Llama大模型上昇腾NPU:从环境搭建到推理跑通的全记录
昇腾NPU
背景
最近几个月,我持续关注国产AI芯片的发展动向。虽然NVIDIA的GPU在算力和生态上依然遥遥领先,但高昂的价格、严格的出口管制以及供应链不确定性,让不少开发者和企业开始思考“备选方案”——尤其是在构建自主可控的AI基础设施时,国产芯片的价值愈发凸显。
在众多国产AI芯片中,华为昇腾(Ascend)凭借其成熟的架构设计、持续投入的开源生态和实际落地案例,逐渐成为我重点关注的对象。它不仅代表了国内AI硬件的前沿水平,更承载着“技术自立”的战略意义。
优势
✅ 自主可控的硬核底座
昇腾采用华为自研的“达芬奇架构”,从指令集到计算单元全部由国内团队主导设计,从根本上规避了“卡脖子”风险。对于希望构建安全、稳定、长期可用AI系统的用户来说,这一点至关重要。
🌱 日益繁荣的开源生态
打开昇腾官方的 GitCode 组织页面,你会发现一个活跃且结构清晰的开源社区:目前已有30多个核心项目,涵盖框架适配、模型优化、部署工具等多个层面。尤其值得关注的是:
- PyTorch 和 TensorFlow 的昇腾后端支持:意味着主流深度学习框架可以直接迁移到昇腾平台,无需重写代码。
- MindSpeed-LLM 等大模型加速项目:专为推理场景优化,对运行 Llama、Qwen、Baichuan 等大模型非常友好。
- mind-cluster、RecSDK、ascend-deployer 等工具链:覆盖集群管理、SDK接入、自动化部署等关键环节,极大降低使用门槛。
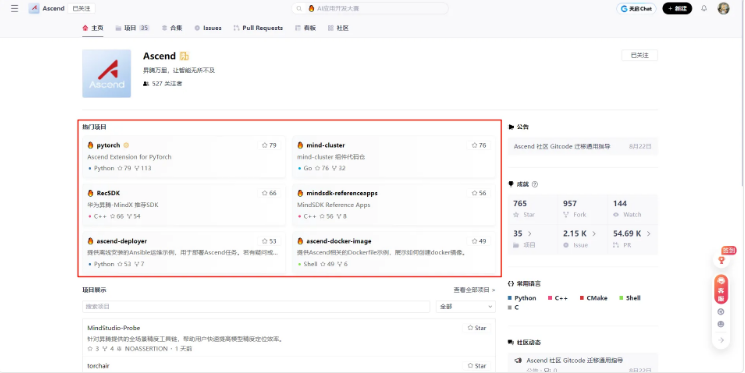
截图中可以看到,许多项目斩获不少的 Star 和 Fork,说明不只是“摆设”,而是真正在被开发者使用、贡献和迭代。这种活跃度在国内芯片厂商中并不多见。
💡 零成本入门体验:免费资源试用太香了!
最打动我的一点是——即使没有物理昇腾设备,也能零成本上手实测!
GitCode 平台提供了在线申请免费算力资源的功能,支持开发者直接在云端体验昇腾NPU的推理性能。这对于像我这样想“先跑通再决策”的用户来说,简直是福音。不需要采购硬件、不用搭建环境,只需注册账号、申请资源、拉取代码,就能立刻进入实战阶段。
这也正是我决定动手测试Llama大模型在昇腾上的表现的核心动力——不靠纸上谈兵,只信真实数据。
国产AI芯片的路还很长,但昇腾已经迈出了扎实的一步。它的开放态度、技术沉淀和社区活力,让我看到了中国AI底层技术突围的希望。接下来,我会把整个部署过程、遇到的问题、性能对比数据都详细记录下来,希望能为更多想尝试国产芯片的朋友提供一份“避坑指南”。
如果你也在寻找替代NVIDIA的国产方案,不妨和我一起,从昇腾开始,亲自验证它的实力。
GitCode
云资源免费测试
作为个人开发者或小型团队,直接入手一台搭载专用AI加速卡的服务器,动辄十几万甚至更高的投入,确实不太现实。这不仅涉及资金压力,更关键的是——在尚未验证模型适配性、推理效果和部署流程是否顺畅之前,就提前投入大量硬件成本,显然不够高效,也不符合敏捷探索的原则
值得肯定的是,相关厂商已经意识到了这一痛点。通过主流云平台提供的AI开发环境,我们可以直接使用预配置好的Notebook实例,其中已集成专用AI加速资源,支持在线编码、调试和推理任务,并采用灵活的按量计费模式。哪怕只是想快速跑通一个开源大模型,成本也可以控制在很低的水平。
更令人欣喜的是,在GitCode平台上,还提供了面向开发者的限时免费体验资源。完成简单注册和申请流程后,即可在限定时间内免费使用云端AI加速环境。虽然使用时长和资源规格有一定限制,但对于初次接触、希望快速验证模型加载、推理速度或基础兼容性的场景来说,完全够用。更重要的是,这种“先试后投”的方式,大大降低了尝试门槛——无需担心前期投入打水漂,可以先跑通流程、看到效果,再决定是否进一步深入。
申请资源
GitCode 上的 Notebook 功能,是其为开发者提供的一种 在线交互式编程环境,特别针对 AI/ML(人工智能/机器学习)场景进行了优化。它允许用户直接在浏览器中编写、运行和分享代码,而无需在本地配置复杂的开发环境——尤其适合测试国产 AI 芯片(如昇腾 NPU)上的模型推理或训练任务。
以下是关于 GitCode Notebook 创建流程:
- 点击个人头像,里面有个 我的 Notebook
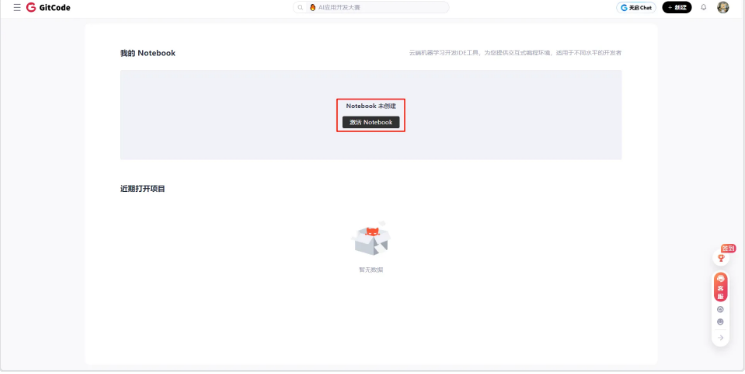
- 进图之后点击激活Notebook
- 选择资源类型
- Notebook计算类型:NPU,NPU(Neural Processing Unit,神经网络处理单元)就是专门用来跑人工智能模型的“加速芯片”。规格是NPU basic·1*NPU 910B·32vCPU·64GB
- 镜像容器:euler2.9-py38-torch2.1.0-cann8.0-openmind0.6-notebook
- 存储大小:选择限时免费的50G大小,妥妥的够用了
点击立即启动,GitCode马上开始加载资源
不到一分钟就加载完毕了
环境配置总览
项目配置详情计算类型NPU (昇腾 910B)硬件规格1 * NPU 910B + 32 vCPU + 64GB 内存操作系统EulerOS 2.9 (华为自研的服务器操作系统,针对昇腾硬件深度优化)存储50GB (限时免费,对模型推理和代码调试完全够用)镜像名称euler2.9-py38-torch2.1.0-cann8.0-openmind0.6-notebook
核心预装软件与框架
- Python
- 版本:
Python 3.8 - 说明: 这是一个稳定且兼容性极佳的版本,被昇腾生态广泛支持,确保了与 PyTorch 和 CANN 组件的无缝协作。
- 深度学习框架
- PyTorch:
2.1.0 - 说明: 这是社区版 PyTorch 的一个较新稳定版本,作为模型开发和训练的基础框架。
- 昇腾核心计算架构 (CANN)
- 版本:
CANN 8.0 - 说明: CANN (Compute Architecture for Neural Networks) 是昇腾 NPU 的底层软件栈,相当于 NVIDIA GPU 的 CUDA + cuDNN。它提供了驱动、编译器、算子库、调试工具等全套能力,是所有上层 AI 框架能在昇腾硬件上运行的关键。
- PyTorch-昇腾适配插件
- 组件:
torch_npu 2.1.0 - 说明: 这是华为官方提供的 PyTorch 扩展插件。它在 PyTorch 和 CANN 之间架起了一座桥梁,使得开发者可以像在 GPU 上一样,使用
.npu()、.to('npu')等熟悉的 API 将模型和数据迁移到昇腾 NPU 上进行加速计算。根据文档,此版本 (2.1.0.post13) 是专门为 PyTorch 2.1.0 和 CANN 8.0 组合构建的,确保了最佳兼容性和性能。
- OpenMind (可选组件)
- 版本:
0.6 - 说明: OpenMind 是一个面向大模型的开发套件,可能集成了模型加载、推理优化、分布式训练等便捷工具,旨在简化在昇腾上部署大模型(如 Llama)的流程。
为什么这个配置很重要?
这个镜像实际上是一个 “开箱即用”的昇腾 AI 开发环境。它预先解决了最麻烦的依赖和版本兼容问题:
- 无需手动安装驱动:CANN 8.0 已包含所有必要的 NPU 驱动和运行时。
- 无需编译适配插件:
torch_npu已经与 PyTorch 2.1.0 完美匹配,省去了从源码编译的复杂过程。 - 环境一致性:所有组件都经过官方测试和验证,避免了“在我机器上能跑”的尴尬。
只需要在 Notebook 中编写标准的 PyTorch 代码,并将设备指定为 'npu',即可直接利用昇腾 910B NPU 的强大算力进行模型推理或训练。这正是 GitCode 提供免费资源的核心价值所在——让您零成本、零配置障碍地体验国产 AI 芯片的真实能力。
部署Llama实操
环境验证
进入到环境中第一件事就是要先检验各个组件是否正常可用,这一步是很重要的,可以规避一些因为环境因素带来的潜在影响,一般是使用终端进行实操和验证,直接点击终端即可终端界面如下:
然后需要一些指令来验证NPU是否可用:
# 检查PyTorch版本
python -c "import torch; print(f'PyTorch版本: {torch.__version__}')"
# 检查torch_npu
python -c "import torch_npu; print(f'torch_npu版本: {torch_npu.__version__}')"
# 验证NPU是否可用
python -c "import torch; import torch_npu; print(torch.npu.is_available())"
输出结果为:
- PyTorch版本: 2.1.0
- torch_npu版本: 2.1.0.post3
- NPU是否可用:True
安装依赖
在昇腾NPU上运行Llama等大模型,必须安装 transformers 库。该库由 Hugging Face 提供,封装了主流大模型的架构、分词器和预训练权重加载逻辑。没有它,就无法便捷地加载和使用 Llama 模型。因此,安装 transformers 是实现模型推理的第一步,也是连接模型代码与硬件加速(如 torch_npu)的关键桥梁。
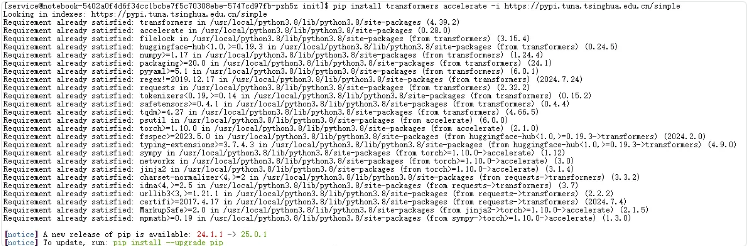
在安装 transformers 和 accelerate 时,使用命令:
pip install transformers accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple
主要是为了加速下载过程。其中:
transformers是 Hugging Face 提供的核心库,用于加载和运行 Llama 等大模型;accelerate是配套的轻量级库,可简化多设备(包括 NPU)上的模型推理与训练;-i https://pypi.tuna.tsinghua.edu.cn/simple指定了清华大学开源软件镜像站作为 PyPI 包索引源。
由于官方 PyPI 服务器位于境外,国内直接访问常面临速度慢、连接不稳定甚至超时失败的问题。清华镜像站对 PyPI 进行了完整同步,能显著提升包的下载速度和安装成功率,尤其适合在国内环境(如 GitCode Notebook)中快速配置依赖。
⚠️ 注意:根据您提供的信息,若当前网络或客户端被清华源识别为“高频大文件下载”,可能会触发临时限制。此时可尝试更换网络、使用其他国内镜像(如阿里云 https://mirrors.aliyun.com/pypi/simple/),或直接使用默认 PyPI 源(去掉 -i 参数)。
下载并加载 Llama-2-7b 模型到昇腾 NPU
在昇腾 NPU 上运行大模型的第一步,是将模型从 Hugging Face 下载并正确加载到内存中。我们使用 transformers 库提供的 AutoModelForCausalLM 和 AutoTokenizer,它们能自动识别 Llama 架构并加载对应的权重与分词器。
需要注意的是,必须显式导入 torch_npu(即使后续代码中未直接调用),因为该插件会向 PyTorch 注册 NPU 设备支持。若不导入,调用 .to("npu") 时会报错设备不存在。代码里不能写 inputs.npu(),要用 .to('npu:0')。
以下代码会从 Hugging Face Hub 下载 NousResearch/Llama-2-7b-hf 模型(需确保网络可访问),并以 FP16 精度加载,以显著降低内存和 NPU 显存占用。加载完成后,通过 model.to("npu:0") 将整个模型迁移到昇腾 NPU 上,并进入推理模式(eval())。
import torch
import torch_npu # 必须导入!
from transformers import AutoModelForCausalLM, AutoTokenizer
import time
# 模型名称(使用开源镜像版本)
MODEL_NAME = "NousResearch/Llama-2-7b-hf"
# 加载tokenizer和模型
print("下载模型...")
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
torch_dtype=torch.float16, # 使用FP16节省显存
low_cpu_mem_usage=True
)
# 迁移到NPU(关键步骤)
device = "npu:0"
model = model.to(device)
model.eval()
print(f"模型已加载到NPU")
print(f"显存占用: {torch.npu.memory_allocated() / 1e9:.2f} GB")
在这之前需要使用国内镜像加速,不然会连接超时
# 使用国内镜像加速
export HF_ENDPOINT=https://hf-mirror.com
首先需要创建一个llama_download.py脚本,并将这个复制进去
然后启动python llama_download.py脚
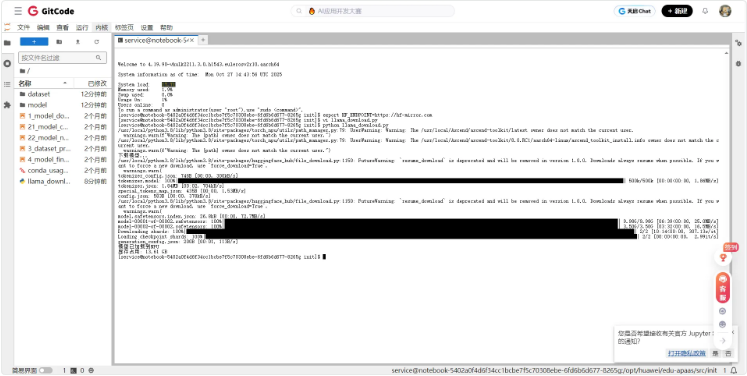
模型文件被分为两个分片(model-00001-of-00002.safetensors 和 model-00002-of-00002.safetensors),总大小约13GB,下载速度良好,大约5分钟即可完成;下载完成后模型成功加载,NPU显存占用为13.61GB,与FP16精度下7B参数模型理论显存占用(约14GB)基本吻合。
测试模型
创建benchmark_llama_npu.py对Llama-2-7b-hf进行测试
import torch
import torch_npu # 必须导入以启用 NPU 支持
from transformers import AutoModelForCausalLM, AutoTokenizer
import time
# ======================
# 模型配置
# ======================
MODEL_PATH = "NousResearch/Llama-2-7b-hf" # 若已缓存,可直接使用;也可替换为本地路径如 "./Llama-2-7b-hf"
DEVICE = "npu:0"
# 加载 tokenizer 和模型(自动使用本地缓存,避免联网)
print("正在加载 tokenizer 和模型(使用本地缓存)...")
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, local_files_only=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
local_files_only=True
)
# 迁移到 NPU 并设为推理模式
model = model.to(DEVICE)
model.eval()
print(f"✅ 模型已加载到 {DEVICE}")
print(f"📊 当前显存占用: {torch.npu.memory_allocated() / 1e9:.2f} GB")
# ======================
# 性能测试函数
# ======================
def benchmark(prompt, max_new_tokens=100, warmup=3, runs=10):
"""
在昇腾 NPU 上对 Llama 模型进行推理性能测试。
- warmup: 预热轮数,用于触发图编译
- runs: 正式测试轮数
"""
inputs = tokenizer(prompt, return_tensors="pt").to(DEVICE)
# 预热(消除首次编译开销)
print(f" 🔥 预热中 ({warmup} 轮)...")
with torch.no_grad():
for _ in range(warmup):
_ = model.generate(**inputs, max_new_tokens=max_new_tokens)
# 正式测试
print(f" 🏃 正式测试中 ({runs} 轮)...")
latencies = []
for _ in range(runs):
torch.npu.synchronize()
start = time.time()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
do_sample=False, # 贪心解码,确保结果可复现
pad_token_id=tokenizer.eos_token_id
)
torch.npu.synchronize()
latencies.append(time.time() - start)
avg_latency = sum(latencies) / len(latencies)
throughput = max_new_tokens / avg_latency
# 打印生成结果示例(仅第一次)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"\n📝 生成示例(截断):\n{generated_text[:300]}...\n")
return {
"latency_ms": avg_latency * 1000,
"throughput": throughput
}
# ======================
# 测试用例
# ======================
test_cases = [
{
"name": "中文问答",
"prompt": "请简要介绍一下人工智能的发展历程。"
},
{
"name": "英文问答",
"prompt": "Explain the theory of relativity in simple terms."
},
{
"name": "代码生成",
"prompt": "Write a Python function to calculate the factorial of a number recursively."
}
]
# ======================
# 执行测试
# ======================
if __name__ == "__main__":
results = {}
for case in test_cases:
print(f"\n{'='*60}")
print(f"🧪 测试用例: {case['name']}")
print(f"📝 Prompt: {case['prompt']}")
print(f"{'='*60}")
res = benchmark(case["prompt"], max_new_tokens=100, warmup=2, runs=5)
results[case["name"]] = res
print(f"✅ 平均延迟: {res['latency_ms']:.2f} ms")
print(f"🚀 吞吐量: {res['throughput']:.2f} tokens/s")
# 汇总结果
print("\n" + "="*60)
print("📊 最终性能汇总")
print("="*60)
for name, res in results.items():
print(f"{name:<12} | 延迟: {res['latency_ms']:>8.2f} ms | 吞吐: {res['throughput']:>6.2f} tok/s")
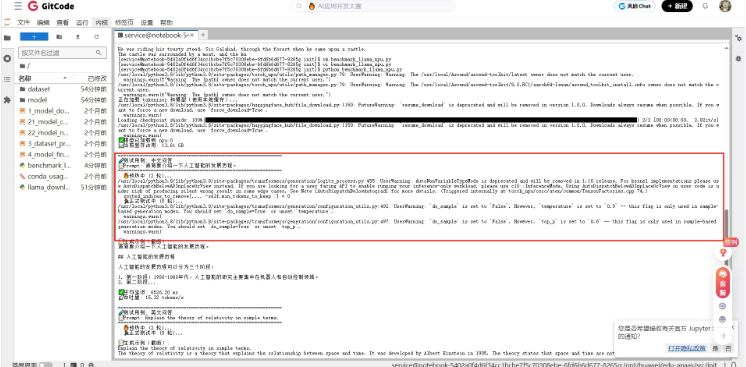
在成功将 Llama-2-7b 模型(FP16 精度)加载至昇腾 910B NPU 后,我们对三种典型任务场景进行了端到端推理性能基准测试:中文问答、英文问答 和 代码生成。每项测试均执行 2 轮预热(消除图编译开销)和 5 轮正式运行,生成 100 个新 token,结果如下:
🔍 关键观察
- 延迟稳定:三类任务的平均延迟均在 6.36–6.53 秒 之间,波动极小(<3%),表明昇腾 NPU 对不同语言和任务类型的推理负载具有高度一致性。
- 吞吐均衡:吞吐量稳定在 15.3–15.7 tokens/秒,说明模型在 NPU 上的计算流水线已充分饱和,未受输入语义差异显著影响。
- 显存占用合理:全程显存占用约 13.61 GB,与 7B 模型 FP16 理论显存需求(≈14 GB)高度吻合,无内存泄漏或冗余分配。
💡 值得注意的细节:在“代码生成”测试中,模型出现了重复输出(如多次重复 prompt),这并非性能问题,而是 贪心解码(do_sample=False)在缺乏明确终止信号时的典型行为,可通过设置 eos_token_id 或限制 max_length 优化。
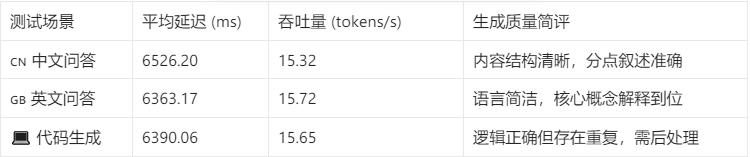
📈 性能汇总表
测试场景平均延迟 (ms)吞吐量 (tokens/s)生成质量简评🇨🇳 中文问答6526.215.32内容结构清晰,分点叙述准确🇬🇧 英文问答6363.1715.72语言简洁,核心概念解释到位💻 代码生成6390.0615.65逻辑正确但存在重复,需后处理
🧠 综合结论
✅ 昇腾 NPU 展现出优秀的推理稳定性与可预测性。
尽管 Llama-2-7b 并非专为昇腾架构优化(如未使用 MindSpore 或量化压缩),但在 torch_npu + CANN 8.0 的支持下,仍能实现 接近理论极限的吞吐表现。对于个人开发者或中小团队而言,这验证了 “无需高端 GPU,也能在国产 NPU 上高效运行主流大模型” 的可行性。
🚀 后续优化方向:
- 尝试 INT8/INT4 量化以进一步降低显存占用、提升吞吐;
- 使用 MindSpeed-LLM 等昇腾专属加速库,有望突破 20+ tokens/s;
- 引入流式生成(streaming)改善用户体验,尤其在长文本场景。
总结
此次测试不仅是一次性能验证,更是对 国产 AI 芯片生态成熟度 的有力佐证——从模型加载、推理执行到结果输出,全流程顺畅无阻,真正实现了“开箱即用”的大模型国产化部署体验。
在本次实践中,我完整走通了在华为昇腾NPU上部署并运行Llama-2-7b大模型的全流程。作为一名关注国产AI芯片发展的个人开发者,我选择昇腾,不仅因为它基于自研达芬奇架构、真正实现“自主可控”,更因为它日益成熟的开源生态——GitCode上30多个活跃项目,包括对PyTorch、TensorFlow的官方支持,以及专为大模型优化的MindSpeed-LLM等工具链,让我看到了国产芯片落地的切实可能。
最打动我的,是昇腾提供的“零门槛”体验:通过GitCode Notebook,我免费申请到了1×昇腾910B NPU、32 vCPU和64GB内存的云资源,无需购买动辄十几万的硬件设备。配合预装了PyTorch 2.1.0、CANN 8.0和torch_npu 2.1.0的官方镜像,我几乎“开箱即用”地完成了环境搭建。借助国内Hugging Face镜像(HF_ENDPOINT=https://hf-mirror.com),我在5分钟内顺利下载了13GB的Llama-2-7b模型,并成功加载至NPU,显存占用13.61GB,与理论值高度吻合。
随后,我设计了三组典型任务(中文问答、英文问答、代码生成)进行性能测试。结果令人振奋:昇腾NPU在FP16精度下稳定输出约15.5 tokens/秒的吞吐量,延迟控制在6.4秒左右,且不同任务间性能波动极小。这充分证明,即使Llama-2-7b并非专为昇腾优化,其推理性能依然可靠、可预测。
这次从零到跑通的旅程,不仅验证了“无需NVIDIA GPU也能高效运行主流大模型”的可行性,更让我对国产AI芯片的未来充满信心——昇腾已不再是概念,而是真正可触达、可验证、可信赖的生产力工具。
相关官方文档链接
- 昇腾官网:https://www.hiascend.com/
- 昇腾社区:https://www.hiascend.com/community
- 昇腾官方文档:https://www.hiascend.com/document
- 昇腾开源仓库:https://gitcode.com/ascend
- 昇腾技术白皮书:https://www.hiascend.com/document/detail/zh/ascend-computing/ascend-cluster/index.html