
在受限环境中优化MCP:无代码执行下的上下文治理策略


随着Anthropic模型上下文协议(MCP)的普及,其通过工具调用扩展模型能力的范式正重塑AI应用架构。然而,在安全与合规要求严苛的企业环境中,代码执行(Code Execution)功能往往被禁用,这使得MCP固有的两大痛点——工具定义膨胀与中间结果冗余——被急剧放大,导致上下文窗口被无效占用,响应延迟与成本激增。在不依赖代码执行这一关键能力的前提下,如何通过一系列精密的架构设计,实现对MCP上下文的有效治理,确保其在大规模企业应用中依然高效、可控。
一、 问题本质:MCP的上下文开销从何而来?
MCP的效能瓶颈源于其工作流程中的两个核心环节:
1. 初始化负载:工具定义的泛滥
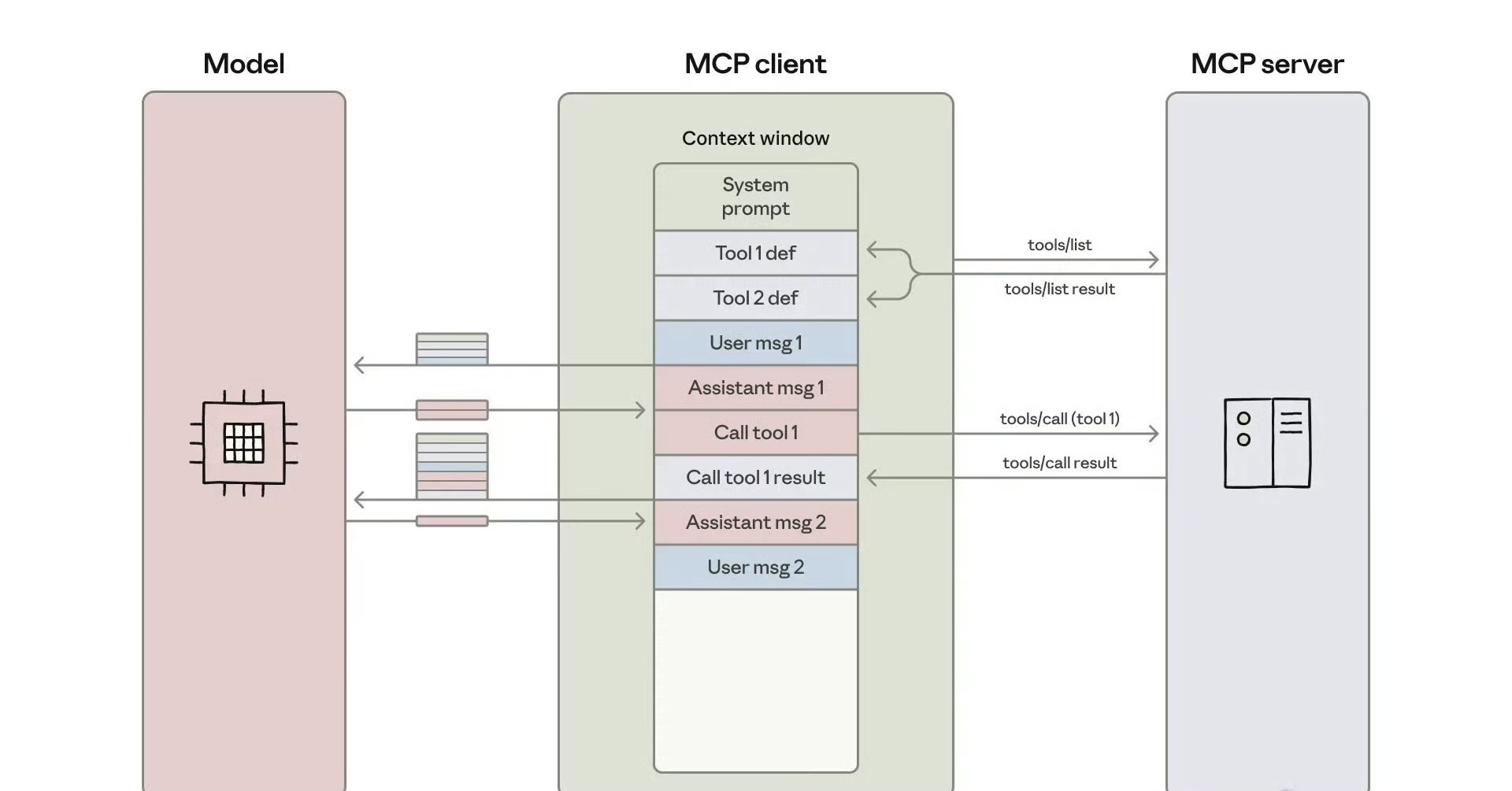
在传统模式下,所有可用工具的完整JSON Schema定义会在会话初期一次性加载至上下文。这如同将整个工具仓库的详细说明书堆在工程师面前,尽管他当前可能只需要一把螺丝刀。这种“预加载一切”的策略,直接挤占了本应用于任务推理与执行的宝贵上下文空间。
2. 执行时负载:中间结果的堆积
工具调用后返回的原始数据(如完整的文档内容、未经筛选的数据库查询结果)会完整地写入上下文。这些未经处理的中间结果不仅体量庞大,且多数细节可能在后续步骤中并无用处,造成了严重的Token浪费。
二、 核心策略一:工具定义的按需加载与动态发现
解决工具定义泛滥的关键,在于将“预加载”模式转变为“按需发现与加载”的动态机制。
1. 分层加载与元数据目录
系统初始化时,不应提供工具的具体参数,而是传递一个轻量的工具服务器元数据目录。该目录仅包含服务器名称及其核心功能描述,使模型对能力边界形成宏观认知,而非陷入实现细节。
2. 基于搜索的精准工具发现
引入一个search_tools的元工具,允许模型通过自然语言关键词(如“筛选本月销售数据”)进行查询。系统返回与之最相关的工具列表,初期仅提供名称与简介,仅在模型明确选择后才加载完整定义。这模拟了人类在工具箱中“寻找-确认-取用”的自然过程。
3. 工具定义的智能缓存与复用
对于高频使用的工具,其定义可被缓存在会话的短期记忆中。这避免了在同一会话内反复加载同一工具定义的开销,在动态加载与执行效率间取得了巧妙平衡。
三、 核心策略二:中间结果的压缩、分页与引用
对于工具执行产生的大量数据,治理的核心思想是:在MCP客户端或服务器端进行预处理,只将最精炼、最相关的信息注入上下文。
1. 结果摘要与内容采样
MCP客户端应具备对原始结果进行实时摘要的能力。例如,在处理一篇长文档时,返回模型的不是一个万字文本,而是一个结构化摘要:“主题:Q4规划;核心结论:3项;后续行动:5条。” 模型可根据此摘要决定是否需获取全文。
2. 分页与服务器端预处理
对于列表或表格数据,强制实施分页机制。同时,将数据过滤、排序等操作尽可能地上推至MCP服务器端完成。通过调用get_data(page=1, filter="status='urgent'"),确保返回的是最精简的结果集,从根本上杜绝了“取回万条数据,仅用其中十条”的浪费现象。
3. 结果引用与指针化传递
在处理极端庞大或敏感的数据时,最有效的策略是“指针化”。客户端不返回数据本身,而是返回一个结果引用ID(如data_ref: 0x7f3a2c)和元数据。模型在后续步骤中若需引用此数据,只需提供该ID即可。这相当于在无代码环境中,建立了一套安全的数据引用机制,将数据本身隔离在上下文之外。
四、 架构哲学:从“数据管道”到“智能调度中心”
上述策略的联合实施,标志着MCP客户端角色的一次根本性转变:它不再是一个被动的、传输原始数据的管道,而演进为一个主动的、具备一定认知能力的智能调度与治理中心。
它的职责不再是简单地转发请求与响应,而是:
● 管理一个动态的工具目录。
● 预处理和压缩流经的数据。
● 实施安全与合规的数据控制策略。

结论
在无法启用代码执行的企业级战场上,胜利并非源于某个单一的“银弹”技术,而是依靠一套体系化的上下文治理架构。通过将工具定义的动态加载与中间结果的智能压缩相结合,我们能够在不牺牲MCP核心灵活性的前提下,显著提升其效率与经济性。
这不仅是技术上的优化,更是一种架构哲学的体现:在资源受限的环境中,通过精妙的设计,让智能系统在安全、合规的框架内,发挥其最大的潜能。
