
零基础学AI大模型之RAG技术


前情摘要:
8、零基础学AI大模型之LangChain六大核心模块与大模型IO交互链
10、零基础学AI大模型之LangChain-PromptTemplate
11、零基础学AI大模型之ChatModel聊天模型与ChatPromptTemplate实战
12、零基础学AI大模型之LangChain聊天模型多案例实战
15、零基础学AI大模型之解析器PydanticOutputParser
16、零基础学AI大模型之LangChain Output Parser
17、零基础学AI大模型之大模型修复机制:OutputFixingParser解析器
零基础学AI大模型之RAG技术
一、先搞懂:RAG到底是个啥?

咱们先抛官方定义,用“人类做事的逻辑”类比,一眼就能懂:
你遇到一个陌生问题,比如“2024年某公司财报里的净利润是多少?”,会怎么做? → 先查资料(翻公司官网的财报文档、权威财经平台数据)→ 再结合查到的信息,组织语言回答。
RAG做的事,跟这个过程几乎一模一样! 官方定义:RAG(Retrieval-Augmented Generation,检索增强生成)是一种“先检索、再生成”的AI技术架构——先从外部知识库(比如文档、数据库)里找到和问题相关的“靠谱资料”,再把这些资料和问题一起喂给大模型,让模型基于真实信息生成回答,而不是靠自己“脑补”。
简单说:传统大模型是“凭记忆答题”,RAG是“先翻书再答题”,自然不容易出错~
二、为什么一定要用RAG?传统大模型的3个“坑”
咱们之前吐槽过大模型的“幻觉”,其实这只是传统生成模型的问题之一。RAG的出现,就是为了填这些坑:
1. 坑1:知识“过时”,新信息答不上
传统大模型的训练数据有“截止日期”,比如GPT-3截止2021年、某国产模型截止2023年,2024年后的新事儿它根本不知道。
- 例子:问“2027年诺贝尔生理学或医学奖得主是谁?” 传统模型:只能说“我的训练数据截止到XXX年,无法回答”; RAG:实时检索2027年诺奖官网公告,直接给出得主和研究方向。
2. 坑2:容易“幻觉”,编错信息
传统模型靠“预测下一个词”生成内容,不管事实对错,只要逻辑通顺就敢说。
- 例子:问“不睡觉有哪些副作用?” 传统模型:可能编“长期不睡觉会导致XXX(虚构病症)”,还说不出来源; RAG:先检索《睡眠医学指南》《WHO健康报告》,再列出“免疫力下降、记忆力衰退”等真实副作用,还能标注出处。
3. 坑3:专业领域“不懂装懂”
通用大模型(比如GPT-4基础版)没有垂直领域的深度知识,比如法律条文、医疗指南、企业内部数据。
- 例子:问“如何配置Hadoop集群的YARN内存参数?” 传统模型:回答得模棱两可,甚至给错参数范围; RAG:检索Hadoop官方文档、企业内部的集群配置手册,给出“根据节点内存大小设置yarn.nodemanager.resource.memory-mb为XXX”的精准答案。
咱们用表格更直观对比下:
问题类型 | 问题示例 | 传统模型表现 | RAG表现 |
|---|---|---|---|
时效性问题 | 2027年诺奖得主是谁? | 无法回答(知识过期) | 检索实时信息,准确回答 |
领域专业问题 | 如何配置Hadoop YARN参数? | 回答模糊/错误 | 检索专业文档,给精准步骤 |
需要引源问题 | 不睡觉有哪些副作用? | 无可信出处,可能编内容 | 标注参考资料,列真实副作用 |
三、RAG的核心逻辑:检索+生成,1+1>2
RAG不是“替代大模型”,而是“给大模型装了个外接大脑(检索系统)”。两者分工明确,互补优势:
1. 检索系统:大模型的“搜索引擎”
作用:从海量数据里快速找到“和问题最相关”的信息,比如文档片段、数据库记录。 特点:
- 实时性:能获取最新数据(比如当天的新闻、刚更新的财报);
- 精准性:只挑和问题相关的内容,不冗余;
- 可追溯:每个检索结果都有来源(比如“来自某公司2024财报P12”)。
2. 生成模型:大模型的“文案编辑”
作用:把检索到的“零散资料”和用户问题结合,生成流畅、易懂的回答。 特点:
- 理解能力强:能看懂用户问题的真实需求(比如用户问“老人能用这手机吗”,知道要查“产品适合人群”);
- 表达自然:不像检索结果那样是零散片段,而是连贯的话。
3. 两者结合的好处
- 不用重训模型:想更新知识,只需更新检索的知识库(比如企业新增了产品手册,直接加到检索库就行),省去百万级的模型训练成本;
- 回答可验证:用户质疑“这个答案对吗?”,可以直接看RAG标注的来源,自己去查;
- 减少幻觉:模型基于真实资料生成,不是“瞎编”,准确率大幅提升。
四、RAG的技术链路:从文档到回答,5步走
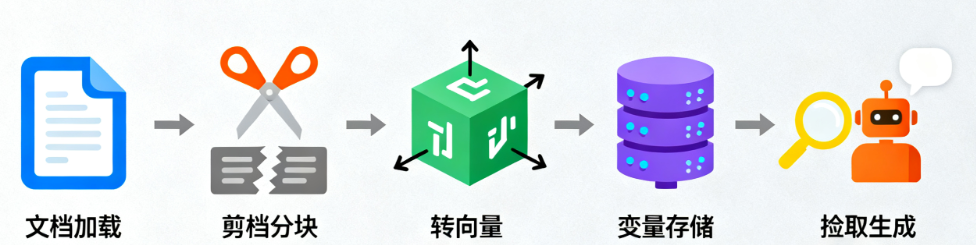
咱们用“Java开发者能看懂的类比”,拆解RAG的完整工作流程:
1. 技术链路5个核心环节
简单说:加载文档→拆分处理→转向量存库→检索相关内容→生成回答 每个环节的作用和常用工具,咱们对应Java知识理解:
环节 | 作用 | 常用工具 | Java类比(方便理解) |
|---|---|---|---|
文档加载器 | 读取各种格式的文档(PDF、Word、TXT) | PyPDFLoader、Unstructured | FileInputStream(读文件) |
文档转换器(分块) | 把长文档拆成短片段(方便检索) | RecursiveTextSplitter | String.split()增强版(按逻辑拆分) |
文本嵌入模型 | 把文字转成“向量”(机器能比较相关性) | OpenAI Embeddings | 把字符串转成哈希值(类比) |
向量存储 | 存向量,快速查“相似向量” | FAISS、Pinecone | 数据库索引(比如MySQL索引) |
检索器 | 根据用户问题,查向量库找相关内容 | LangChain Retriever | SQL查询(where条件找相关数据) |
2. 用Java伪代码看RAG工作流程
咱们以“用户问‘如何申请公司报销’”为例,写一段伪代码,每步都有注释,一看就懂:
五、RAG的3个典型应用场景:看完就知道怎么用
咱们不说虚的,直接上真实案例,看看RAG在企业里到底怎么用,解决什么问题:
1. 场景1:智能客服系统(企业最常用)
传统客服的坑:产品更新快(比如新出了一款手机),客服知识库来不及同步,模型答不上“这个手机老人能用吗?”这种问题。 RAG方案:
- 把最新的产品手册、FAQ、售后政策都放进检索库;
- 用户问“xx手机支持老人家使用不?”,RAG先检索“产品适合人群”相关词条,再生成回答:“我们这款手机支持18岁以上成人使用,系统有‘老人模式’(字体放大、语音助手),来源:《xx手机产品手册V2.0》P8”。 效果:客服人工干预减少40%,回答准确率提升30%+。
2. 场景2:医疗问答助手(专业领域必备)
传统医疗模型的坑:通用模型不懂专业医学知识,可能给“新冠疫苗导致自闭症”这种错误建议,出问题要担法律责任。 RAG方案:
- 检索库接入权威医学资源(PubMed论文、《临床用药指南》、卫健委公告);
- 用户问“二甲双胍的禁忌症有哪些?”,RAG检索2023版《临床用药指南》第5.3节,生成回答:“根据2023版《临床用药指南》,二甲双胍禁用于:1)严重肾功能不全(eGFR<30);2)急性代谢性酸中毒...来源:《临床用药指南2023》P156”。 效果:回答合规性100%,避免医疗误导风险。
3. 场景3:金融研究报告生成(高效提效)
传统分析师的坑:市场数据天天变(比如某公司刚发财报),分析师要花几小时找数据、整理报告,效率低。 RAG方案:
- 检索库实时同步财报、行业新闻、股价数据;
- 分析师问“XXX公司2024Q1财报怎么样?”,RAG先检索该公司2024Q1财报(净利润同比增15%)、行业对比数据,再生成报告片段:“XXX公司2024Q1净利润5.2亿元,同比增15%,高于行业平均8%,主要因XX业务增长...来源:XXX公司2024Q1财报P10、XX行业分析报告”。 效果:分析师写报告时间从6小时缩短到1小时,更新频率从“每天1次”变成“实时更新”。
小结
RAG的核心不是“高大上的新技术”,而是“用检索补全大模型的短板”——让模型从“凭记忆答题”变成“先翻书再答题”,既解决了知识过时、幻觉问题,又不用花大价钱重训模型。
对咱们开发者来说,入门RAG不用怕:先掌握LangChain的文档加载、向量存储(比如FAISS),再结合今天讲的“检索+生成”逻辑,就能搭一个简单的RAG系统
最后问大家:你所在的行业,有没有“需要RAG来解决的问题”?比如公司内部文档太多,查资料慢?欢迎在评论区聊聊!
