
准确率92.9!GPT-4o直逼专业医师


一年前,ChatGPT在医学解剖学考试中平均准确率只有44%。
如今,GPT-4o交出了92.9%正确率的答卷,这将彻底改写 AI在医学教育中的角色定位。
据自然科学杂志的最新研究显示,AI不仅能解题,还能理解人体结构逻辑——它的答案,不再是背诵,而是推理。

四款AI测试:GPT-4o登顶
解剖学是医学生的基石学科,知识评估的复杂性让其成为检验大模型知识深度与准确性的试金石。
而这项涵盖325道USMLE(美国医师执照考试)的多项选择题,是迄今最系统的AI医学教育评测。
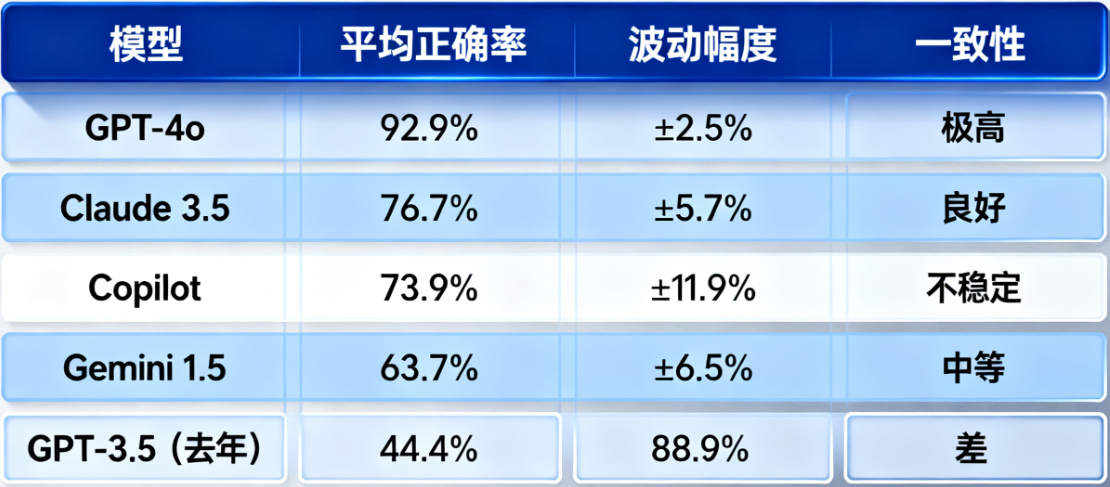
新一代大模型的平均准确度为76.8%±12.2%,相较于一年前GPT-3.5的44.4%准确率,实现了48.5%的巨大性能提升。
GPT-4o不仅正确率最高,还在三次答题中维持了超90%的稳定性。
这意味着它的知识逻辑趋于固定,而非随机猜测。
这标志着大模型已经从一个不可靠的辅助工具,蜕变成一个具有专家级潜力的系统。
模型的蜕变:从语言理解到结构推理
GPT-4o的质变不止在算力,而在推理路径的改变。
GPT-3.5以关键词匹配作答,遇到题干中隐含空间关系时极易混乱;
GPT-4o则能重建人体部位间的逻辑关系链。
例如在肱动脉分支类题中,GPT-3.5的答案正确率仅46%,GPT-4o上升至94%。
研究者认为,这得益于其多模态训练数据中加入了结构性文本,这让模型能在纯语言输入中重建空间语义。
三、Claude与Copilot:表现稳健但“领域盲区”明显
Anthropic的Claude 3.5在整体准确率上紧随其后(76.7%),其优势在骨骼系统与下肢题目,但在“腹部”和“上肢”表现下滑。研究显示,Claude的“知识置信度”高但偏好保守答案——相较GPT-4o,它更像一个安全型AI教师。
微软Copilot虽依托Office生态,便于教学整合,但受限于输入长度(最多4000字符),导致连续推理能力受损。尽管如此,它在“背部”“腹部”类题上仍有接近89%的准确率,显示其适合作为教学辅助工具,而非核心答题系统。
Google的Gemini 1.5表现最弱(63.7%),但仍优于去年GPT-3.5。这反映出:模型架构的迭代速度已超越单一公司优势,AI教育正进入多极竞争阶段。
知识结构失衡:AI懂头颈部,却不懂手
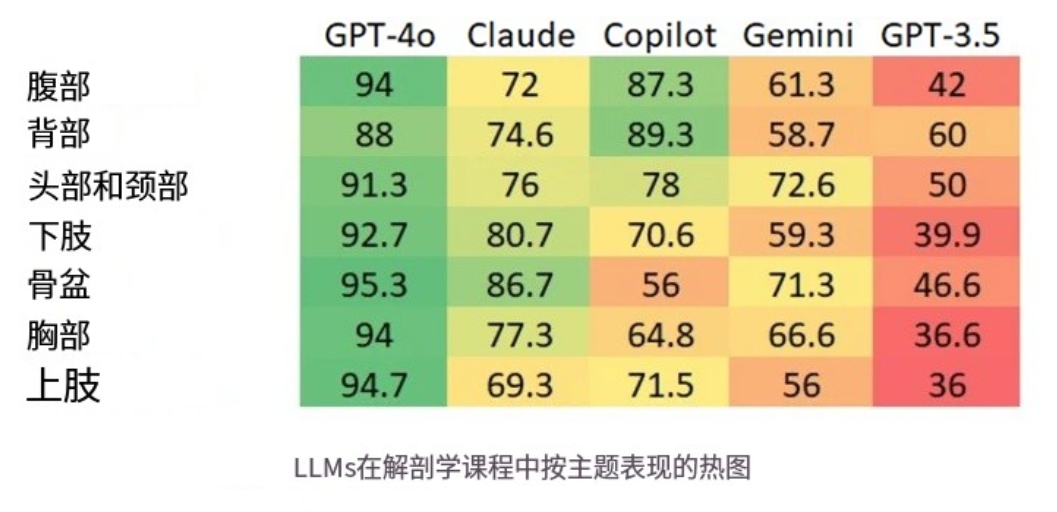
数据表明,大模型的性能在不同解剖主题间存在显著统计学差异:
● AI掌握度最高:头颈部(79.5%)、腹部(78.7%)
● AI掌握度最低最薄弱:上肢(72.9%)、胸廓(73.5%)
这种差异表明大模型并非拥有均匀的解剖学知识图谱,其训练数据在某些复杂区域(如上肢的神经和血管变异)上存在不足。
还有2.5%的题目从未被任何大模型答对过,这种集体失败表明:
大模型擅长知识的记忆、关联和模式识别,但在处理跨概念的复杂推理、临床情景等高阶思维时,仍存在无法逾越的智能天花板。

AI正在重塑医学教育模式
据美国AAMC报告,医学生使用AI进行USMLE备考的比例已达42%。
AI 能根据学生理解层次即时调整解释方式,还能将解剖与生理、临床影像等知识联通,提高学习效率。
但 AI答错的8%题目中,有三分之一表现出自信错误,学生容易把错误的知识当成真理。
AI学习系统应 + 导师的机制或将成为主流。
反向设计课程和考试重点
既然 AI在上肢和复杂推理表现最差,这些恰恰是人类专业知识最能创造价值的地方。
未来或将把教学资源和学生精力从 AI轻松掌握的基础知识点中解放出来,
重点教授2.5% AI没法掌握的复杂临床推理题。
专属医疗模型
在AI医疗领域,微调模型在解剖题上的准确率可较通用模型再提升10%–15%。
开发专科定制型医学LLM将成为未来趋势,它们将不再通读百科,而专注单一领域的知识深度。
未来出现AnatoGPT或NeuroGPT也不再奇怪。
