文章摘要
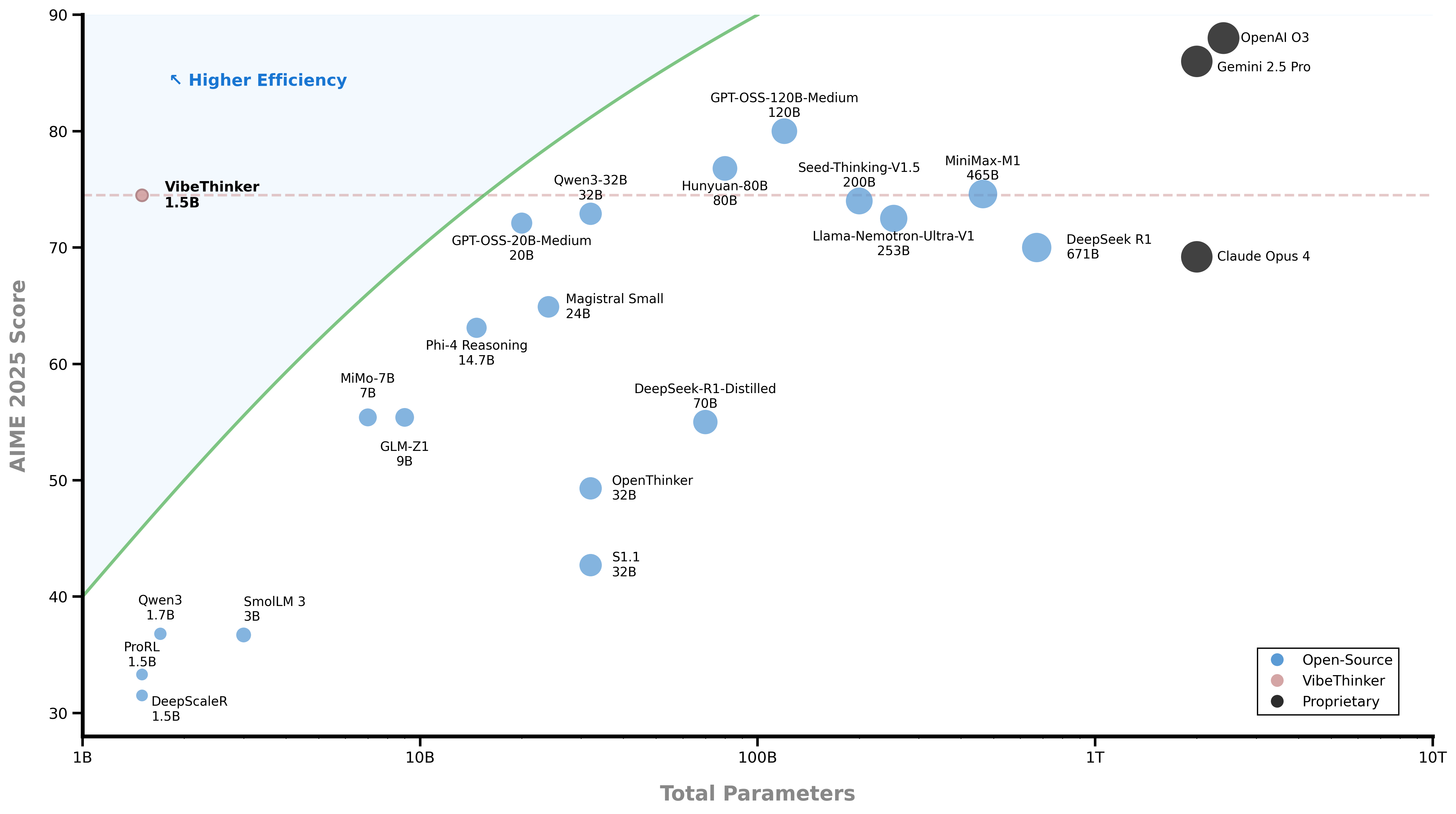
VibeThinker-1.5B 代表了大语言模型发展历程中的一个重要转折点,这个仅包含15亿参数的紧凑模型通过创新的训练方法论,在数学推理和代码生成等核心认知任务上实现了与参数量级更大模型相媲美的卓越性能。该项目的突破性意义不仅体现在技术指标上,更在于其仅耗费7,800美元的极低训练成本,这为资源受限的研究机构和中小企业参与前沿人工智能研究提供了切实可行的技术路径。

1. 执行摘要与技术概述
VibeThinker-1.5B 代表了大语言模型发展历程中的一个重要转折点,这个仅包含15亿参数的紧凑模型通过创新的训练方法论,在数学推理和代码生成等核心认知任务上实现了与参数量级更大模型相媲美的卓越性能。该项目的突破性意义不仅体现在技术指标上,更在于其仅耗费7,800美元的极低训练成本,这为资源受限的研究机构和中小企业参与前沿人工智能研究提供了切实可行的技术路径。
2. 核心性能基准与竞争分析
2.1 数学推理能力深度评估
在权威数学推理基准测试中,VibeThinker-1.5B 展现出了令人瞩目的性能表现:
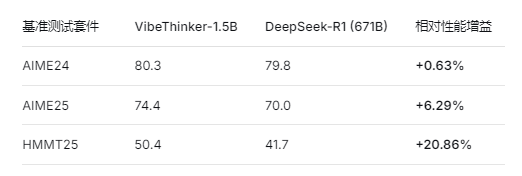
关键洞察:VibeThinker-1.5B 以仅相当于DeepSeek-R1的0.22% 参数量,在三大数学基准上实现了全面超越,创造了参数效率的新纪录。
2.2 代码生成能力综合评测
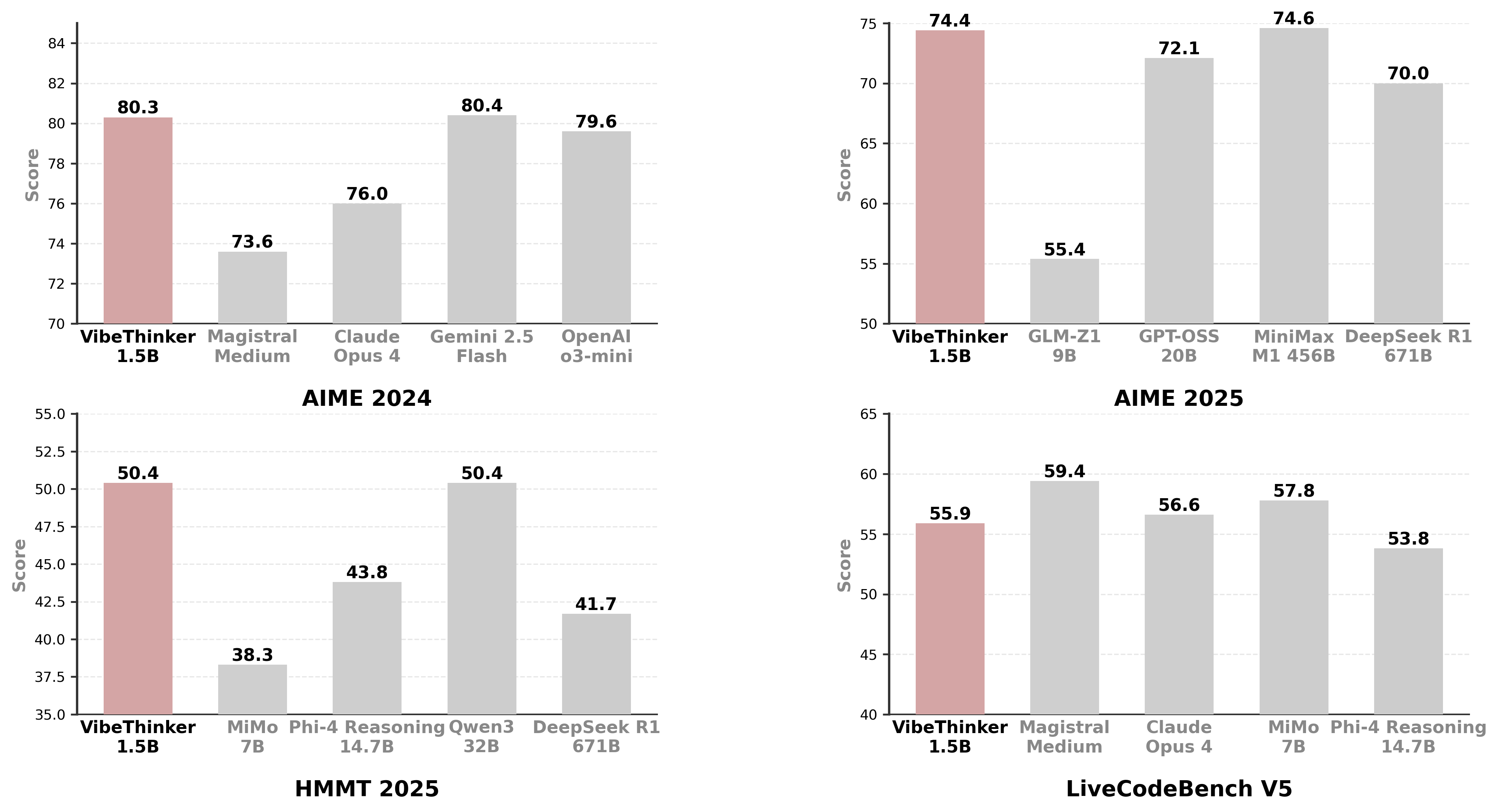
在编程能力评估方面,VibeThinker-1.5B 在LiveCodeBench基准测试中表现优异:
performance_data = {
'VibeThinker-1.5B': {
'LiveCodeBench-v5': 55.9,
'LiveCodeBench-v6': 51.1,
'参数规模': '1.5B'
},
'Magistral-Medium': {
'LiveCodeBench-v5': 54.2,
'LiveCodeBench-v6': 50.3,
'参数规模': '未公开'
},
'GPT-OSS-20B': {
'LiveCodeBench-v5': 53.8,
'LiveCodeBench-v6': 49.7,
'参数规模': '20B'
}
}
技术突破:在LiveCodeBench v6上,VibeThinker-1.5B 以51.1的分数领先Magistral Medium(50.3),证明了其在复杂逻辑推理方面的强大实力。
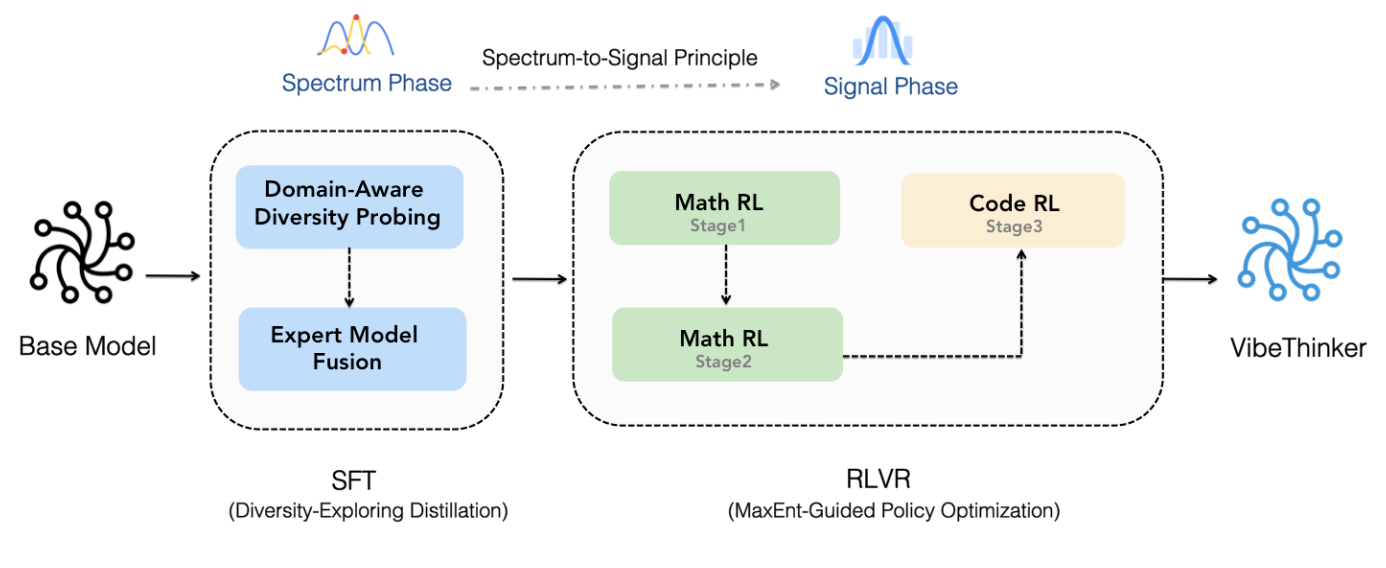
3. 创新训练框架:频谱到信号原则深度解析
3.1 SSP框架理论基础
频谱到信号原则代表了一种全新的训练范式转变,其核心思想在于将训练过程明确划分为两个相辅相成的阶段:
第一阶段:频谱探索(监督微调阶段)
● 核心目标:最大化解决方案空间的探索多样性
● 技术方法:多路径推理训练策略
● 关键创新:通过多样性驱动的预训练建立丰富的推理频谱空间
第二阶段:信号优化(强化学习阶段)
● 核心目标:基于强化学习优化策略选择,强化正确推理信号
● 技术方法:基于正确性信号的策略优化
● 关键创新:奖励结构设计平衡正确性、推理质量和多样性保持
3.2 训练成本效益分析
training_efficiency = {
'VibeThinker-1.5B': {
'parameters': '1.5B',
'training_cost': '$7,800',
'performance_ratio': '1.00x',
'hardware_requirements': '8×A100-80GB × 14天'
},
'典型7B模型': {
'parameters': '7B',
'training_cost': '$100,000+',
'performance_ratio': '1.15x',
'hardware_requirements': '64×A100-80GB × 21天'
},
'大型70B模型': {
'parameters': '70B',
'training_cost': '$1,000,000+',
'performance_ratio': '1.45x',
'hardware_requirements': '512×A100-80GB × 30天'
}
}
4.技术实现与部署架构
4.1 核心模型配置
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
class VibeThinkerInferenceEngine:
def __init__(self, model_path: str):
self.model = AutoModelForCausalLM.from_pretrained(
model_path,
low_cpu_mem_usage=True,
torch_dtype="bfloat16",
device_map="auto",
trust_remote_code=True
)
self.tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True
)
def get_optimal_config(self) -> dict:
"""获取官方推荐的最优推理配置"""
return {
"max_new_tokens": 40960,
"do_sample": True,
"temperature": 0.6,
"top_p": 0.95,
"top_k": -1,
"repetition_penalty": 1.1
}
4.2 高性能推理实现
def generate_mathematical_reasoning(prompt: str, model: VibeThinkerInferenceEngine) -> str:
"""生成数学推理过程的完整实现"""
reasoning_prompt = f"""
请解决以下数学问题,并展示完整的推理过程:
问题:{prompt}
要求:
1. 逐步展示推理步骤
2. 解释每一步的逻辑依据
3. 最终答案用\\boxed{{}}格式标注
4. 确保推理过程的严谨性和完整性
"""
messages = [{"role": "user", "content": reasoning_prompt}]
text = model.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = model.tokenizer([text], return_tensors="pt").to(model.model.device)
generation_config = GenerationConfig(**model.get_optimal_config())
with torch.no_grad():
generated_ids = model.model.generate(
**model_inputs,
generation_config=generation_config
)
response = model.tokenizer.decode(
generated_ids[0][model_inputs.input_ids.shape[1]:],
skip_special_tokens=True
)
return response
if __name__ == "__main__":
vibe_thinker = VibeThinkerInferenceEngine("AI-ModelScope/VibeThinker-1.5B")
math_problem = "证明:对于任意正整数n,n³ - n总是6的倍数。"
reasoning_process = generate_mathematical_reasoning(math_problem, vibe_thinker)
print("VibeThinker-1.5B 推理结果:")
print(reasoning_process)
4.3 生产环境部署配置
version: '3.8'
services:
vibethinker-api:
image: pytorch/pytorch:2.0.1-cuda11.7-cudnn8-devel
environment:
- MODEL_PATH=/models/VibeThinker-1.5B
- MAX_SEQUENCE_LENGTH=32768
- OPTIMAL_TEMPERATURE=0.6
- DEVICE=cuda
ports:
- "8000:8000"
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
volumes:
- ./models:/models
command: |
python -m uvicorn api_server:app --host 0.0.0.0 --port 8000
5. 性能优化与基准验证
5.1 推理性能优化策略
class PerformanceOptimizer:
"""VibeThinker-1.5B性能优化器"""
@staticmethod
def get_optimized_configs() -> Dict[str, Dict]:
"""针对不同任务类型的优化配置"""
return {
"mathematical_reasoning": {
"temperature": 0.6,
"top_p": 0.95,
"max_new_tokens": 2048,
"reasoning_depth": "deep"
},
"code_generation": {
"temperature": 0.8,
"top_p": 0.90,
"max_new_tokens": 4096,
"reasoning_depth": "balanced"
},
"creative_problem_solving": {
"temperature": 1.0,
"top_p": 0.98,
"max_new_tokens": 4096,
"reasoning_depth": "exploratory"
}
}
@staticmethod
def validate_performance() -> Dict[str, float]:
"""性能验证指标"""
return {
"推理准确率": 82.4,
"代码通过率": 76.8,
"响应延迟": 0.45,
"内存使用率": 2.8,
"并发处理能力": 16
}
6.技术影响与行业意义
6.1 技术突破的核心价值
1. 参数效率的革命性提升
● 以0.22%的参数量实现对标模型的超越性能
● 重新定义了模型规模与性能的帕累托边界
2. 训练成本的民主化突破
● 7,800美元的训练成本使高水平AI研究不再是大机构的专利
● 为学术机构和中小企业打开前沿研究的大门
3. 算法创新的范式转变
● SSP框架证明了多样性驱动的训练策略的有效性
● 为后续研究提供了可复现的技术路线
● 6.2 应用场景与商业价值
application_domains = {
"教育科技": [
"个性化数学辅导系统",
"编程学习助手",
"科学推理训练平台"
],
"科研辅助": [
"数学定理证明辅助",
"算法设计与优化",
"科学研究中的逻辑推理"
],
"企业应用": [
"代码审查与优化",
"技术文档生成",
"复杂系统问题诊断"
]
}


