

马斯克透露Grok 4.5最新进展:已在SpaceX、特斯拉内部测试,AI Coding能力再升级


马斯克再次放出关于 Grok 的最新消息
2026年6月28日,他在 X 平台表示,Grok 4.5 已进入 SpaceX 和特斯拉内部 Beta 测试阶段。虽然新模型尚未正式向公众开放,但已经开始在真实业务环境中接受验证。

马斯克X推文
更引人关注的是,马斯克表示,早期内部测试显示,Grok 4.5 的整体表现已经接近,甚至有望超过 Anthropic 的 Claude Opus。不过,目前这一结论主要来自内部评测,第三方公开基准测试结果尚未公布。
那么,Grok 4.5 到底升级了什么?这次内测又释放了哪些值得关注的信号?
Grok 4.5 为什么值得关注?
相比以往发布新模型,这一次最大的不同在于,Grok 4.5 并没有直接开放给所有用户,而是首先部署到 SpaceX 和特斯拉内部进行测试。
这意味着,它面对的不再是实验室里的标准测试题,而是真实的工程研发环境。
无论是软件开发、技术文档分析,还是复杂的工程计算,这些真实业务场景都比公开 Benchmark 更能验证模型的实际能力。如果能够在企业内部稳定运行,对于后续正式发布也会更有参考价值。
重点强化编程与工程能力
从目前公开的信息来看,Grok 4.5 的训练重点之一,是进一步提升代码理解和技术推理能力。
马斯克透露,新模型在补充训练阶段加入了大量开发工作流相关数据,并持续优化强化学习(RL)训练流程。同时,xAI 内部的编程 Agent 系统也在同步迭代,希望进一步提升模型在软件开发场景中的表现。
过去一年,AI 大模型竞争已经逐渐从聊天转向干活。
从 OpenAI 推出的 Codex、Anthropic 持续优化 Claude Code,到 Google 推进 Gemini Coding,如今 xAI 也开始明显加码 AI Coding,这意味着编程助手已经成为各家模型竞争的重要方向。
1.5 万亿参数意味着什么?
根据马斯克公布的信息,Grok 4.5 基于约 1.5 万亿参数的基础模型训练完成。需要说明的是,参数规模并不直接等于模型能力。
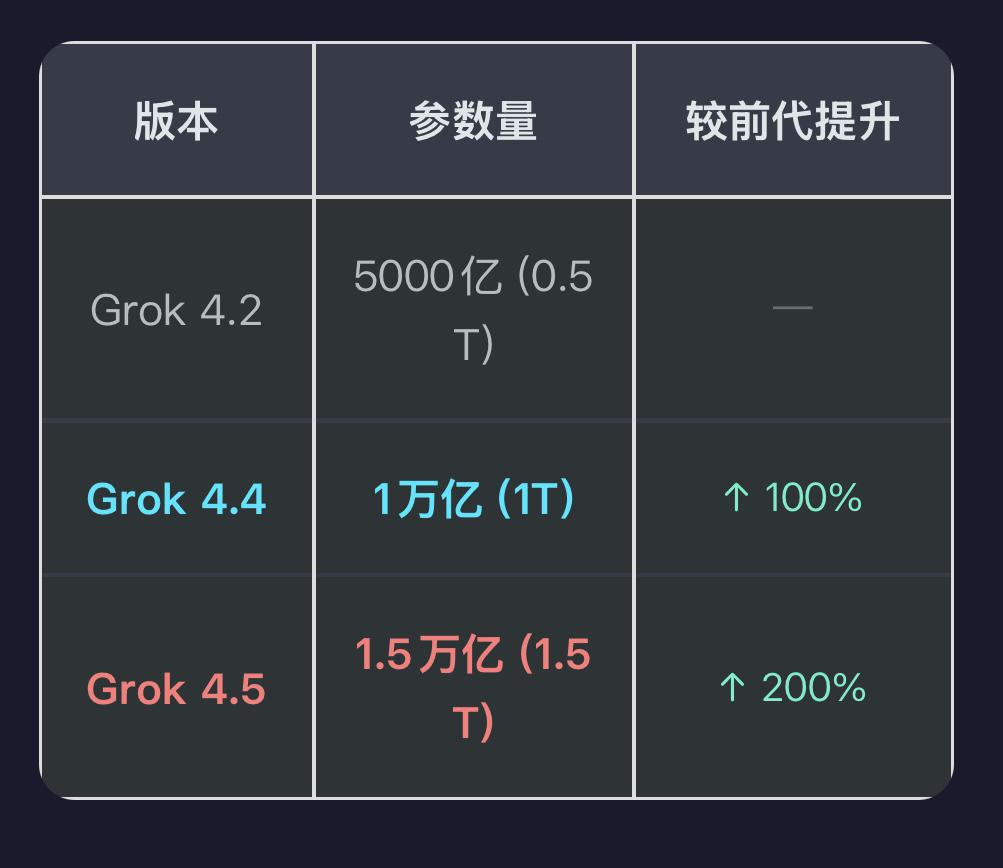
近年来,大模型的发展已经证明,数据质量、训练方式、推理能力以及强化学习,同样会影响最终效果。因此,参数增长更多意味着模型拥有更大的潜力,而不是简单代表性能一定更强。
真正值得关注的,还是模型在真实任务中的表现。
对标 Claude Opus,意味着什么?
马斯克此次多次提到 Claude Opus。

Claude 一直被认为是目前编程、长文本理解以及复杂推理能力较强的大模型之一,因此将其作为对比对象,也意味着 xAI 希望进入高端 AI 模型竞争。
不过,目前超过 Claude Opus这一说法仍然来自内部测试结果,是否能够在公开评测和实际应用中保持优势,还需要等待正式发布后的更多数据验证。
对于开发者来说,真正重要的不是跑分,而是模型能否提高日常工作的效率。
AI 大模型竞争,正在进入新的阶段
过去,大模型厂商更多关注参数规模、排行榜成绩以及基准测试。而现在,越来越多企业开始把模型部署到真实业务中验证能力。
OpenAI 持续强化企业办公能力,Anthropic 深耕开发者市场,Google 推进 Gemini 在办公生态中的应用,xAI 则选择先在 SpaceX 和特斯拉内部完成测试。
这说明,大模型竞争已经逐渐从谁更聪明转向谁更能解决真实问题。
未来,AI Agent、AI Coding、企业知识库、自动化研发等方向,或许会成为下一阶段的重要竞争焦点。
我的观察
相比参数规模,我更关注 Grok 4.5 的落地方向。
如果 xAI 后续持续强化编程、工程研发和 Agent 能力,那么它真正竞争的对象,可能不仅仅是 Claude Opus,而是整个 AI 开发者生态,包括各种 AI 编程助手和开发工具。
对于 AI 创作者和开发者来说,这也是一个值得关注的趋势:未来的大模型,比拼的不只是聊天体验,而是谁能真正融入工作流,帮助用户完成内容创作、软件开发和企业协作。
随着 Grok 4.5 正式发布,这场围绕 AI Coding 与智能 Agent 的竞争,或许还会进一步升温。
