是ControlNet生态中用于姿态控制的核心模型。它通过提取输入图像中的人体关键点坐标,将二维空间中的关节位置映射为骨架图,从而强制Stable Diffusion在扩散过程中严格遵循指定的姿态。OpenPose能够检测人体25个主要关节点,也可以扩展到检测每只手21个关节点和面部68个代表点位,较全面地还原人体动态。
OpenPose的核心能力在于将自然语言无法精确表述的动作描述(如“抬手”“转身”“坐下”“走路”等)转化为精确的骨骼坐标数据,使模型不再依赖模糊的文字想象,而是按照骨架图给出的关节坐标“看着画”。这在固定全身站姿、坐姿或处理手部遮挡等复杂动作时尤为实用。
4.2 预处理器类型与功能对比
OpenPose预处理器提供了从基础版本到全细节增强版本的多种配置。
| 预处理器 | 检测范围 | 关键点数量 | 适用场景 |
|---|---|---|---|
| openpose | 身体主要关节 | 18个 | 全身姿势控制,无须面部和手部细节 |
| openpose_face | 身体+面部 | 18+70=88个 | 需要控制面部表情的肖像场景 |
| openpose_hand | 身体+手部 | 18+42=60个 | 需要精确控制手部姿态的场景 |
| openpose_full | 身体+面部+手部 | 130个 | 需完整控制人物姿态、表情和手势的场景 |
| dw_openpose_full | 身体+面部+手部(增强) | 同Full | 手部姿势要求较高的专业场景 |
在ComfyUI中启用OpenPose的具体操作是:上传参考图,在ControlNet中启用OpenPose预处理器,系统会自动识别人物关节,生成骨架图。
dw_openpose_full是OpenPose的增强版本,采用升级后的算法处理复杂手势和透视变形,在手部细节还原能力上明显优于普通版本。从WebUI操作来看,控制类型选择openpose_full,预处理器和模型均选择对应的full版本,再勾选Pixel Perfect确保骨骼图尺寸与生成图一致。
4.3 姿态控制的三种主流方法
方法一:参考图驱动法
这是最直接也是最常用的方法,适用于已经拥有比较理想的姿态参考图(如舞蹈动作、特定站姿等照片)的场景。在WebUI的ControlNet面板中,将参考图上传至输入区域,Control Type选择openpose_full,勾选Allow Preview预览生成的骨架图,确认关键点识别是否准确。确认无误后将Control Weight设为1.0-1.2,Starting Control Step设为0(从第一步即开始强约束),在提示词框中输入目标人物的描述,生成新图像。
这种方法的优势在于无需手动调整骨骼,系统会自动完成从照片到骨架的转换。
方法二:OpenPose编辑器手工调整
当自动提取的骨架出现偏差、缺失关键点,或需要定制化夸张动作(如舞蹈动作、非人形角色)时,可以借助OpenPose Editor插件进行手动修正。在WebUI的Extensions菜单中安装sd-webui-openpose-editor插件后,顶部菜单栏会出现OpenPose Editor选项卡。进入编辑器界面,导入原始参考图,系统会自动生成初始骨架,使用鼠标点击并拖拽任意关节点进行调整。若需要强化手部细节,可以勾选Show Hand Joints,手动调整五指张开角度与朝向。
调整完成后点击Send to txt2img,骨架数据会自动载入ControlNet面板。此时ControlNet中的Preprocessor需设为none(因为骨架图已经手动处理完毕),Model仍为openpose模型,Weight保持为1.0。这一方法的控制粒度远超自动提取,尤其适合需要特定动作设计的场景。
方法三:用3D编辑器搭建自定义姿态
对于需要完全自创姿态而无法从任何参考图中获取的场景,可以采用OpenPose Editor的3D模式。在3D编辑界面中,用户可以操控一个3D人体模型,用鼠标将关节拖拽到所需的位置和角度,系统会自动生成对应的2D骨架图,再将其发送给ControlNet使用。这种方法特别适合分镜设计、动画姿态创作等需要精确控制动作路径的场景。
4.4 OpenPose进阶参数配置
在WebUI中完成OpenPose控制时,建议采用以下参数配置:Control Weight设为0.8-1.2之间,Starting Control Step设为0,Ending Control Step设为0.8-1.0(姿势骨架需要全程引导)。姿态提示词中需与骨架的动作保持一致,例如参考骨架图中人物站立时可写“a woman standing confidently”,模型仍会根据骨架图绘制姿势,提示词仅为细节补充。
五、深度图控制:建立空间的“骨架”
5.1 深度图控制的工作原理
如果说OpenPose是对二维平面上的动作形状进行控制,那么深度图控制则是对立体空间的布局进行约束。深度图本质上是一张用灰度值来表征物体与镜头距离的图像,纯白色代表离镜头最近,纯黑色代表最远,中间的灰度则对应空间中的各种纵深变化。
深度图控制的本质是通过深度信息约束模型对空间透视关系的理解,适用于室内设计、街景、建筑、景深较为明显的镜头等需要保持前后层次分明的场景。在人物与背景的分离处理上,借助深度图也可以有效改善图像中常见的前后景“粘连成贴纸”的问题。
深度图控制的核心价值在于:即便彻底改变图像的材质与风格,只要保留深度信息,空间中的远近关系和物体相对位置就不会发生变化。室内设计师可以借助这一能力,将一张毛坯房照片渲染成不同风格的精装修效果图,同时保证窗户位置和房间布局稳定不变。
5.2 深度图预处理器对比与选择
不同深度估计算法在处理不同类型图像时各有优劣,以下对三种常用的预处理器进行对比:
| 预处理器 | 核心算法 | 适用场景 | 特点 |
|---|---|---|---|
| depth_midas | MiDaS | 通用场景,室内/室外 | 通用性较好,平衡度适中 |
| depth_leres | LeReS | 室内场景、建筑、复杂空间 | 空间感表现较为细腻 |
| depth_zoe | ZoeDepth | 高精度需求、边缘细节丰富的场景 | 边缘锐利度较高,细节保留更优 |
在控制模型的选择上,推荐使用control_v11f1p_sd15_depth(对应SD1.5)或controlnet-depth-sdxl-1.0(对应SDXL),它们与上述预处理器可以较好地适配。
5.3 深度图控制实战操作
在ComfyUI中实现深度图控制的思路与OpenPose类似:加载原始图像,使用深度预处理器提取深度图,通过Apply ControlNet节点将控制信号注入生成管道。由于ComfyUI Core并不自带深度图预处理器,需要先安装ComfyUI ControlNet Auxiliary Preprocessors插件来获取深度估算能力。
在参数配置方面,深度图控制建议设置Control Weight为0.6-0.8之间,分辨率设置为768左右以保留更丰富的深度细节,Preprocessor resolution设为1以保持原始比例。在WebUI中,控制类型选择depth,系统将自动匹配对应的模型和预处理器。
5.4 深度图的进阶应用:景深与透视增强
深度图不仅是控制工具,其生成的深度图本身就是很有价值的信息源,可以导入到Photoshop、After Effects等专业后期软件中进行景深模糊、立体渲染等进一步处理。
- 景深效果生成:利用深度图作为蒙版,对画面远处施加高斯模糊,制造自然的景深效果
- 空间层次强化:将生成的深度图与原始图像叠加,通过亮度对比增强画面的立体感
- 3D信息提取:深度图的灰度值可以直接转换为位移数据,用于立体照片生成或简单3D视差动画
值得一提的是,深度图控制与OpenPose控制的组合是解决AI绘画中“坏手问题”的常用方法之一——OpenPose负责整体骨骼定位,深度图则补充Z轴空间信息,让前景肢体(例如正在遮挡脸的手)在纵深上压于面部之前,避免出现平面化的位置错位。
六、OpenPose与深度图协同:多重控制的进阶方案
6.1 为何需要多重控制
在电商或专业级的图像生成场景中,单一控制往往不够用:
- OpenPose:可以控制骨骼走向,但对人物胖瘦、手部细节的精细度以及身体的前后遮挡关系控制有限
- 深度图(Depth) :虽然能表现空间关系,但对五官和手指的精细度掌控不足
- Canny边缘:线条控制较为死板,容易把参考图中原有的纹理(如衣物的旧条纹)一并刻入新图像中
要解决“AI抽风”问题,比较有效的方案是构建一个OpenPose、Depth和Canny/Lineart三者协作的“控制铁三角”。三者在组合中各司其职:OpenPose负责大范围动作姿态(地基),Depth负责空间体积和透视关系(墙体结构),Canny负责微调轮廓,例如特定的手指弯曲度(精装细节)。三者协同工作,可以实现远超出单一控制单元的结构稳定性。
6.2 ComfyUI中的多重ControlNet串联
在ComfyUI中,多个ControlNet的串联使用需要将Apply ControlNet节点的条件以“接力”的方式连接:
- 第一棒(OpenPose) :接入原始的Positive Prompt,输出经过OpenPose修改的条件数据
- 第二棒(Depth) :接收OpenPose输出的条件数据,叠加上Depth深度约束,继续传递下去
- 第三棒(Canny/Lineart) :接收Depth的输出,完成最后一层控制,最终连接到KSampler
这样一来,AI在生成图像时会同时受到三种控制力的约束,大幅减少布局偏差。
6.3 终止步数的分层设置
在ControlNetApplyAdvanced节点中,Exit Step参数是生成效果自然与否的关键。很多新手虽然开启了多个ControlNet,但生成出的图像显得较为生硬、有贴片感,原因在于整个生成过程都被强约束着,缺乏后期让模型自由发挥细节的空间。经过多次实践验证的步数分层设置方案如下:
| 控制类型 | 建议End Step | 理由 |
|---|---|---|
| Canny/Lineart(强边缘) | 0.5-0.6 | 轮廓应早期固定,后期须释放以获取自然光影 |
| Depth(景深) | 0.6-0.8 | 空间结构中期可保有约束,后期适度放宽 |
| OpenPose(姿势) | 0.8-1.0 | 姿势骨架需要全程引导,确保动作准确 |
通过这样精细的步数分层,可以为AI留出“早期临摹、后期润色”的空间,既能确保构图的准确性,又能让图像的质感和光影在生成后期得以自然改善。
6.4 权重的分层配置
每个ControlNet单元的控制权重也需要根据它在组合中的角色进行差异化设置:
- OpenPose(结构骨架) :权重设为较高值(0.9-1.0),确保动作骨架被严格遵循
- Depth(空间层次) :权重设为中等偏高值(0.7-0.9),保障透视关系的准确性
- Canny/Lineart(细节轮廓) :权重设为中等偏低值(0.6-0.8),用于微调而不至于扭曲新内容
这样的权重配置可以在保证核心结构的基础上,保留足够的新内容生成空间。
七、八大控制类型全景:从基础到扩展
尽管本文聚焦于姿态骨架与深度图控制,但ControlNet的完整能力远不止于此。以下将简要介绍八个主要控制类型的核心功能与适用场景,以便读者根据具体任务灵活选用:
| 控制类型 | 技术原理 | 适用场景 | 关键预处理器 |
|---|---|---|---|
| OpenPose(姿态) | 人体25个关键点检测 | 舞蹈动作、角色姿态固定 | openpose_full / dw_openpose_full |
| Depth(深度) | 单通道深度估计算法 | 室内设计、空间布局、景深场景 | depth_midas / depth_leres / depth_zoe |
| Canny(边缘) | 双阈值边缘检测 | 产品设计、建筑轮廓、硬件结构 | canny |
| HED(软边缘) | 整体嵌套边缘检测 | 保留草图手绘感、艺术创作 | hed |
| Scribble(涂鸦) | 简单线条引导 | 草图变成品、快速创意表达 | scribble |
| MLSD(直线) | 直线段检测 | 建筑渲染、工业设计 | mlsd |
| Normal(法线) | 表面法线贴图 | 3D材质控制、光照效果 | normal_bae / normal_midas |
| Segmentation(分割) | 语义分割 | 分区域精准控制 | seg_ofade20k / seg_ofcoco |
在ControlNet的使用过程中,掌握上述各种控制类型的特点,并能够根据具体任务灵活切换与组合,是进阶创作的关键一步。
八、实战案例与工作流
案例一:电商模特姿态精准克隆
需求:参照某张模特照片的站姿,将服装替换为自家新款产品,同时确保手势自然。
控制方案:
- 将参考图上传到ControlNet单元,选择dw_openpose_full预处理器,提取含手部关键点的完整骨架
- 启用第二个ControlNet单元,控制类型选择Canny,对图像轮廓进行补充约束
- OpenPose单元权重设为0.9-1.0,Canny单元权重设为0.6-0.7
- 在正向提示词中详细描述新服装的材质、颜色和款式
采用此方案后,新生成的模特将严格遵循参考图的头身比和姿态,手指姿态保持自然,衣物纹理也不会被原图的旧条纹所干扰。
案例二:室内设计风格快速迭代
需求:将一张毛坯房照片渲染为现代风格精装修客厅,同时保持窗户、门框等结构的位置不变。
控制方案:
- 控制类型选择Depth,预处理器选depth_midas,提取空间深度信息
- Control Weight设为0.9,Preprocessor resolution设为768,以保留丰富的空间细节
- 正向提示词中描述目标装修风格(如“modern style, hardwood floor, minimalistic”)
- 配合Canny边缘控制来锁定建筑轮廓边界
该方案能够在严格保持空间布局的前提下,自由变换材质与装饰风格。
案例三:角色多动作序列生成
需求:保持角色脸部特征、服装风格一致的前提下,生成多种不同的动作姿态。
控制方案:
- 将角色的基准头像作为Reference参考图锁定面部特征
- 分别导入或手动绘制多个不同姿态的OpenPose骨架图
- 固定相同的随机种子和基础提示词
- 批量生成多批次图像,确保角色一致性
这一方案在动画分镜设计、游戏角色动作库构建等场景中能有效保证角色的稳定统一。
九、常见问题与避坑指南
Q1:ControlNet预处理后生成的骨架图不准怎么办?
先检查参考图的质量,选择光线均匀、四肢无大面积遮挡的照片。如果自动提取的结果依然不准确,可使用OpenPose Editor手动拖拽校准关节点。校准后将Preprocessor设为None(因为此时输入的已经是手工校正后的骨架图),Model仍选用OpenPose模型,即可正常生成。
Q2:开启ControlNet后生成图像过于刻板,像贴纸一样怎么办?
这是由于全程强制控制导致的。在多个ControlNet启用时,注意精细调节Ending Control Step——Canny早一点退出(如0.5-0.6),Depth中期退出(0.6-0.8),OpenPose全程持续到1.0。这样可以为AI留出后期自然修饰的空间。
Q3:如何解决手部扭曲问题?
建议使用双ControlNet协同方案:OpenPose控制整体骨架,Depth控制空间纵深关系,让前景肢体(如正在遮挡脸部的手)在深度信息上明确压于面部之前,避免手脸错位。也可在正向提示词中加入“detailed hands”等描述,配合负面提示词中的“bad hands, mutated fingers”等加以约束。
Q4:ComfyUI和WebUI哪个更适合ControlNet高级控制?
ComfyUI的优势在于节点式工作流的灵活性和精细的可控性,尤其适合多重ControlNet串联和自定义参数配置。WebUI则对新手更为友好,社区插件丰富,适合快速上手。专业量产建议选择ComfyUI,实验性探索可用WebUI。
Q5:不同Stable Diffusion版本对ControlNet的支持有何差异?
ControlNet最初为SD1.5开发,生态最为完备。SDXL可以通过ControlNetXL(CNXL)获得支持。最新的SD3.5已经推出了官方的ControlNets,包括Blur、Canny和Depth三种类型,目前仅与SD3.5 Large(8B)兼容,未来将逐步支持其他版本。FLUX.1方面,已推出Controlnet-Union Pro版,单模型原生支持Canny、Depth、Pose、Scribble等7种控制模式的融合,且在控制模式切换耗时和多模态融合控制精度上显著优于传统方案。
Q6:ControlNet权重过高导致画面畸形如何解决?
尝试以下步骤:将Control Weight下调至0.6-0.8范围;检查是否给模型分配了匹配的控制类型(例如用Depth模型配Canny预处理器会导致效果不稳定);适当降低ControlNet的结束步数,给后期更多自由度。
Q7:多ControlNet组合使用时权重如何分配?
推荐按控制层级分配:OpenPose高权重(0.9-1.0),Depth中等偏高(0.7-0.9),Canny中等偏低(0.6-0.8)。分工逻辑是姿态骨架全程强约束,空间结构中期约束,轮廓细节前期约束后尽早退出。
Q8:深度图控制和Canny边缘检测有什么区别?
深度图控制基于灰度深度图约束空间透视关系,确保近大远小的物理合理性;Canny边缘检测则提取图像轮廓,强约束结构线条。两者配合使用时,深度控制全局空间,边缘控制细节轮廓,达到互补效果。