
超越提示工程:构建可靠AI系统的上下文工程指南


本文深入探讨了上下文工程这一构建生产级AI应用的核心 discipline。通过阐释智能体、查询增强、检索、记忆、工具和提示技术这五大核心组件,并结合代码示例与架构图,系统性地介绍了如何设计能够为LLM在正确时间提供正确信息的动态系统。本文指出,上下文工程是实现从演示原型到可靠、智能应用飞跃的关键。
从孤立模型到互联系统
每一位LLM开发者最终都会遇到同一堵“墙”:一个在写作、总结和推理上表现出色的强大模型,在面对真实世界问题时却显得力不从心。它无法回答关于您私有文档的问题,对昨天发生的事件一无所知,甚至在不知道答案时会“自信地”编造信息。问题的根源不在于模型的智能,而在于其根本性的孤立性。LLM是一个强大但孤立的大脑,无法访问您的特定数据、实时互联网,甚至对上一次对话没有记忆。这种孤立性源于其核心的架构限制:上下文窗口。上下文窗口是模型的活跃工作内存,是一个用于存放当前任务指令和信息的有限空间。就像一块白板,一旦写满,旧信息就会被擦除以容纳新指令,关键细节可能因此丢失。您无法仅通过编写更好的提示词来克服这一根本限制。您必须围绕模型构建一个系统。这就是上下文工程。
上下文工程是一门设计架构的学科,该架构负责在正确的时间向LLM提供正确的信息。它不是改变模型本身,而是构建连接模型与外部世界的桥梁——检索外部数据、连接实时工具、并赋予其记忆,使其回答基于事实,而不仅仅是训练数据。
核心组件一:智能体——系统的决策大脑
当您超越简单的“检索-生成”静态流程,开始构建需要判断、适应或多步推理的系统时,智能体便成为核心。
什么是智能体?
在上下文工程中,智能体是管理信息如何(以及多好地)在系统中流动的协调者。与盲目遵循脚本的管道不同,智能体能够:
1. 动态决策信息流:根据已学内容决定下一步行动。
2. 在多次交互中保持状态:记住过往行为,用以指导未来决策。
3. 自适应地使用工具:选择并组合可用工具,完成未显式编程的任务。
4. 根据结果修改策略:在策略无效时尝试不同方法。
智能体的关键策略与挑战:
● 上下文卫生:智能体需监控和管理自身上下文质量,包括上下文总结、上下文修剪、上下文卸载,以避免过载和污染。
● 动态工具选择:并非将所有工具倒入提示中,而是过滤并仅加载与任务相关的工具,减少混淆。
● 上下文窗口的挑战:更大的上下文窗口(如100万令牌)会引入新的故障模式,如上下文污染(幻觉信息持续影响)、上下文干扰(过度依赖历史)和上下文冲突(信息矛盾)。
架构角色:智能体不取代其他技术,而是智能地协调它们。它可能应用查询重写、选择不同分块策略,或决定何时压缩对话历史。
核心组件二:查询增强——从模糊意图到精确查询
查询增强在管道起始端解决“垃圾进,垃圾出”的问题,将混乱的用户请求转化为系统可理解的精确意图。
一. 查询重写
将原始查询转换为更适合检索的版本。
● 示例:
原始查询: "我的API调用一直失败,怎么让它工作?"
重写后查询:
作用:重构不清晰的问题、移除无关上下文、引入增强匹配的关键词。
query="API call failure, troubleshooting authentication headers, size limits, timeout, 500 error"
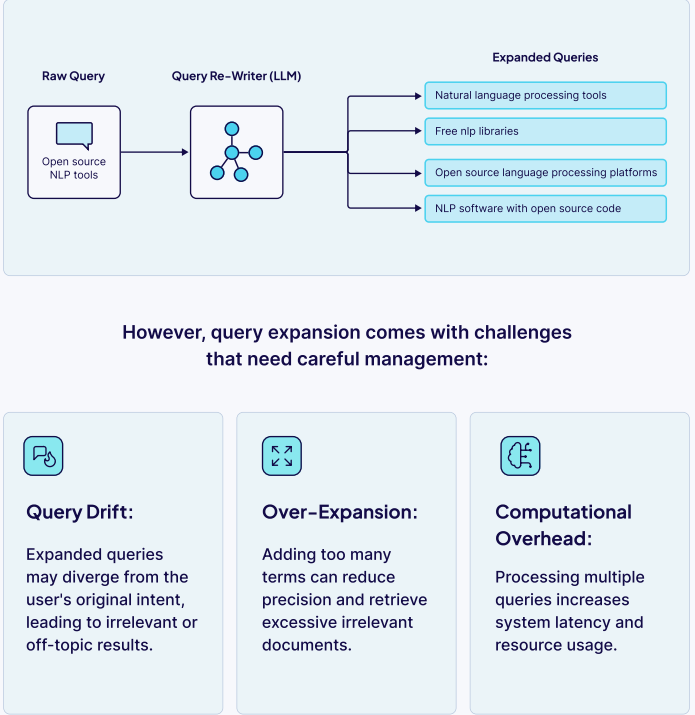
二. 查询扩展
从单个用户输入生成多个相关查询,以扩大检索范围。
● 示例: 查询“自然语言处理工具”可能扩展为 [“NLP库”, “开源API工具”, “语言处理平台”]。
● 挑战:需管理查询漂移(偏离原意)和计算开销。
三. 查询分解
将复杂的多层面问题拆分为可独立处理的子查询。
● 流程:
○ 分解阶段:LLM将“比较产品A和B的优缺点并给出推荐”分解为【产品A优点】、【产品A缺点】、【产品B优点】、【产品B缺点】等子查询。
○ 处理阶段:每个子查询独立检索。
○ 合成阶段:系统综合所有结果,生成连贯答案。
四. 查询智能体
最先进的形式,使用智能体动态管理整个查询流程,包括多集合路由和基于结果的迭代重查。
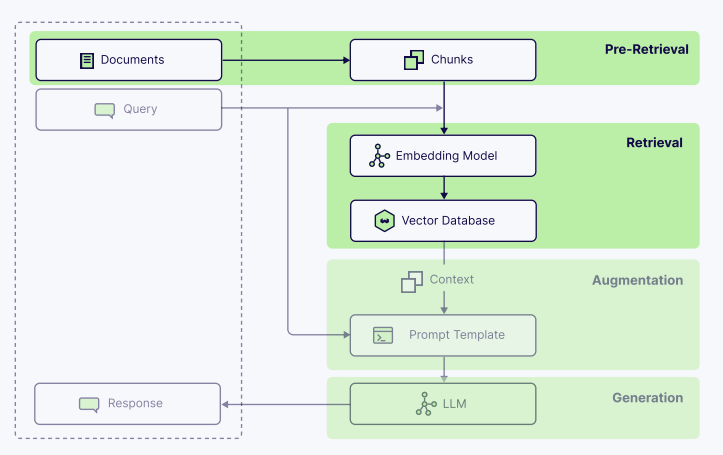
核心组件三:检索——连接LLM与知识库的桥梁
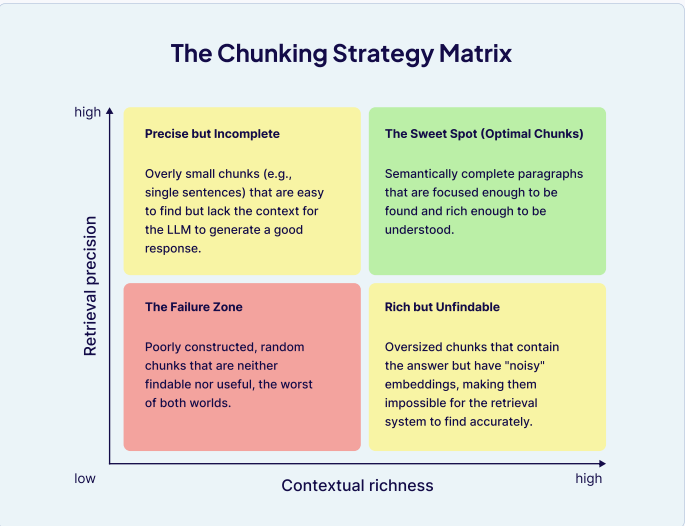
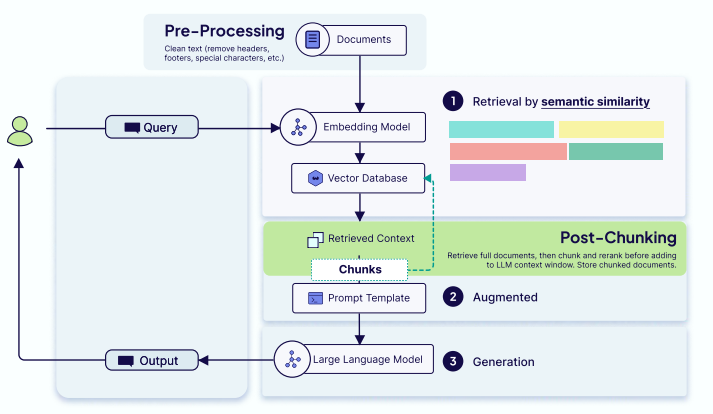
原始文档集通常太大,无法放入LLM的上下文窗口。分块是成功检索的关键,其核心是在检索精度和上下文丰富性之间找到平衡。

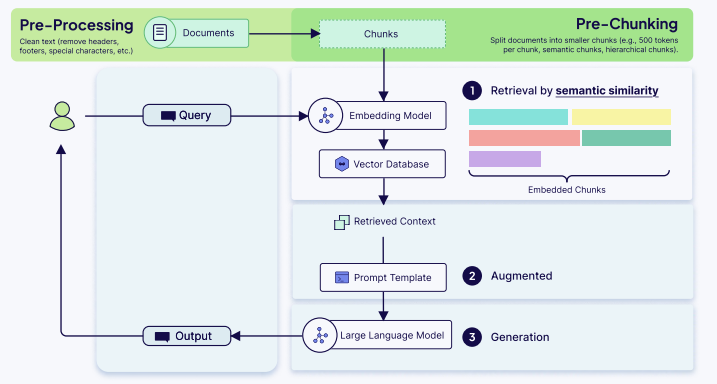
架构模式:预分块 vs. 后分块
● 预分块:离线处理,查询时检索极快,但策略固定,更改成本高。
○ 清洁数据 -> 分块文档 -> 嵌入并存储块
● 后分块:实时处理,可根据查询上下文动态分块,更灵活、结果更相关,但会引入延迟。
○ 存储文档 -> 检索相关文档 -> 动态分块
核心组件四:提示技术——引导模型推理的艺术
提示工程关注如何组织指令,而上下文工程关注构建提供给模型的信息和知识。二者结合才能发挥最大效能。
经典技术:
● 思维链:要求模型展示推理步骤,提高复杂任务透明度。
● 少样本提示:提供输入-输出示例,引导模型学习所需格式和风格。
高级策略:
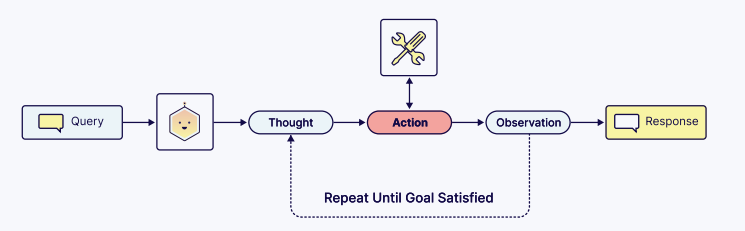
● ReAct提示:将推理和行动交错结合,使模型能与工具交互并基于观察调整推理。
● 思维树:让模型并行探索多个推理路径,像决策树一样评估不同可能性,适用于证据众多的复杂问题。
工具使用的提示:
清晰定义工具的描述至关重要。
核心组件五:记忆——赋予系统历史与学习能力
记忆将LLM从无状态的文本处理器转变为能保持上下文、从过去学习并动态适应的智能体。
记忆类型:
● 短期记忆:即时的推理空间,等同于上下文窗口。通过上下文学习将最近对话、行动打包进提示。挑战在于高效的令牌管理。
● 长期记忆:持久的存储系统,通常由向量数据库驱动的RAG实现。包括:
○ 情景记忆:存储具体事件和交互。
○ 语义记忆:存储领域知识和事实。
○ 程序性记忆:存储内化的工作流步骤
● 工作记忆:用于处理多步任务的临时缓冲区(如暂存旅行预订的详情)。
有效记忆管理原则:
1. 修剪与优化:定期删除重复、合并相关、丢弃过时记忆。例如,客户支持机器人可自动修剪90天前已解决的对话日志,仅保留摘要。
2. 选择性存储:并非所有交互都值得永久保存。可使用LLM对交互进行“反思”并分配重要性分数后再存储。
3. 掌握检索艺术:使用重排序和迭代检索等技术,确保在正确时间检索到最相关的信息。
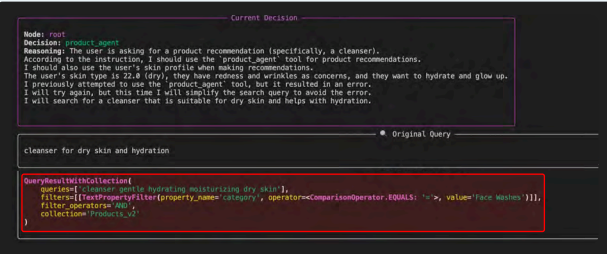
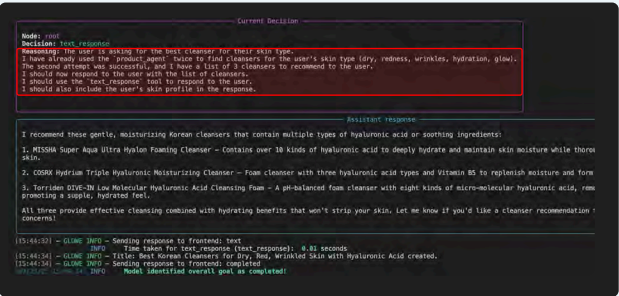
核心组件六:工具——赋予模型行动的“双手”
工具是将LLM智能体连接到外部世界,使其能够采取行动和获取实时信息的接口。
演进:从提示到函数调用
早期的“技巧式”提示已被原生函数调用能力取代,模型可以输出结构化的JSON来调用预定义函数。
编排的挑战:
给智能体一个工具是简单的,但让它可靠、安全、有效地使用工具则需要精细的编排。这通常遵循思考-行动-观察循环:
1. 工具发现:通过系统提示提供可用工具及其清晰描述。
2. 工具选择与规划:智能体推理是否需要工具、需要哪个、是否需要链式调用。
3. 参数制定:从用户查询中提取并格式化工具所需的参数。
4. 反思:基于工具执行的观察结果,决定下一步行动。
下一个前沿:标准化
模型上下文协议(MCP,由Anthropic提出)旨在成为“AI的USB-C”,提供一个通用标准来连接AI应用与外部数据和工具。它将传统的MxN集成问题(M个应用各自需要为N个工具编写自定义代码)简化为M+N问题,代表了AI工具化的未来方向。
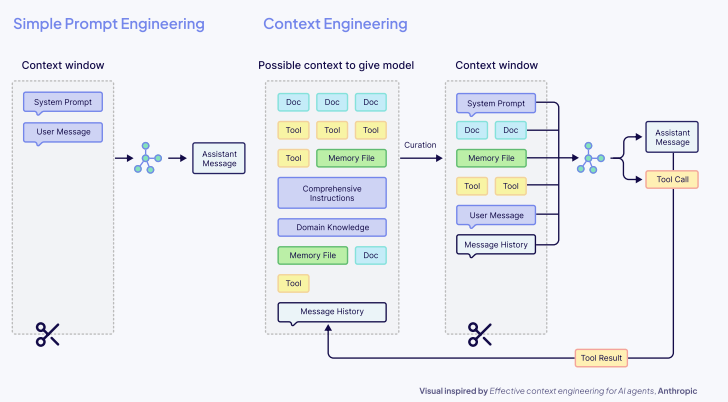
总结:从提示者到系统架构师
上下文工程不仅仅是提示LLM、构建检索系统或设计AI架构。它是关于构建互联、动态的系统,这些系统能够在各种用途和用户中可靠地工作。
本电子书中描述的所有组件都将随着新技术、新模型和新发现而不断发展,但真正功能完备的系统与失败的AI应用之间的区别,将在于它们在整个架构中设计上下文的能力。
我们不再仅仅是与模型对话的提示者,而是成为为模型构建其所处世界的架构师。我们——构建者、工程师和创造者——深知一个真理:最好的AI系统并非源于更大的模型,而是源于更好的工程。
