CANN算子开发实战:从概念到代码完整指南
昇腾CANN训练营第二季火热进行中!这是一场不容错过的AI技术盛宴,提供从零基础到高级实践的全套课程体系。无论你是刚入门的开发者,还是经验丰富的工程师,都能在这里找到适合自己的学习路径。立即报名参加,与万名开发者一起探索昇腾AI的无限可能!
算子是深度学习框架的基础构成单元,负责执行特定的计算任务。随着AI应用的快速发展,对高性能算子的需求日益增长。华为昇腾CANN(Compute Architecture for Neural Networks)提供了一个强大的算子开发平台,让开发者能够充分利用昇腾硬件的计算能力。
CANN算子开发的核心优势包括:
- 硬件原生优化:直接利用昇腾AI处理器的计算单元
- 高性能执行:通过专门的优化实现极致性能
- 开发便利性:提供丰富的开发工具和库支持
- 生态集成:与主流深度学习框架无缝集成
- CANN算子基础概念
2.1 算子定义与分类
在CANN架构中,算子是执行特定计算任务的基本单元。根据功能特点,可以分为以下几类:
基础数学算子:
- 算术运算:加法、减法、乘法、除法
- 线性代数:矩阵乘法、向量运算、张量操作
- 数学函数:三角函数、指数对数、激活函数
神经网络算子:
- 卷积操作:1D、2D、3D卷积
- 池化操作:最大池化、平均池化
- 归一化:批归一化、层归一化
- 激活函数:ReLU、Sigmoid、Tanh
图像处理算子:
- 变换操作:缩放、旋转、裁剪
- 滤波操作:高斯滤波、边缘检测
- 颜色空间转换:RGB、HSV、YUV
2.2 算子执行流程
CANN算子的执行遵循标准的流程,确保计算的正确性和效率:

关键步骤说明:
- 参数验证:检查输入参数的合法性和一致性
- 内存分配:为计算过程中需要的数据分配内存空间
- 数据加载:将输入数据从主机内存传输到设备内存
- 计算执行:在AI Core或Vector Core上执行实际计算
- 结果存储:将计算结果存储到指定位置
- 资源释放:释放临时分配的资源
- 输出返回:将结果返回给调用者
- 开发环境搭建
3.1 硬件要求
CANN算子开发需要特定的硬件支持:
必需硬件:
- 昇腾AI处理器:Ascend 310/910/910B等
- 系统内存:至少16GB RAM
- 存储空间:至少100GB可用空间
- 网络连接:用于下载开发工具和依赖包
推荐配置:
- Ascend 910B:用于训练算子开发
- 64GB RAM:支持大规模模型开发
- SSD存储:提高编译和调试效率
- 千兆网络:加速资源下载
3.2 软件环境
安装和配置CANN开发环境:
核心组件安装:
# 1. 下载CANN开发套件
wget https://developer.huawei.com/ascend/cann/download
# 2. 安装驱动
sudo bash ./Ascend-hdk-*.run --install
# 3. 安装CANN toolkit
sudo bash ./Ascend-cann-toolkit*.run --install
# 4. 配置环境变量
echo 'source /usr/local/Ascend/ascend-toolkit/set_env.sh' >> ~/.bashrc
source ~/.bashrc
开发工具配置:
# 安装Python开发包
pip install tensorflow==2.8.0
pip install torch==1.11.0
pip install acl==5.0.2
# 配置IDE(以VS Code为例)
# 安装C/C++扩展
# 安装Python扩展
# 配置远程开发(如需要)
3.3 验证环境
验证开发环境是否正确配置:
// test_environment.cpp
#include "acl/acl.h"
#include <iostream>
int main() {
// 初始化ACL
aclError ret = aclInit(nullptr);
if (ret != ACL_ERROR_NONE) {
std::cout << "aclInit failed: " << ret << std::endl;
return -1;
}
// 获取设备数量
int32_t deviceCount = 0;
ret = aclrtGetDeviceCount(&deviceCount);
if (ret != ACL_ERROR_NONE) {
std::cout << "aclrtGetDeviceCount failed: " << ret << std::endl;
aclFinalize();
return -1;
}
std::cout << "Found " << deviceCount << " Ascend devices" << std::endl;
// 清理资源
aclFinalize();
return 0;
}
编译和运行验证程序:
# 编译
g++ -o test_env test_environment.cpp -I/usr/local/Ascend/ascend-toolkit/latest/acllib/include -L/usr/local/Ascend/ascend-toolkit/latest/acllib/lib64 -lacl
# 运行
./test_env
- 基础算子开发实践
4.1 向量加法算子
实现一个简单的向量加法算子:
// vector_add.cpp
#include "acl/acl.h"
#include <vector>
__global__ void vector_add_kernel(const float* a, const float* b, float* c, int size) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < size) {
c[idx] = a[idx] + b[idx];
}
}
class VectorAddOperator {
public:
VectorAddOperator() : stream_(nullptr) {}
~VectorAddOperator() {
if (stream_) {
aclrtDestroyStream(stream_);
}
}
aclError Init() {
// 创建流
return aclrtCreateStream(&stream_);
}
aclError Process(const std::vector<float>& input_a,
const std::vector<float>& input_b,
std::vector<float>& output) {
int size = input_a.size();
if (input_b.size() != size) {
return ACL_ERROR_PARAM_INVALID;
}
output.resize(size);
// 分配设备内存
float* d_a = nullptr;
float* d_b = nullptr;
float* d_c = nullptr;
aclError ret = aclrtMalloc(&d_a, size * sizeof(float), ACL_MEM_MALLOC_HUGE_FIRST);
if (ret != ACL_ERROR_NONE) return ret;
ret = aclrtMalloc(&d_b, size * sizeof(float), ACL_MEM_MALLOC_HUGE_FIRST);
if (ret != ACL_ERROR_NONE) {
aclrtFree(d_a);
return ret;
}
ret = aclrtMalloc(&d_c, size * sizeof(float), ACL_MEM_MALLOC_HUGE_FIRST);
if (ret != ACL_ERROR_NONE) {
aclrtFree(d_a);
aclrtFree(d_b);
return ret;
}
// 数据传输
ret = aclrtMemcpy(d_a, size * sizeof(float), input_a.data(),
size * sizeof(float), ACL_MEMCPY_HOST_TO_DEVICE);
if (ret != ACL_ERROR_NONE) {
aclrtFree(d_a);
aclrtFree(d_b);
aclrtFree(d_c);
return ret;
}
ret = aclrtMemcpy(d_b, size * sizeof(float), input_b.data(),
size * sizeof(float), ACL_MEMCPY_HOST_TO_DEVICE);
if (ret != ACL_ERROR_NONE) {
aclrtFree(d_a);
aclrtFree(d_b);
aclrtFree(d_c);
return ret;
}
// 启动核函数
int blockSize = 256;
int gridSize = (size + blockSize - 1) / blockSize;
vector_add_kernel<<<gridSize, blockSize, 0, stream_>>>(d_a, d_b, d_c, size);
// 等待计算完成
aclrtSynchronizeStream(stream_);
// 传输结果
ret = aclrtMemcpy(output.data(), size * sizeof(float), d_c,
size * sizeof(float), ACL_MEMCPY_DEVICE_TO_HOST);
// 释放内存
aclrtFree(d_a);
aclrtFree(d_b);
aclrtFree(d_c);
return ret;
}
private:
aclrtStream stream_;
};
4.2 矩阵乘法算子
实现高性能的矩阵乘法算子:
// gemm.cpp
#include "acl/acl.h"
#include <immintrin.h>
__global__ void gemm_kernel_naive(const float* A, const float* B, float* C,
int M, int N, int K) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < M && col < N) {
float sum = 0.0f;
for (int k = 0; k < K; k++) {
sum += A[row * K + k] * B[k * N + col];
}
C[row * N + col] = sum;
}
}
__global__ void gemm_kernel_tiling(const float* A, const float* B, float* C,
int M, int N, int K) {
// 分块大小
const int BM = 64;
const int BN = 64;
const int BK = 8;
__shared__ float As[BM][BK];
__shared__ float Bs[BK][BN];
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
// 计算全局索引
int row = by * BM + ty;
int col = bx * BN + tx;
float sum = 0.0f;
// 分块计算
for (int k = 0; k < K; k += BK) {
// 加载数据到共享内存
if (row < M && k + tx < K) {
As[ty][tx] = A[row * K + k + tx];
} else {
As[ty][tx] = 0.0f;
}
if (col < N && k + ty < K) {
Bs[ty][tx] = B[(k + ty) * N + col];
} else {
Bs[ty][tx] = 0.0f;
}
__syncthreads();
// 计算部分乘积
for (int i = 0; i < BK; i++) {
sum += As[ty][i] * Bs[i][tx];
}
__syncthreads();
}
// 存储结果
if (row < M && col < N) {
C[row * N + col] = sum;
}
}
class GEMMOperator {
public:
aclError Process(const float* A, const float* B, float* C,
int M, int N, int K, bool use_tiling = true) {
// 分配设备内存
float* d_A = nullptr;
float* d_B = nullptr;
float* d_C = nullptr;
aclError ret = aclrtMalloc(&d_A, M * K * sizeof(float), ACL_MEM_MALLOC_HUGE_FIRST);
if (ret != ACL_ERROR_NONE) return ret;
ret = aclrtMalloc(&d_B, K * N * sizeof(float), ACL_MEM_MALLOC_HUGE_FIRST);
if (ret != ACL_ERROR_NONE) {
aclrtFree(d_A);
return ret;
}
ret = aclrtMalloc(&d_C, M * N * sizeof(float), ACL_MEM_MALLOC_HUGE_FIRST);
if (ret != ACL_ERROR_NONE) {
aclrtFree(d_A);
aclrtFree(d_B);
return ret;
}
// 传输输入数据
ret = aclrtMemcpy(d_A, M * K * sizeof(float), A, M * K * sizeof(float),
ACL_MEMCPY_HOST_TO_DEVICE);
if (ret != ACL_ERROR_NONE) goto cleanup;
ret = aclrtMemcpy(d_B, K * N * sizeof(float), B, K * N * sizeof(float),
ACL_MEMCPY_HOST_TO_DEVICE);
if (ret != ACL_ERROR_NONE) goto cleanup;
// 启动核函数
if (use_tiling) {
dim3 blockDim(64, 1);
dim3 gridDim((N + 63) / 64, (M + 63) / 64);
gemm_kernel_tiling<<<gridDim, blockDim>>>(d_A, d_B, d_C, M, N, K);
} else {
dim3 blockDim(16, 16);
dim3 gridDim((N + 15) / 16, (M + 15) / 16);
gemm_kernel_naive<<<gridDim, blockDim>>>(d_A, d_B, d_C, M, N, K);
}
// 传输结果
ret = aclrtMemcpy(C, M * N * sizeof(float), d_C, M * N * sizeof(float),
ACL_MEMCPY_DEVICE_TO_HOST);
cleanup:
aclrtFree(d_A);
aclrtFree(d_B);
aclrtFree(d_C);
return ret;
}
};
4.3 卷积算子实现
实现2D卷积算子:
// conv2d.cpp
#include "acl/acl.h"
__global__ void conv2d_kernel(
const float* input, // [N, H, W, C]
const float* weight, // [KH, KW, C, K]
const float* bias, // [K]
float* output, // [N, OH, OW, K]
int N, int H, int W, int C,
int K, int KH, int KW,
int stride_h, int stride_w,
int pad_h, int pad_w
) {
// 计算输出维度
int OH = (H + 2 * pad_h - KH) / stride_h + 1;
int OW = (W + 2 * pad_w - KW) / stride_w + 1;
// 线程映射到输出位置
int n = blockIdx.z;
int oh = blockIdx.y * blockDim.y + threadIdx.y;
int ow = blockIdx.x * blockDim.x + threadIdx.x;
int k = threadIdx.z;
if (n >= N || oh >= OH || ow >= OW || k >= K) return;
float sum = 0.0f;
// 卷积计算
for (int kh = 0; kh < KH; kh++) {
for (int kw = 0; kw < KW; kw++) {
for (int c = 0; c < C; c++) {
// 计算输入坐标
int ih = oh * stride_h + kh - pad_h;
int iw = ow * stride_w + kw - pad_w;
// 边界检查
if (ih >= 0 && ih < H && iw >= 0 && iw < W) {
float in_val = input[n * H * W * C + ih * W * C + iw * C + c];
float weight_val = weight[kh * KW * C * K + kw * C * K + c * K + k];
sum += in_val * weight_val;
}
}
}
}
// 添加偏置并存储
sum += bias[k];
output[n * OH * OW * K + oh * OW * K + ow * K + k] = sum;
}
class Conv2DOperator {
public:
aclError Process(const float* input, const float* weight, const float* bias,
float* output,
int N, int H, int W, int C, int K, int KH, int KW,
int stride_h = 1, int stride_w = 1,
int pad_h = 0, int pad_w = 0) {
// 计算输出维度
int OH = (H + 2 * pad_h - KH) / stride_h + 1;
int OW = (W + 2 * pad_w - KW) / stride_w + 1;
// 分配设备内存
float* d_input = nullptr;
float* d_weight = nullptr;
float* d_bias = nullptr;
float* d_output = nullptr;
aclError ret = aclrtMalloc(&d_input, N * H * W * C * sizeof(float), ACL_MEM_MALLOC_HUGE_FIRST);
if (ret != ACL_ERROR_NONE) return ret;
ret = aclrtMalloc(&d_weight, KH * KW * C * K * sizeof(float), ACL_MEM_MALLOC_HUGE_FIRST);
if (ret != ACL_ERROR_NONE) goto cleanup1;
ret = aclrtMalloc(&d_bias, K * sizeof(float), ACL_MEM_MALLOC_HUGE_FIRST);
if (ret != ACL_ERROR_NONE) goto cleanup2;
ret = aclrtMalloc(&d_output, N * OH * OW * K * sizeof(float), ACL_MEM_MALLOC_HUGE_FIRST);
if (ret != ACL_ERROR_NONE) goto cleanup3;
// 传输数据
ret = aclrtMemcpy(d_input, N * H * W * C * sizeof(float), input,
N * H * W * C * sizeof(float), ACL_MEMCPY_HOST_TO_DEVICE);
if (ret != ACL_ERROR_NONE) goto cleanup4;
ret = aclrtMemcpy(d_weight, KH * KW * C * K * sizeof(float), weight,
KH * KW * C * K * sizeof(float), ACL_MEMCPY_HOST_TO_DEVICE);
if (ret != ACL_ERROR_NONE) goto cleanup4;
ret = aclrtMemcpy(d_bias, K * sizeof(float), bias,
K * sizeof(float), ACL_MEMCPY_HOST_TO_DEVICE);
if (ret != ACL_ERROR_NONE) goto cleanup4;
// 启动核函数
dim3 blockDim(16, 16, 1);
dim3 gridDim((OW + 15) / 16, (OH + 15) / 16, N);
// 每个block处理多个输出通道
int channels_per_block = min(64, K);
gridDim.z *= (K + channels_per_block - 1) / channels_per_block;
blockDim.z = channels_per_block;
conv2d_kernel<<<gridDim, blockDim>>>(d_input, d_weight, d_bias, d_output,
N, H, W, C, K, KH, KW,
stride_h, stride_w, pad_h, pad_w);
// 传输结果
ret = aclrtMemcpy(output, N * OH * OW * K * sizeof(float), d_output,
N * OH * OW * K * sizeof(float), ACL_MEMCPY_DEVICE_TO_HOST);
cleanup4:
aclrtFree(d_output);
cleanup3:
aclrtFree(d_bias);
cleanup2:
aclrtFree(d_weight);
cleanup1:
aclrtFree(d_input);
return ret;
}
};
- 性能优化技术
5.1 内存优化
内存访问是影响算子性能的关键因素:
// 内存优化示例:融合算子减少内存访问
__global__ void fused_conv_bn_relu_kernel(
const float* input, const float* conv_weight, const float* conv_bias,
const float* bn_mean, const float* bn_var, const float* bn_scale, const float* bn_shift,
float* output,
int N, int H, int W, int C, int K, int KH, int KW
) {
int n = blockIdx.z;
int oh = blockIdx.y * blockDim.y + threadIdx.y;
int ow = blockIdx.x * blockDim.x + threadIdx.x;
int k = threadIdx.z;
if (n >= N || oh >= H || ow >= W || k >= K) return;
// 卷积计算
float conv_sum = 0.0f;
for (int kh = 0; kh < KH; kh++) {
for (int kw = 0; kw < KW; kw++) {
for (int c = 0; c < C; c++) {
int ih = oh + kh;
int iw = ow + kw;
if (ih < H && iw < W) {
conv_sum += input[n * H * W * C + ih * W * C + iw * C + c] *
conv_weight[kh * KW * C * K + kw * C * K + c * K + k];
}
}
}
}
// 批归一化
float bn_output = (conv_sum + conv_bias[k] - bn_mean[k]) / sqrt(bn_var[k] + 1e-5);
bn_output = bn_scale[k] * bn_output + bn_shift[k];
// ReLU激活
output[n * H * W * K + oh * W * K + ow * K + k] = max(0.0f, bn_output);
}
5.2 计算优化
优化计算过程提升性能:
// 使用Winograd算法优化卷积
__global__ void winograd_conv2d_kernel(
const float* input, const float* weight, float* output,
int N, int H, int W, int C, int K
) {
// Winograd F(2x2, 3x3)算法
// 将3x3卷积转换为元素乘法
// 计算tile索引
int tile_x = blockIdx.x * blockDim.x + threadIdx.x;
int tile_y = blockIdx.y * blockDim.y + threadIdx.y;
int n = blockIdx.z;
int k = threadIdx.z;
const int TILE_SIZE = 2;
int tiles_x = (W + 1) / TILE_SIZE;
int tiles_y = (H + 1) / TILE_SIZE;
if (tile_x >= tiles_x || tile_y >= tiles_y || n >= N || k >= K) return;
// 提取2x2输入块
float in_block[2][2];
for (int i = 0; i < 2; i++) {
for (int j = 0; j < 2; j++) {
int x = tile_x * TILE_SIZE + j;
int y = tile_y * TILE_SIZE + i;
if (x < W && y < H) {
in_block[i][j] = input[n * H * W * C + y * W * C + x * C + k];
} else {
in_block[i][j] = 0.0f;
}
}
}
// 应用Winograd变换
float B[2][2];
B[0][0] = in_block[0][0] - in_block[0][1];
B[0][1] = in_block[0][1] + in_block[0][1];
B[1][0] = in_block[1][0] + in_block[1][0];
B[1][1] = in_block[1][1] - in_block[1][0];
// 与变换后的权重相乘
float G[2][2];
// ... 获取变换后的权重
float M[2][2];
for (int i = 0; i < 2; i++) {
for (int j = 0; j < 2; j++) {
M[i][j] = 0.0f;
for (int p = 0; p < 2; p++) {
M[i][j] += B[i][p] * G[p][j];
}
}
}
// 逆变换得到输出
float out_block[2][2];
out_block[0][0] = M[0][0] + M[0][1] + M[1][0] + M[1][1];
out_block[0][1] = M[0][0] - M[0][1] + M[1][0] - M[1][1];
out_block[1][0] = M[0][0] + M[0][1] - M[1][0] - M[1][1];
out_block[1][1] = M[0][0] - M[0][1] - M[1][0] + M[1][1];
// 存储结果
for (int i = 0; i < 2; i++) {
for (int j = 0; j < 2; j++) {
int x = tile_x * TILE_SIZE + j;
int y = tile_y * TILE_SIZE + i;
if (x < W && y < H) {
output[n * H * W * K + y * W * K + x * K + k] = out_block[i][j];
}
}
}
}
5.3 并行优化
提升并行度以充分利用硬件资源:
// 使用流水线并行优化
__global__ void pipelined_kernel(float* input, float* output, int size) {
// 共享内存缓冲区
__shared__ float buffer[3][256];
int tid = threadIdx.x;
int block_size = blockDim.x;
// 流水线阶段
for (int i = 0; i < size; i += block_size * 3) {
// Stage 0: 加载第一批数据
if (tid + i < size) {
buffer[0][tid] = input[tid + i];
}
__syncthreads();
// Stage 1: 加载第二批数据,处理第一批
if (tid + i + block_size < size) {
buffer[1][tid] = input[tid + i + block_size];
}
if (tid + i < size) {
buffer[2][tid] = process(buffer[0][tid]);
}
__syncthreads();
// Stage 2: 加载第三批数据,处理第二批,存储第一批
if (tid + i + 2 * block_size < size) {
buffer[0][tid] = input[tid + i + 2 * block_size];
}
if (tid + i + block_size < size) {
buffer[1][tid] = process(buffer[1][tid]);
}
if (tid + i < size) {
output[tid + i] = buffer[2][tid];
}
__syncthreads();
// 继续处理剩余数据
if (tid + i + 2 * block_size < size) {
buffer[2][tid] = process(buffer[0][tid]);
}
__syncthreads();
if (tid + i + block_size < size) {
output[tid + i + block_size] = buffer[1][tid];
}
__syncthreads();
if (tid + i + 2 * block_size < size) {
output[tid + i + 2 * block_size] = buffer[2][tid];
}
}
}
- CATLASS模板库使用

CATLASS是昇腾平台提供的算子模板库,极大简化了算子开发过程
6.1 CATLASS简介
CATLASS(Compute Accelerator Template Library for Ascend)提供了:
核心特性:
- 预优化的算子模板
- 灵活的配置选项
- 高度可定制化
- 良好的性能表现
支持的操作类型:
- GEMM(通用矩阵乘法)
- Convolution(卷积)
- Reduction(规约操作)
- Element-wise(逐元素操作)
6.2 使用CATLASS开发GEMM算子
// 使用CATLASS实现GEMM
#include "catlass/gemm.h"
class CATLASSGEMMOperator {
public:
struct Config {
int M, N, K;
float alpha = 1.0f;
float beta = 0.0f;
bool trans_a = false;
bool trans_b = false;
};
aclError Process(const float* A, const float* B, float* C, const Config& config) {
// 配置GEMM参数
catlass::GemmCoord problem_size(config.M, config.N, config.K);
catlass::TensorRef<float> ref_A(const_cast<float*>(A),
catlass::Layout::ColumnMajor);
catlass::TensorRef<float> ref_B(const_cast<float*>(B),
catlass::Layout::ColumnMajor);
catlass::TensorRef<float> ref_C(C, catlass::Layout::ColumnMajor);
// 创建GEMM算子
using Gemm = catlass::Gemm<float, float, float>;
// 配置GEMM参数
typename Gemm::Arguments arguments{
problem_size,
ref_A, ref_B, ref_C,
ref_C,
{config.alpha, config.beta},
config.trans_a ? catlass::Layout::kColumnMajor : catlass::Layout::kRowMajor,
config.trans_b ? catlass::Layout::kColumnMajor : catlass::Layout::kRowMajor
};
// 初始化和运行
Gemm gemm_op;
// 分配工作空间
size_t workspace_size = Gemm::get_workspace_size(arguments);
void* workspace = nullptr;
if (workspace_size > 0) {
aclrtMalloc(&workspace, workspace_size, ACL_MEM_MALLOC_HUGE_FIRST);
}
// 执行GEMM
aclError status = gemm_op.initialize(arguments, workspace);
if (status == ACL_ERROR_NONE) {
status = gemm_op.run();
}
// 释放工作空间
if (workspace) {
aclrtFree(workspace);
}
return status;
}
};
6.3 使用CATLASS开发卷积算子
// 使用CATLASS实现卷积
#include "catlass/convolution.h"
class CATLASSConvOperator {
public:
struct Config {
int N, H, W, C; // 输入维度
int K, R, S; // 输出通道数,卷积核大小
int pad_h, pad_w;
int stride_h, stride_w;
int dilation_h, dilation_w;
};
aclError Process(const float* input, const float* weight, const float* bias,
float* output, const Config& config) {
// 将卷积转换为矩阵乘法
using Conv2d = catlass::conv::ImplicitGemmConvolution<
float, // 元素类型
catlass::Layout::TensorNHWC, // 输入布局
catlass::Layout::TensorNHWC, // 输出布局
float, // 累积类型
catlass::arch::Sm80 // 计算能力
>;
// 配置卷积参数
using ConvolutionProblemSize = catlass::conv::ConvolutionProblemSize;
ConvolutionProblemSize problem_size(
config.N, config.H, config.W, config.C, // 输入
config.K, config.R, config.S, // 卷积核
config.pad_h, config.pad_w,
config.stride_h, config.stride_w,
config.dilation_h, config.dilation_w
);
// 创建卷积算子
Conv2d conv_op;
// 配置参数
typename Conv2d::Arguments arguments{
problem_size,
{input, catlass::Layout::TensorNHWC},
{weight, catlass::Layout::TensorNHWC},
{output, catlass::Layout::TensorNHWC},
{bias, catlass::Layout::TensorNHWC}
};
// 分配工作空间
size_t workspace_size = Conv2d::get_workspace_size(arguments);
void* workspace = nullptr;
if (workspace_size > 0) {
aclrtMalloc(&workspace, workspace_size, ACL_MEM_MALLOC_HUGE_FIRST);
}
// 执行卷积
aclError status = conv_op.initialize(arguments, workspace);
if (status == ACL_ERROR_NONE) {
status = conv_op.run();
}
// 释放工作空间
if (workspace) {
aclrtFree(workspace);
}
return status;
}
};
- 调试与性能分析
7.1 调试工具
使用昇腾提供的调试工具:
# 使用nsight进行调试
nsight --cuda-gdb ./your_application
# 使用msprof进行性能分析
msprof --application="./your_app" --output="performance_result"
# 生成调试报告
msprof --trace --application="./your_app" --output="trace_result"
7.2 性能分析
分析算子性能瓶颈:
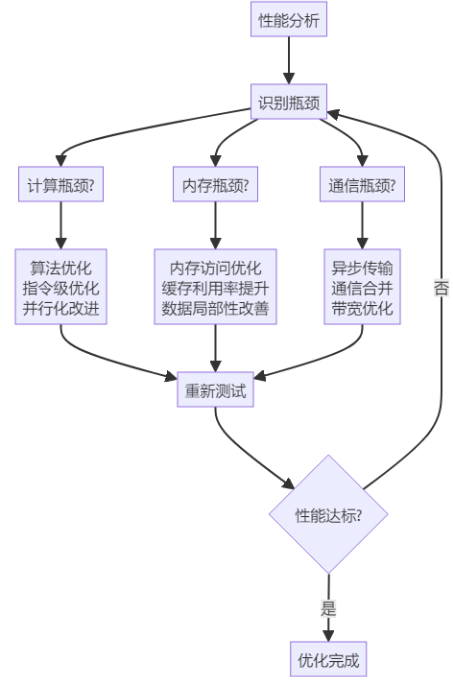
7.3 调试技巧
实用的调试技巧:
// 添加调试宏
#ifdef DEBUG
#define DEBUG_PRINT(fmt, ...) printf("[DEBUG] " fmt "\n", ##__VA_ARGS__)
#define DEBUG_ASSERT(cond) assert(cond)
#else
#define DEBUG_PRINT(fmt, ...)
#define DEBUG_ASSERT(cond)
#endif
// 使用调试日志
class DebugLogger {
public:
static void LogKernelLaunch(const char* kernel_name, dim3 grid, dim3 block) {
DEBUG_PRINT("Launching kernel %s: grid=(%d,%d,%d), block=(%d,%d,%d)",
kernel_name, grid.x, grid.y, grid.z, block.x, block.y, block.z);
}
static void LogMemoryTransfer(size_t size, aclrtMemcpyKind kind) {
const char* kind_str = (kind == ACL_MEMCPY_HOST_TO_DEVICE) ? "H2D" :
(kind == ACL_MEMCPY_DEVICE_TO_HOST) ? "D2H" : "D2D";
DEBUG_PRINT("Memory transfer %s: %zu bytes", kind_str, size);
}
static void LogPerformanceMetric(const char* metric, double value) {
DEBUG_PRINT("%s: %.2f", metric, value);
}
};
- 实战案例
8.1 ResNet50优化实现
使用CANN优化ResNet50网络:
// ResNet50残差块优化实现
class ResNet50Block {
private:
Conv2DOperator conv1_, conv2_, conv3_;
ElementwiseAddOperator add_;
ReluOperator relu_;
BatchNormOperator bn1_, bn2_, bn3_;
public:
aclError Forward(const float* input, float* output,
const float* weights, const float* biases,
int batch, int height, int width, int channels) {
// 分配中间结果存储
std::vector<float> conv1_out, conv2_out, conv3_out;
std::vector<float> bn1_out, bn2_out, bn3_out;
std::vector<float> relu1_out, relu2_out;
int conv_out_size = batch * height * width * channels;
conv1_out.resize(conv_out_size);
conv2_out.resize(conv_out_size);
conv3_out.resize(conv_out_size);
bn1_out.resize(conv_out_size);
bn2_out.resize(conv_out_size);
bn3_out.resize(conv_out_size);
relu1_out.resize(conv_out_size);
relu2_out.resize(conv_out_size);
// 第一个卷积块
conv1_.Process(input, weights, biases, conv1_out.data(),
batch, height, width, channels, channels, 1, 1);
bn1_.Process(conv1_out.data(), bn1_out.data(),
batch * height * width, channels);
relu_.Process(bn1_out.data(), relu1_out.data(),
batch * height * width * channels);
// 第二个卷积块
conv2_.Process(relu1_out.data(), weights + channels, biases + channels,
conv2_out.data(), batch, height, width, channels, channels, 3, 3);
bn2_.Process(conv2_out.data(), bn2_out.data(),
batch * height * width, channels);
relu_.Process(bn2_out.data(), relu2_out.data(),
batch * height * width * channels);
// 第三个卷积块
conv3_.Process(relu2_out.data(), weights + 2 * channels, biases + 2 * channels,
conv3_out.data(), batch, height, width, channels, channels * 4, 1, 1);
bn3_.Process(conv3_out.data(), bn3_out.data(),
batch * height * width, channels * 4);
// 残差连接(需要调整输入通道数)
std::vector<float> shortcut_out;
if (channels * 4 != channels) {
// 使用1x1卷积调整通道数
// ...
} else {
shortcut_out.assign(input, input + conv_out_size);
}
// 相加
add_.Process(bn3_out.data(), shortcut_out.data(), output,
batch * height * width * channels * 4);
return ACL_ERROR_NONE;
}
};
8.2 BERT Transformer优化
优化BERT中的Transformer模块:
// BERT Transformer优化实现
class BERTTransformer {
private:
MultiHeadAttention attention_;
FeedForwardNetwork ffn_;
LayerNormOperator layernorm1_, layernorm2_;
public:
aclError Forward(const float* input, float* output,
const float* attention_weights,
const float* ffn_weights,
int batch_size, int seq_len, int hidden_size,
int num_heads, int ffn_size) {
// 分配中间存储
int total_size = batch_size * seq_len * hidden_size;
std::vector<float> attention_out, ffn_out;
std::vector<float> norm1_out, norm2_out;
attention_out.resize(total_size);
ffn_out.resize(total_size);
norm1_out.resize(total_size);
norm2_out.resize(total_size);
// 第一个LayerNorm
layernorm1_.Process(input, norm1_out.data(),
batch_size, seq_len, hidden_size);
// Multi-Head Attention
attention_.Forward(norm1_out.data(), attention_out.data(),
attention_weights,
batch_size, seq_len, hidden_size, num_heads);
// 残差连接
for (int i = 0; i < total_size; i++) {
attention_out[i] = attention_out[i] + input[i];
}
// 第二个LayerNorm
layernorm2_.Process(attention_out.data(), norm2_out.data(),
batch_size, seq_len, hidden_size);
// Feed Forward Network
ffn_.Forward(norm2_out.data(), ffn_out.data(),
ffn_weights,
batch_size, seq_len, hidden_size, ffn_size);
// 第二个残差连接
for (int i = 0; i < total_size; i++) {
output[i] = ffn_out[i] + attention_out[i];
}
return ACL_ERROR_NONE;
}
};
- 总结与展望
9.1 技术总结
本文系统介绍了CANN算子开发的完整流程,涵盖了从基础概念到高级优化的各个方面。通过实践案例展示了如何开发高性能的AI算子,包括:
核心技能:
- 掌握CANN算子开发的基本流程和方法
- 理解昇腾硬件架构和优化技巧
- 熟练使用CATLASS模板库加速开发
- 具备调试和性能分析能力
实践经验:
- 内存优化技巧减少访问延迟
- 计算优化方法提升执行效率
- 并行编程模型充分利用硬件资源
- 实际案例应用巩固理论知识
9.2 未来展望
CANN算子开发的未来发展方向:
技术趋势:
- 自动化优化:AI驱动的算子自动调优
- 跨平台支持:统一的多硬件适配方案
- 低精度计算:INT4、二值化等新精度支持
- 稀疏计算:针对稀疏模型的专门优化
生态建设:
- 工具链完善:更强大的开发和调试工具
- 社区活跃:开源社区和开发者生态
- 标准制定:算子接口和性能标准
- 教育普及:系统的学习资源和培训体系
9.3 学习建议
对于想要深入掌握CANN算子开发的开发者,建议:
学习路径:
- 基础阶段:掌握C++、并行计算基础
- 入门阶段:学习CANN架构和基础算子开发
- 进阶阶段:掌握性能优化和CATLASS使用
- 专家阶段:参与开源项目,贡献算子实现
实践建议:
- 从简单算子开始,逐步增加复杂度
- 重视性能分析,培养优化思维
- 积极参与社区讨论,学习最佳实践
- 持续关注技术更新,保持知识更新
思考题
- 在算子开发过程中,如何平衡代码的可读性和性能优化?特别是在处理复杂的优化技巧时。
- 随着AI模型的规模不断扩大,算子开发面临哪些新的挑战?CANN平台需要如何演进来应对这些挑战?
- 如何设计一个通用的算子开发框架,既能够保证高性能,又能够简化开发流程?
- 在实际项目中,如何评估和选择不同的优化策略?如何建立完善的性能评估体系?
本文提供了CANN算子开发的全面指南,从理论基础到实践应用,帮助开发者掌握昇腾平台上的高性能算子开发技能。通过持续学习和实践,开发者可以充分利用昇腾硬件的强大能力,为AI应用的开发提供有力支撑。
昇腾CANN训练营正在火热进行中,点击报名,与我们一起探索AI算子开发的精彩世界!